分布式SQL数据库中部分索引的好处
在优锐课的java学习分享中,探讨了分布式SQL数据库中部分索引的优势,并探讨了性能测试,结果等。
如果使用局部索引而不是常规索引,则在可为空的列上(其中只有一小部分行的该列不具有空值),然后可以大大缩短插入,更新和删除的响应时间。 另外,单行选择的响应时间也缩短了一点。 这篇文章解释了什么是部分索引,显示了如何创建部分索引,描述了要求使用部分索引的规范用例,描述了一些简单的性能测试,并显示了结果证明有理由建议使用部分索引。 适当的用例。
1、介绍
有时,业务分析会确定实体类型具有可选属性,该属性在典型情况下仍未设置,需要标识将可选属性设置为某个值的实体出现,并且从不要求 识别未设置的事件。 现在出现了一个典型的例子,一些办公设施在一个很小的地下室里提供有限的自行车存放空间,并为很少有人利用这一点提供了编号的钥匙。 当看门人交错了一把钥匙时,确实需要找出“谁被分配了42号钥匙?”,但是不需要识别不使用自行车存放处的人员。
这样的实体类型将被实现为具有可为空的列以表示可选属性的表。并且该列将需要辅助索引来支持快速执行查询,该查询通过此列的非非空值来标识行。
如果你有一个同时包含“开票”和“未开票”订单的表,则会出现另一种情况(与可选属性的情况稍有不同),其中“未开票”的订单只占总表的一小部分,但通常在OLTP场景中唯一要选择的对象-正是这样以便可以对其进行处理并将其设置为“开票”。使用限制定义了部分索引,以便仅对表的某些行进行索引。在当前情况下,在第一种情况下,限制将指定仅对该列具有不为空值的行建立索引。或者,在第二种情况下,将仅索引“未开票”的行。
这将是有益的,因为部分索引比常规索引要小得多。最重要的是,在插入或删除行时,在典型情况下将避免索引的维护成本。
2、“创建索引”语法
假设我们创建了一个表:
create table t(k int primary key, v int);
(我将在本文中以尾部分号显示所有SQL语句,因为它们将以ysqlsh命令形式显示。)请注意,t.v列是可为空的。
创建常规二级索引:
create index t_v on t(v);
并创建了部分二级索引:
create index t_v on t(v) where v is not null;
where子句限制可以是任何仅提及要索引表中的列的单行表达式。 例如,``其中v不为null且v!= 0''。 就这么简单!
3、性能测试
我用一百万行填充了表t,其中只有百分之十的行的t.v不为空。 这是用PostgreSQL语法编写的SQL,其中%运算符用于表示取模函数。
insert into t(k, v) select a.v, case a.v % 10 when 0 then a.v else null end from (select generate_series(1, 1000000) as v) as a;
测试1:创建索引
首先,我首先在t.v上创建了一个常规索引,对``创建索引''操作进行计时,然后运行计时脚本。 (此脚本实现了测试#2至#4。)然后我删除了索引并在t.v上创建了部分索引,也对该操作进行了计时,并再次运行了计时脚本.
测试2:单键选择
\timing on call select_not_null_rows(100000); \timing off
过程select_not_null_rows()通过运行实现的“ for循环”来模拟OLTP单行选择语句:
for j in 1..num_rows loop select t.k into the_k from t where t.v = the_v; the_v := the_v + sparseness_step; end loop;
当然,没有人会写像这样的真实程序-尤其是因为在没有唯一约束ont.v的情况下,select语句可能会返回多个行! 但是这种幼稚的方法足以用于计时目的。 sparseness_step的值设置为10,反映了我的选择,表示为:
case a.v % 10
在上面显示的插入语句中,我曾用来填充表t。在程序运行时首次遇到该问题时,该程序反复发出的选择语句是在幕后准备的,因此SQL执行确实遵循最佳的准备- 执行范例
测试3:单行插入
\timing on call insert_rows(100000); \timing off
过程insert_rows()通过运行以下实现的“ for循环”来模拟OLTP单行插入语句:
for j in 1..num_rows loop insert into t(k, v) values(1000000 + j, null); commit; end loop;
没有人会在实际程序中提交每一行。 但这是模拟单行OLTP的设备。 在这里,SQL执行也遵循最佳的执行准备范式。
测试4:批量删除
\timing on delete from t where k > 1000000; \timing off
我在这里没有使用prepare-execute范例,因为SQL编译和计划所需的时间只是删除十万行所需时间的一小部分。
4、测试环境
我在两个环境中记录了时间。
- 首先,我使用本地MacBook运行单节点YugabyteDB群集(版本2.0.1),复制因子(RF)为1。 ysqlsh客户端在同一本地计算机上运行。
- 然后,我使用托管在AWS上的,RF = 3的实际三节点集群来运行它们。 我将所有三个节点部署在相同的``us-west-2''(俄勒冈)可用性区域中。 节点的类型为“ c5.large”,每个节点都有足够的存储空间来满足我的测试要求。 我在同一可用区中的另一个节点上运行了ysqlsh客户端。
5、结果
我记录了在两种测试条件(常规索引和部分索引)和两种测试环境(“本地”和“云”)下上述测试的经过时间。对于每个测量对,常规索引时间都大于部分索引时间。可以预料,“云”环境中的时间绝对值大于“本地”环境中的时间绝对值。请注意,使用Raft共识算法和分布式事务,在RF = 3的三节点群集上的SQL操作预期比单个节点要慢,RF = 1且没有节点间通信且代码路径较短。如此有弹性和可扩展的系统有很多有据可查的好处,而这些好处可能会超过成本。
我通过将它们表示为速比来标准化结果。例如,如果使用常规索引进行的测试花费60秒,而使用部分索引进行的测试花费20秒,则部分索引速度是常规索引速度的3倍。在我的测量精度范围内,两个测试环境中的速度比是相同的。
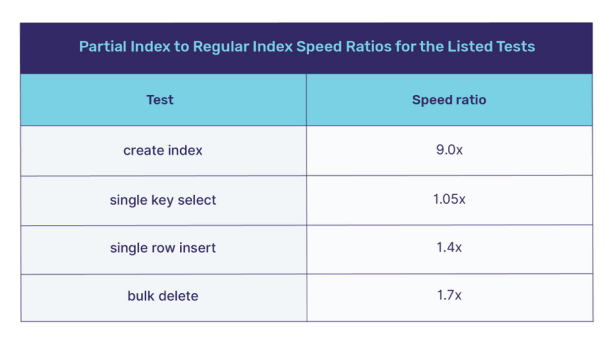
列出测试的部分索引与常规索引速度比
当然,你的结果可能会有所不同。 索引列中的非零值稀疏密度将使速度比更大,而稀疏密度较小将使它们变得更小。
6、结论
这篇文章展示了如何在适当的用例中使用部分索引,可以减少二级索引维护的成本,从而加快有关表的插入,更新和删除操作。 通过使用部分索引来减少二级索引维护操作的数量在分布式SQL数据库(例如YugabyteDB)中特别有利。 这是因为在索引维护期间,看似仅插入,更新或删除单个行的事务会自动成为涉及主行和辅助索引行的分布式事务。
当主行和辅助索引行存在于群集的潜在两个不同节点上的两个不同分片上时,这种分布式事务可以是多分片事务。 可以想象,多分片事务必然比单分片事务昂贵。
文章写道这里,如有不足之处,欢迎补充评论。
抽丝剥茧,细说架构那些事。
分布式SQL数据库中部分索引的好处的更多相关文章
- SQL Server中的索引
1 SQL Server中的索引 索引是与表或视图关联的磁盘上结构,可以加快从表或视图中检索行的速度.索引包含由表或视图中的一列或多列生成的键.这些键存储在一个结构(B 树)中,使 SQL Serve ...
- 转载: SQL Server中的索引
http://www.blogjava.net/wangdetian168/archive/2011/03/07/347192.html 1 SQL Server中的索引 索引是与表或视图关联的磁盘上 ...
- 保姆级教程!手把手教你使用Longhorn管理云原生分布式SQL数据库!
作者简介 Jimmy Guerrero,在开发者关系团队和开源社区拥有20多年的经验.他目前领导YugabyteDB的社区和市场团队. 本文来自Rancher Labs Longhorn是Kubern ...
- Android - 数据存储 -在SQL数据库中保存数据
对于重复的或结构化的数据,保存到数据库中是很好的选择,比如联系人信息.这里假设你对SQL数据库大体上了解然后帮助你学习Android上的SQLite数据库.在Android数据库上需要用到的API可以 ...
- sql server中的索引详情
什么是索引 拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K .为了加快查找的速度,汉语字(词)典一般都有按拼音. ...
- SQL数据库中临时表、临时变量和WITH AS关键词创建“临时表”的区别
原文链接:https://www.cnblogs.com/zhaowei303/articles/4204805.html SQL数据库中数据处理时,有时候需要建立临时表,将查询后的结果集放到临时表中 ...
- 数据库中的索引Index
索引就像一本书的目录,而书中的索引是对一个词语的列表,其中注明了包含各个词的页码.数据库中的索引 是某一个表中一列或者若干列值的集合和相应的只想表中物理标识这些值的数据页的逻辑指针清单. 索引的作用: ...
- Android学习笔记——保存数据到SQL数据库中(Saving Data in SQL Databases)
知识点: 1.使用SQL Helper创建数据库 2.数据的增删查改(PRDU:Put.Read.Delete.Update) 背景知识: 上篇文章学习了保存文件,今天学习的是保存数据到SQL数据库中 ...
- SQL语句:把Excel文件中数据导入SQL数据库中的方法
1.从Excel文件中,导入数据到SQL数据库情况一.如果接受数据导入的表不存在 select * into jd$ from OPENROWSET('MICROSOFT.JET.OLEDB.4.0' ...
随机推荐
- Dotnetcore安装nuget包时不能使用content中的文件
问题:用NUGET打包了一个asp.netcore的项目,试图安装到另一个asp.netcore项目中,除了自动添加引用外,还希望自动释放一些文件以供修改.这些操作以前在netframe中是正常的,脚 ...
- 6 Ubuntu软件安装
6 软件安装¶ 6.1 通过apt 安装/卸载软件¶ apt是Advanced Packaging Tool,是Linux下的一款安装包管理工具 可以在终端中方便的安装/卸载/更新软件包 # 1. ...
- 31(1).密度聚类---DBSCAN算法
密度聚类density-based clustering假设聚类结构能够通过样本分布的紧密程度确定. 密度聚类算法从样本的密度的角度来考察样本之间的可连接性,并基于可连接样本的不断扩张聚类簇,从而获得 ...
- Python导入运行的当前模块报错
引言 今天遇到了一个奇怪的现象,简单举个栗子: 文件结构如下:
- pip安装插件报错。
报错: Cannot unpack file C:\Windows\TEMP\pip-unpack-4mbfczpj\simple (downloaded from C:\Windows\TEMP\p ...
- 织女星开发板启动模式修改——从ARM M4核启动
前言 刚开始玩织女星开发板的时候,想先从熟悉的ARM核入手,连上Jlink,打开MDK版本的Demo程序,编译OK,却检测不到芯片,仔细看了一下文档,原来RV32M1芯片默认从RISC-V核启动,如果 ...
- mysql给字段取别名无法被jdbc解析的解决办法
项目上用的Spring JDBC,是通过ResultSetMetaData接口来调用具体数据库的JDBC实现类来获取数据库返回结果集的. 在项目开发中,发现在MySQL中使用的别名没有办法被正常解析, ...
- Hive安装、配置和使用
Hive概述 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. Hive本质是:将HQL转化成MapReduce程序. Hive处理的数据存储 ...
- MacOS~jenkins里解决docker执行权限问题
一 全局配置项设置 需要添加全局变量项,例如名称docker,路径/usr/local 添加一个jenkinsfile文件,用于运行docker命令 pipeline { agent any tool ...
- [browser srceen]、很多未知望大神告知、简单写了个拖拽
未知作用的有.如果也有像我1样好奇的小伙伴了解了麻烦告知 // console.log(window.screen.availWidth);//未知效果 // console.log(window.s ...