python进程池与线程池
为什么会进行池化?
一切都是为了效率,每次开启进程都会分配一个属于这个进程独立的内存空间,开启进程过多会占用大量内存,系统调度也会很慢,我们不能无限的开启进程。
进程池原来大概如下图
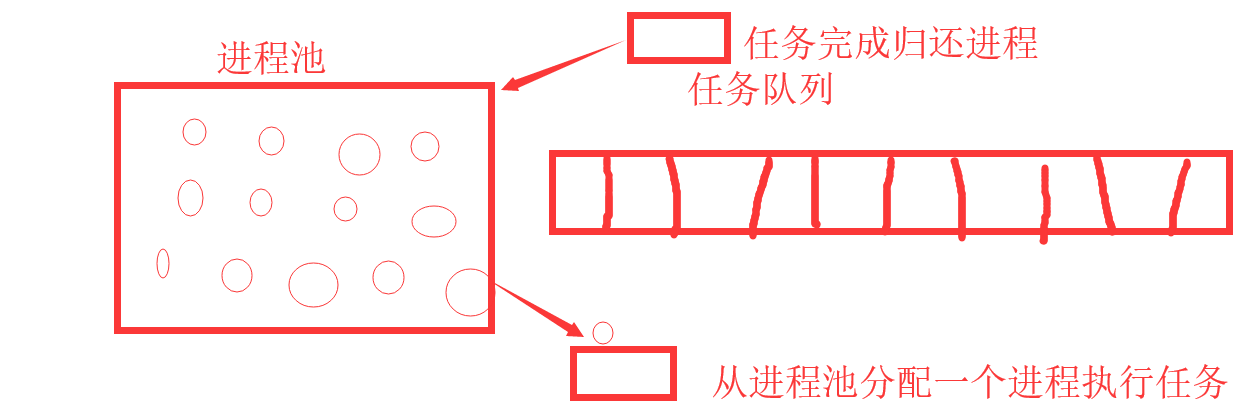
假设有100个任务 ,如果不使用进程池就需要创建100个进程。但是使用进程池假设进程池里有25个进程,那么100个任务 每个都从进程池分配一个进程执行,如果进程池为空就会等待别的任务完成归还进程再分配进程执行任务。
更高级的进程池,会根据任务数量自动收缩和扩充进程池大小,不过python暂时不具备。我猜的原因是因为python效率过低自动化进程池收缩和分配进程会严重影响效率还不如固定大小的进程池效率高。不过可以可以写一个C语言的自动化进程池再联合编程为python模块=。=最近已经在研究C语言希望能搞一搞。
python池化模块
python3.2版本发布的concurrent.futures 模块 ,可以用来生成进程池和线程池。 也可以直接使用multiprocessing.Pool 这里不多介绍了。建议使用前一个毕竟都是标准库模块前一个功能更强。
ProcessPoolExecutor进程池
ThreadPoolExecutor线程池 基本方法:
submit(fn,*args,**kwargs) 异步提交任务 需要使用for循环提交多个任务 map(func,*iterables,timeout=None,chunksize=1) 取代for循环submit的操作 shutdown(wait=True) 相当于进程池pool.close()+pool.join() 操作,wait=True等待池内所有任务执行完毕回收完资源后才继续否则立即返回。但是不管wait为何值程序都会等等所有任务执行完毕。
submit和map必须在shutdown之前 result(timeout=None)取回结果 add_done_callback(fn) 回调函数
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor def fun1(i):
print(i) if __name__ == "__main__":
p = ProcessPoolExecutor(max_workers=) #进程池 for i in range():
p.submit(fun1,i) p.shutdown() #回收完所有进程才向下执行 t = ThreadPoolExecutor(max_workers=) #线程池
for item in range():
t.submit(fun1,item)
print("主进程结束")
拿到返回值
from concurrent.futures import ProcessPoolExecutor def fun1(i):
return i if __name__ == "__main__":
p = ProcessPoolExecutor(max_workers=5) #进程池 p_lst = []
for i in range(100):
pn = p.submit(fun1,i)
p_lst.append(pn)
p.shutdown() #回收完所有进程才向下执行 result_lst = [task.result() for task in p_lst]
print(result_lst) #返回值列表
使用回调函数
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor def fun1(i):
return i def call_back(m): #回调函数传入的参数是任务的返回值
print("结果是%d"%m.result()) #处理任务的返回值 if __name__ == "__main__":
p = ProcessPoolExecutor(max_workers=5) #进程池 p_lst = [] for i in range(100):
pn = p.submit(fun1,i).add_done_callback(call_back) #添加回调函数
p_lst.append(pn) p.shutdown() #回收完所有进程才向下执行 print("主进程结束")
使用上下文管理器
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor def fun1(i):
print(i) if __name__ == "__main__":
with ProcessPoolExecutor(max_workers=5) as p: #进程池
for i in range(10):
p.submit(fun1,i) with ThreadPoolExecutor(max_workers=5) as t: #线程池
for i in range(10):
t.submit(fun1, i)
使用map方法处理任务
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor def fun1(i):
print(i)
return i*i if __name__ == "__main__":
with ProcessPoolExecutor(max_workers=5) as p: #进程池
results = p.map(fun1,range(10)) #map的可迭代对象参数的每个值都传入函数执行 for result in results:
print(result) #拿到map的返回值
python进程池与线程池的更多相关文章
- python系列之 - 并发编程(进程池,线程池,协程)
需要注意一下不能无限的开进程,不能无限的开线程最常用的就是开进程池,开线程池.其中回调函数非常重要回调函数其实可以作为一种编程思想,谁好了谁就去掉 只要你用并发,就会有锁的问题,但是你不能一直去自己加 ...
- python并发编程之进程池,线程池,协程
需要注意一下不能无限的开进程,不能无限的开线程最常用的就是开进程池,开线程池.其中回调函数非常重要回调函数其实可以作为一种编程思想,谁好了谁就去掉 只要你用并发,就会有锁的问题,但是你不能一直去自己加 ...
- python自带的进程池及线程池
进程池 """ python自带的进程池 """ from multiprocessing import Pool from time im ...
- Python并发编程之线程池/进程池--concurrent.futures模块
一.关于concurrent.futures模块 Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码,但是当项目达到一定的规模,频繁创建/ ...
- python并发编程之进程池,线程池concurrent.futures
进程池与线程池 在刚开始学多进程或多线程时,我们迫不及待地基于多进程或多线程实现并发的套接字通信,然而这种实现方式的致命缺陷是:服务的开启的进程数或线程数都会随着并发的客户端数目地增多而增多, 这会对 ...
- 《转载》Python并发编程之线程池/进程池--concurrent.futures模块
本文转载自Python并发编程之线程池/进程池--concurrent.futures模块 一.关于concurrent.futures模块 Python标准库为我们提供了threading和mult ...
- python之进程池与线程池
一.进程池与线程池介绍 池子使用来限制并发的任务数目,限制我们的计算机在一个自己可承受的范围内去并发地执行任务 当并发的任务数远远超过了计算机的承受能力时,即无法一次性开启过多的进程数或线程数时就应该 ...
- python自带的线程池和进程池
#python自带的线程池 from multiprocessing.pool import ThreadPool #注意ThreadPool不在threading模块下 from multiproc ...
- Python并发编程之进程池与线程池
一.进程池与线程池 python标准模块concurrent.futures(并发未来) 1.concurrent.futures模块是用来创建并行的任务,提供了更高级别的接口,为了异步执行调用 2. ...
- Python 37 进程池与线程池 、 协程
一:进程池与线程池 提交任务的两种方式: 1.同步调用:提交完一个任务之后,就在原地等待,等任务完完整整地运行完毕拿到结果后,再执行下一行代码,会导致任务是串行执行 2.异步调用:提交完一个任务之后, ...
随机推荐
- IDEA+docker,进行远程漏洞调试(weblogic)
用于学习java漏洞debug. 以weblogic为例. cve-2017-10271 weblogic:10.3.6 环境搭建 拿docker为例 https://github.com/vulhu ...
- C/C++语言误区void main( )
很多人甚至市面上的一些书籍,都使用了void main( ) ,其实这是错误的.C/C++ 中从来没有定义过void main( ) .C++ 之父 Bjarne Stroustrup 在他的主页上的 ...
- Java基础(三十三)JDBC(3)操作数据库
一.添加数据 在SQL语句中,一条INSERT语句只能添加一条记录,因此分为几种情况进行添加数据操作. 1.添加一条记录 (1)如果只需要添加一条记录,通常情况下通过Statament实例完成. tr ...
- Java基础(三十二)JDBC(2)连接数据库
一.连接数据库的过程 连接数据库的过程:加载数据库驱动程序,不过只需在第一次访问数据库时加载一次,然后在每次访问数据库时创建一个Connection实例,然后执行操作数据库的SQL语句,并返回执行结果 ...
- Phpstudy隐藏后门
Phpstudy隐藏后门 1.事件背景 Phpstudy软件是国内的一款免费的PHP调试环境的程序集成包,通过集成Apache.PHP.MySQL.phpMyAdmin.ZendOptimizer多款 ...
- Angular开发规范
目录 一. 前言 1.1. 规范目的 1.2. 局限性 二. 文件规范 2.1. 文件结构约定 2.2. 单一职责原则 ...
- Apache+Tomcat负载均衡
参考:http://www.cnblogs.com/fly_binbin/p/3881207.html 反向代理负载均衡 (Apache2+Tomcat7/8) 使用代理服务器可以将请求转发给内部的 ...
- map和set的使用及top K问题
1.map和set的应用和比较 map和set都是关联式容器,底层容器都是红黑树. map以键值对的形式进行存储,方便进行查找,关键词起到索引的作用,值则表示与索引相关联的数据,以红黑树的结构实现,插 ...
- ElasticSearch(二):文档的基本CRUD与批量操作
ElasticSearch(二):文档的基本CRUD与批量操作 学习课程链接<Elasticsearch核心技术与实战> Create 文档 支持自动生成文档_id和指定文档_id两种方式 ...
- NuGet Package Explorer使用教程下载
1.下载NuGet Package Explorer http://www.pc0359.cn/downinfo/91514.html 2.双击NuGet Package Explorer出现启动界面 ...