spring-boot-starter-quartz集群实践
【**前情提要**】由于项目需要,需要一个定时任务集群,故此有了这个spring-boot-starter-quartz集群的实践。springboot的版本为:2.1.6.RELEASE;quartz的版本为:2.3.1.假如这里一共有两个定时任务的节点,它们的代码完全一样。
---
# 壹.jar包依赖
~~~pom
1.8
org.springframework.boot
spring-boot-starter
org.springframework.boot
spring-boot-starter-quartz
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-jdbc
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
~~~
这里选择将定时任务的数据入库,避免数据直接存在内存中,因应用重启造成的数据丢失和做集群控制。
# 贰、项目配置
~~~yaml
spring:
server:
port: 8080
servlet:
context-path: /lovin
datasource:
url: jdbc:mysql://127.0.0.1:3306/training?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
quartz:
job-store-type: jdbc #数据库方式
jdbc:
initialize-schema: never #不初始化表结构
properties:
org:
quartz:
scheduler:
instanceId: AUTO #默认主机名和时间戳生成实例ID,可以是任何字符串,但对于所有调度程序来说,必须是唯一的 对应qrtz_scheduler_state INSTANCE_NAME字段
#instanceName: clusteredScheduler #quartzScheduler
jobStore:
class: org.quartz.impl.jdbcjobstore.JobStoreTX #持久化配置
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate #我们仅为数据库制作了特定于数据库的代理
useProperties: false #以指示JDBCJobStore将JobDataMaps中的所有值都作为字符串,因此可以作为名称 - 值对存储而不是在BLOB列中以其序列化形式存储更多复杂的对象。从长远来看,这是更安全的,因为您避免了将非String类序列化为BLOB的类版本问题。
tablePrefix: qrtz_ #数据库表前缀
misfireThreshold: 60000 #在被认为“失火”之前,调度程序将“容忍”一个Triggers将其下一个启动时间通过的毫秒数。默认值(如果您在配置中未输入此属性)为60000(60秒)。
clusterCheckinInterval: 5000 #设置此实例“检入”*与群集的其他实例的频率(以毫秒为单位)。影响检测失败实例的速度。
isClustered: true #打开群集功能
threadPool: #连接池
class: org.quartz.simpl.SimpleThreadPool
threadCount: 10
threadPriority: 5
threadsInheritContextClassLoaderOfInitializingThread: true
~~~
**这里需要注意的是两个节点的端口号应该不一致,避免冲突**
# 叁、实现一个Job
~~~java
@Slf4j
public class Job extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {
// 获取参数
JobDataMap jobDataMap = jobExecutionContext.getJobDetail().getJobDataMap();
// 业务逻辑 ...
log.info("------springbootquartzonejob执行"+jobDataMap.get("name").toString()+"###############"+jobExecutionContext.getTrigger());
}
~~~
**其中的日志输出是为了便于观察任务执行情况**
# 肆、封装定时任务操作
~~~java
@Service
public class QuartzService {
@Autowired
private Scheduler scheduler;
@PostConstruct
public void startScheduler() {
try {
scheduler.start();
} catch (SchedulerException e) {
e.printStackTrace();
}
}
/**
* 增加一个job
*
* @param jobClass
* 任务实现类
* @param jobName
* 任务名称
* @param jobGroupName
* 任务组名
* @param jobTime
* 时间表达式 (这是每隔多少秒为一次任务)
* @param jobTimes
* 运行的次数 ( jobClass, String jobName, String jobGroupName, int jobTime,
int jobTimes, Map jobData) {
try {
// 任务名称和组构成任务key
JobDetail jobDetail = JobBuilder.newJob(jobClass).withIdentity(jobName, jobGroupName)
.build();
// 设置job参数
if(jobData!= null && jobData.size()>0){
jobDetail.getJobDataMap().putAll(jobData);
}
// 使用simpleTrigger规则
Trigger trigger = null;
if (jobTimes jobClass, String jobName, String jobGroupName, String jobTime, Map jobData) {
try {
// 创建jobDetail实例,绑定Job实现类
// 指明job的名称,所在组的名称,以及绑定job类
// 任务名称和组构成任务key
JobDetail jobDetail = JobBuilder.newJob(jobClass).withIdentity(jobName, jobGroupName)
.build();
// 设置job参数
if(jobData!= null && jobData.size()>0){
jobDetail.getJobDataMap().putAll(jobData);
}
// 定义调度触发规则
// 使用cornTrigger规则
// 触发器key
Trigger trigger = TriggerBuilder.newTrigger().withIdentity(jobName, jobGroupName)
.startAt(DateBuilder.futureDate(1, IntervalUnit.SECOND))
.withSchedule(CronScheduleBuilder.cronSchedule(jobTime)).startNow().build();
// 把作业和触发器注册到任务调度中
scheduler.scheduleJob(jobDetail, trigger);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 修改 一个job的 时间表达式
*
* @param jobName
* @param jobGroupName
* @param jobTime
*/
public void updateJob(String jobName, String jobGroupName, String jobTime) {
try {
TriggerKey triggerKey = TriggerKey.triggerKey(jobName, jobGroupName);
CronTrigger trigger = (CronTrigger) scheduler.getTrigger(triggerKey);
trigger = trigger.getTriggerBuilder().withIdentity(triggerKey)
.withSchedule(CronScheduleBuilder.cronSchedule(jobTime)).build();
// 重启触发器
scheduler.rescheduleJob(triggerKey, trigger);
} catch (SchedulerException e) {
e.printStackTrace();
}
}
/**
* 删除任务一个job
*
* @param jobName
* 任务名称
* @param jobGroupName
* 任务组名
*/
public void deleteJob(String jobName, String jobGroupName) {
try {
scheduler.deleteJob(new JobKey(jobName, jobGroupName));
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 暂停一个job
*
* @param jobName
* @param jobGroupName
*/
public void pauseJob(String jobName, String jobGroupName) {
try {
JobKey jobKey = JobKey.jobKey(jobName, jobGroupName);
scheduler.pauseJob(jobKey);
} catch (SchedulerException e) {
e.printStackTrace();
}
}
/**
* 恢复一个job
*
* @param jobName
* @param jobGroupName
*/
public void resumeJob(String jobName, String jobGroupName) {
try {
JobKey jobKey = JobKey.jobKey(jobName, jobGroupName);
scheduler.resumeJob(jobKey);
} catch (SchedulerException e) {
e.printStackTrace();
}
}
/**
* 立即执行一个job
*
* @param jobName
* @param jobGroupName
*/
public void runAJobNow(String jobName, String jobGroupName) {
try {
JobKey jobKey = JobKey.jobKey(jobName, jobGroupName);
scheduler.triggerJob(jobKey);
} catch (SchedulerException e) {
e.printStackTrace();
}
}
/**
* 获取所有计划中的任务列表
*
* @return
*/
public List> queryAllJob() {
List> jobList = null;
try {
GroupMatcher matcher = GroupMatcher.anyJobGroup();
Set jobKeys = scheduler.getJobKeys(matcher);
jobList = new ArrayList>();
for (JobKey jobKey : jobKeys) {
List triggers = scheduler.getTriggersOfJob(jobKey);
for (Trigger trigger : triggers) {
Map map = new HashMap();
map.put("jobName", jobKey.getName());
map.put("jobGroupName", jobKey.getGroup());
map.put("description", "触发器:" + trigger.getKey());
Trigger.TriggerState triggerState = scheduler.getTriggerState(trigger.getKey());
map.put("jobStatus", triggerState.name());
if (trigger instanceof CronTrigger) {
CronTrigger cronTrigger = (CronTrigger) trigger;
String cronExpression = cronTrigger.getCronExpression();
map.put("jobTime", cronExpression);
}
jobList.add(map);
}
}
} catch (SchedulerException e) {
e.printStackTrace();
}
return jobList;
}
/**
* 获取所有正在运行的job
*
* @return
*/
public List> queryRunJob() {
List> jobList = null;
try {
List executingJobs = scheduler.getCurrentlyExecutingJobs();
jobList = new ArrayList>(executingJobs.size());
for (JobExecutionContext executingJob : executingJobs) {
Map map = new HashMap();
JobDetail jobDetail = executingJob.getJobDetail();
JobKey jobKey = jobDetail.getKey();
Trigger trigger = executingJob.getTrigger();
map.put("jobName", jobKey.getName());
map.put("jobGroupName", jobKey.getGroup());
map.put("description", "触发器:" + trigger.getKey());
Trigger.TriggerState triggerState = scheduler.getTriggerState(trigger.getKey());
map.put("jobStatus", triggerState.name());
if (trigger instanceof CronTrigger) {
CronTrigger cronTrigger = (CronTrigger) trigger;
String cronExpression = cronTrigger.getCronExpression();
map.put("jobTime", cronExpression);
}
jobList.add(map);
}
} catch (SchedulerException e) {
e.printStackTrace();
}
return jobList;
}
~~~
# 陆、初始化任务
这里不准备给用户用web界面来配置定时任务,故此采用**CommandLineRunner**来子啊应用初始化的时候来初始化任务。只需要实现CommandLineRunner的run()方法即可。
~~~java
@Override
public void run(String... args) throws Exception {
HashMap map = new HashMap();
map.put("name",1);
quartzService.deleteJob("job", "test");
quartzService.addJob(Job.class, "job", "test", "0 * * * * ?", map);
map.put("name",2);
quartzService.deleteJob("job2", "test");
quartzService.addJob(Job.class, "job2", "test", "10 * * * * ?", map);
map.put("name",3);
quartzService.deleteJob("job3", "test2");
quartzService.addJob(Job.class, "job3", "test2", "15 * * * * ?", map);
}
~~~
# 柒、测试验证
分别夏侯启动两个应用,然后观察任务执行,以及在运行过程中杀死某个服务,来观察定时任务的执行。
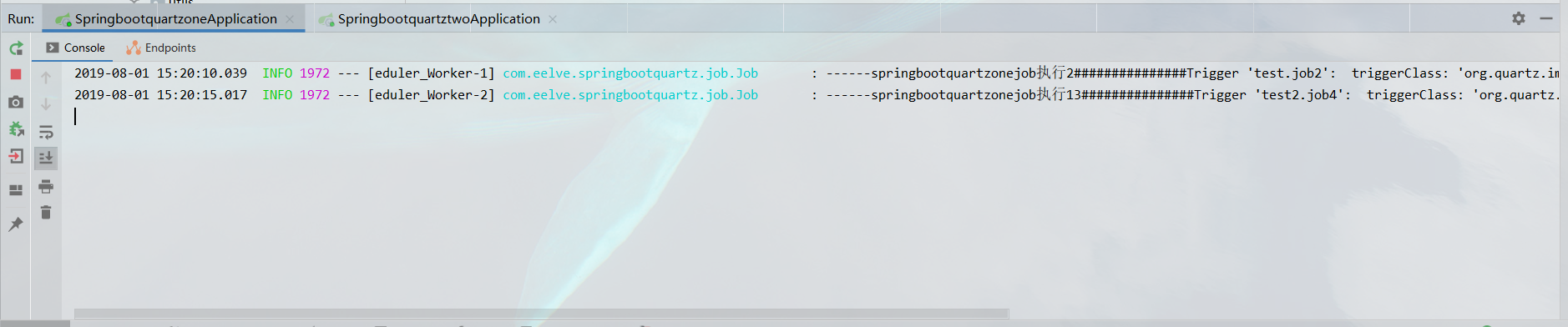
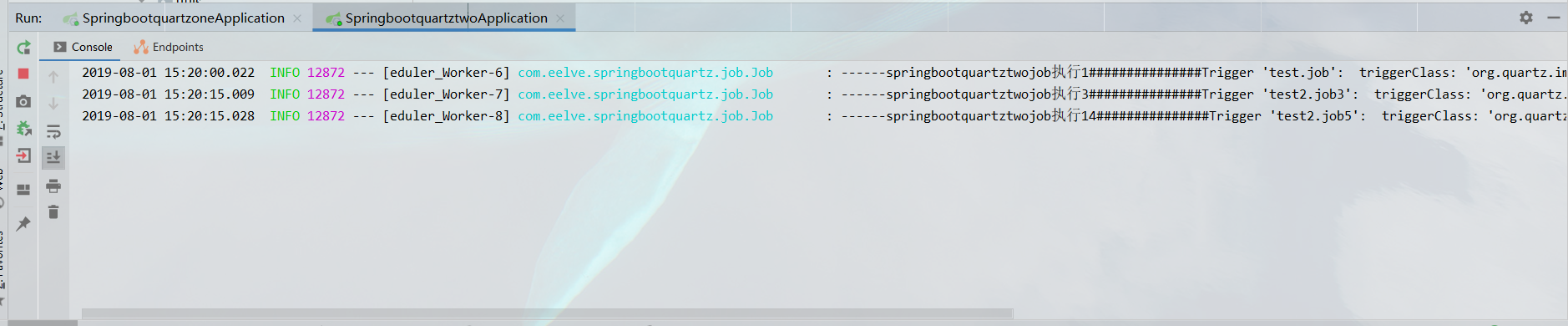
【**写在后面的话**】下面给出的是所需要脚本的连接地址:[脚本下载地址](http://www.quartz-scheduler.org/downloads/),另外这边又一个自己实现的[demo](https://github.com/eelve/springbootquartzs.git)
spring-boot-starter-quartz集群实践的更多相关文章
- spring boot 整合 quartz 集群环境 实现 动态定时任务配置【原】
最近做了一个spring boot 整合 quartz 实现 动态定时任务配置,在集群环境下运行的 任务.能够对定时任务,动态的进行增删改查,界面效果图如下: 1. 在项目中引入jar 2. 将需要 ...
- Spring Boot MyBatis 数据库集群访问实现
Spring Boot MyBatis 数据库集群访问实现 本示例主要介绍了Spring Boot程序方式实现数据库集群访问,读库轮询方式实现负载均衡.阅读本示例前,建议你有AOP编程基础.mybat ...
- (4) Spring中定时任务Quartz集群配置学习
原 来配置的Quartz是通过spring配置文件生效的,发现在非集群式的服务器上运行良好,但是将工程部署到水平集群服务器上去后改定时功能不能正常运 行,没有任何错误日志,于是从jar包.JDK版本. ...
- Spring Boot集成Redis集群(Cluster模式)
目录 集成jedis 引入依赖 配置绑定 注册 获取redis客户端 使用 验证 集成spring-data-redis 引入依赖 配置绑定 注册 获取redis客户端 使用 验证 异常处理 同样的, ...
- Spring boot连接MongoDB集群
主要问题是:MongoDB集群分为复制集(replicaSet)与分片集(shardingSet),那么如何去连接这两种集群: 参考官方文档,我使用了最通用的方法:通过构造connection str ...
- spring boot + quartz 集群
spring boot bean配置: @Configuration public class QuartzConfig { @Value("${quartz.scheduler.insta ...
- Spring+quartz集群配置,Spring定时任务集群,quartz定时任务集群
Spring+quartz集群配置,Spring定时任务集群,quartz定时任务集群 >>>>>>>>>>>>>> ...
- Spring+Quartz集群环境下定时调度的解决方案
集群环境可能出现的问题 在上一篇博客我们介绍了如何在自己的项目中从无到有的添加了Quartz定时调度引擎,其实就是一个Quartz 和Spring的整合过程,很容易实现,但是我们现在企业中项目通常都是 ...
- Spring+Quartz 集群
这几天给Spring+Quartz的集群折腾得死去活来,google了无数页总算搞定,记下一些要点备以后使用. 单独的Quartz集群在http://unmi.blogjava.net/有Unmi翻译 ...
- Spring集成quartz集群配置总结
1.spring-quartz.xml <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE be ...
随机推荐
- Centos7.4 的yum源库配置。
http://mirrors.163.com/.help/centos.html https://www.cnblogs.com/mchina/archive/2013/01/04/2842275.h ...
- weex起步
weex文档地址: http://weex-project.io/cn/guide/index.html weex的文档过于简单,加上js语法 & android & ios本身也有很 ...
- 通过自研数据库画像工具支持“去O”评估
“去O”,是近些年来一直很火的一个话题,随之也产生了各种疑惑,包括现有数据库评估.技术选型等.去O是项系统工程,需要做好充分的评估.本文通过自研工具,生成数据库画像,为去O评估提供一手数据,希望给大家 ...
- Spark学习之第一个程序 WordCount
WordCount程序 求下列文件中使用空格分割之后,单词出现的个数 input.txt java scala python hello world java pyfysf upuptop wintp ...
- C4.5和ID3的差别
C4.5和ID3的差别 决策树分为两大类:分类树和回归树,前者用于分类标签值,后者用于预测连续值,常用算法有ID3.C4.5.CART等. 信息熵 信息量: 信息熵: 信息增益 当计算出各个特征属 ...
- [leetcode] 8. String to Integer (atoi) (Medium)
实现字符串转整形数字 遵循几个规则: 1. 函数首先丢弃尽可能多的空格字符,直到找到第一个非空格字符. 2. 此时取初始加号或减号. 3. 后面跟着尽可能多的数字,并将它们解释为一个数值. 4. 字符 ...
- [PTA] L3-015 球队“食物链”
原题链接 思路: 如果有环,则起点一定为"1".如果没有可以胜过"1"的,则无环. 根据W,L来建立图,用dfs从1节点遍历+回溯. 剪枝:dfs到某个子序列时 ...
- tomcat用做图片服务器
最近做了个小网站,就是用tinyce富文本编辑器,https://www.511easy.com/ 保持字体排版和图片 发现博客园的图片,一天之后就无法显示 就想着自己做一个图片服务器,上传图片到指定 ...
- Python基础之str常用方法、for循环
初学python,有些地方可能还不够明白,希望各位看官发现我的错误后留言指正! 一.字符串的索引与切片 注:字符串的第一位的索引值是0 1.索引案例 s = 'abcd' s1 = s[0] prin ...
- excel表数据生成定长txt数据
项目作业中需要造数据,从txt文件中获取定长数据,直接从txt中修改,会显得十分麻烦,于是便利用excel自带的vba写了一个小工具.效果如下: A1表示字段名,A2表示长度,A3是数据,也可以增加字 ...