深入理解跳表在Redis中的应用
本文首发于:深入理解跳表在Redis中的应用
微信公众号:后端技术指南针
持续输出干货 欢迎关注
前面写了一篇关于跳表基本原理和特性的文章,本次继续介绍跳表的概率平衡和工程实现,
跳表在Redis、LevelDB、ES中都有应用,
本文以Redis为工程蓝本,分析跳表在Redis中的工程实现。
通过本文你将了解到以下内容:
- Redis基本的数据类型和底层数据结构
- Redis的有序集合的实现方法
- Redis的跳表实现细节
1.Redis的数据结构
Redis对外共有约五种类型的对象:
- 字符串(String)
- 列表(List)
- 哈希(Hash)
- 集合(Set)
- 有序集合(SortedSet)
redis源码文件src/server.h中对于5种结构的定义:
/* The actual Redis Object */ #define OBJ_STRING 0 /* String object. */ #define OBJ_LIST 1 /* List object. */ #define OBJ_SET 2 /* Set object. */ #define OBJ_ZSET 3 /* Sorted set object. */ #define OBJ_HASH 4 /* Hash object. */
Redis对象由redisObject结构体表示,从src/server.h可以看到该结构的定义如下:
typedef struct redisObject {
unsigned type:;
unsigned encoding:;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;
redisObject明确了对象类型、对象编码方式、过期设置、引用计数、内存指针等,从而完整表示一个key-value键值对。
由于Redis是基于内存的,Antirez在实现这5种数据类型时在底层创建了多种数据结构,在对象底层选择采用哪种结构来实现,
需要根据对象大小以及单个元素大小来进行确定,从而提高空间使用率和效率。
如图展示了Redis对外使用的数据类型和底层的数据结构:
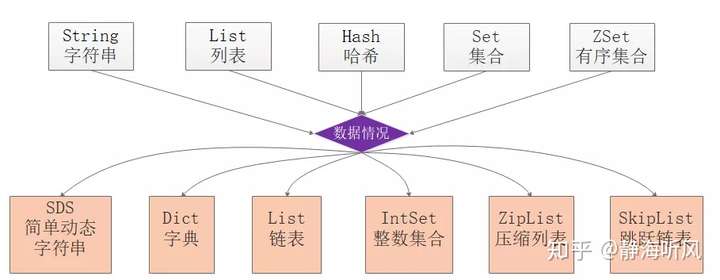
有序集合对象的编码可以是ziplist或者skiplist,在元素小于128并且元素长度小于64Byte时才会选择压缩列表实现,一般使用skiplist跳表实现。
2.Redis的ZSet
ZSet结构同时包含一个字典和一个跳跃表,跳跃表按score从小到大保存所有集合元素。
字典保存着从member到score的映射。这两种结构通过指针共享相同元素的member和score,不会浪费额外内存。
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
ZSet中的字典和跳表布局:
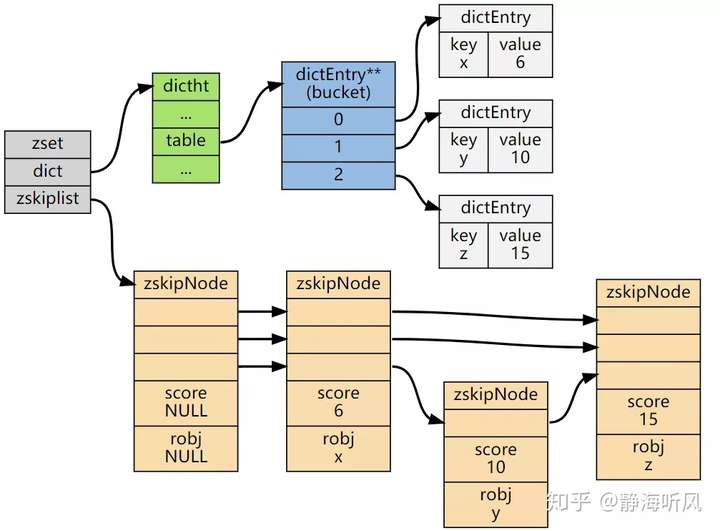
注:图片源自网络
3.ZSet中跳表的实现细节
- 随机层数的实现原理
跳表是一个概率型的数据结构,元素的插入层数是随机指定的。Willam Pugh在论文中描述了它的计算过程如下:
- 指定节点最大层数 MaxLevel,指定概率 p, 默认层数 lvl 为1
- 生成一个0~1的随机数r,若r<p,且lvl<MaxLevel ,则lvl ++
- 重复第 2 步,直至生成的r >p 为止,此时的 lvl 就是要插入的层数。
论文中生成随机层数的伪码:
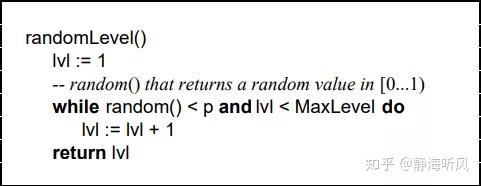
论文中关于随机层数的伪码
在Redis中对跳表的实现基本上也是遵循这个思想的,只不过有微小差异,
看下Redis关于跳表层数的随机源码src/z_set.c:
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void) {
;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += ;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
其中两个宏的定义在redis.h中:
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^32 elements */ #define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
可以看到while中的:
(random()&0xFFFF) < (ZSKIPLIST_P*0xFFFF)
第一眼看到这个公式,因为涉及位运算有些诧异,需要研究一下Antirez为什么使用位运算来这么写?

最开始的猜测是random()返回的是浮点数[0-1],于是乎在线找了个浮点数转二进制的工具,输入0.25看了下结果:
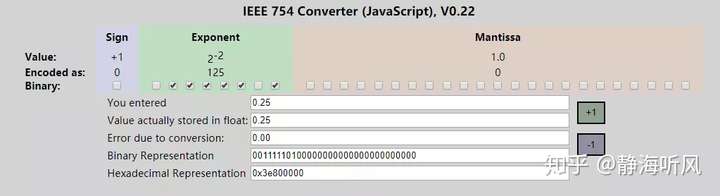
可以看到0.25的32bit转换16进制结果为0x3e800000,如果与0xFFFF做与运算结果是0,好像也符合预期,再试一个0.5:
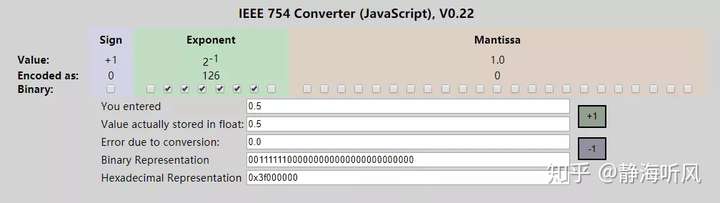
可以看到0.5的32bit转换16进制结果为0x3f000000,如果与0xFFFF做与运算结果还是0,不符合预期。
我印象中C语言的math库好像并没有直接random函数,所以就去Redis源码中找找看,于是下载了3.2版本代码,也并没有找到random()的实现,不过找到了其他几个地方的应用:
- random()在dict.c中的使用:

- random()在cluster.c中的使用:

看到这里的取模运算,后知后觉地发现原以为random()是个[0-1]的浮点数,但是现在看来是uint32才对,这样Antirez的式子就好理解了。
由于ZSKIPLIST_P=0.25,所以相当于0xFFFF右移2位变为0x3FFF,假设random()比较均匀,
在进行0xFFFF与运算之后高16位清零之后,低16位取值就落在0x0000-0xFFFF之间,这样while为真的概率只有1/4,更一般地说为真的概率为1/ZSKIPLIST_P。
对于随机层数的实现并不统一,重要的是随机数的生成,在LevelDB中对跳表层数的生成代码是这样的:
template <typename Key, typename Value>
int SkipList<Key, Value>::randomLevel() {
;
;
)) {
height++;
}
assert(height > );
assert(height <= kMaxLevel);
return height;
}
uint32_t Next( uint32_t& seed) {
seed = seed & 0x7fffffffu;
|| seed == 2147483647L) {
seed = ;
}
static const uint32_t M = 2147483647L;
;
uint64_t product = seed * A;
seed = static_cast<uint32_t>((product >> ) + (product & M));
if (seed > M) {
seed -= M;
}
return seed;
}
可以看到leveldb使用随机数与kBranching取模,如果值为0就增加一层,这样虽然没有使用浮点数,但是也实现了概率平衡。
- 跳表结点的平均层数
我们很容易看出,产生越高的节点层数出现概率越低,无论如何层数总是满足幂次定律越大的数出现的概率越小。
如果某件事的发生频率和它的某个属性成幂关系,那么这个频率就可以称之为符合幂次定律。幂次定律的表现是少数几个事件的发生频率占了整个发生频率的大部分, 而其余的大多数事件只占整个发生频率的一个小部分。幂次定律
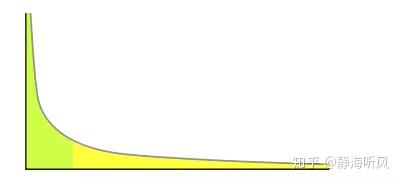
幂次定律应用到跳表的随机层数来说就是大部分的节点层数都是黄色部分,只有少数是绿色部分,并且概率很低。
定量的分析如下:
- 节点层数至少为1,大于1的节点层数满足一个概率分布。
- 节点层数恰好等于1的概率为p^0(1-p)。
- 节点层数恰好等于2的概率为p^1(1-p)。
- 节点层数恰好等于3的概率为p^2(1-p)。
- 节点层数恰好等于4的概率为p^3(1-p)。
- 依次递推节点层数恰好等于K的概率为p^(k-1)(1-p)
因此如果我们要求节点的平均层数,那么也就转换成了求概率分布的期望问题了,灵魂画手大白再次上线:

表中P为概率,V为对应取值,给出了所有取值和概率的可能,因此就可以求这个概率分布的期望了。
方括号里面的式子其实就是高一年级学的等比数列,常用技巧错位相减求和,从中可以看到结点层数的期望值与1-p成反比。
对于Redis而言,当p=0.25时结点层数的期望是1.33。
小结:在Redis源码中有详尽的关于插入和删除调整跳表的过程,本文就不再展开了,代码并不算难懂,都是纯C写的没有那么多炫技的特效,放心大胆读起来。
4.参考资料

- http://note.huangz.me/algorithm/arithmetic/power-law.html
- https://juejin.im/post/5cb885a8f265da03973aa8a1
- https://epaperpress.com/sortsearch/download/skiplist.pdf
- https://www.h-schmidt.net/FloatConverter/IEEE754.html
- http://www.ruanyifeng.com/blog/2010/06/ieee_floating-point_representation.html
- https://cyningsun.github.io/06-18-2018/skiplist.html
5.推荐阅读
白话布隆过滤器BloomFilter
理解缓存系统的三个问题
几种高性能网络模型
二叉树及其四大遍历
理解Redis单线程运行模式
Linux中各种锁及其基本原理
理解Redis持久化
深入理解IO复用之epoll
深入理解跳跃链表[一]
理解堆和堆排序
理解堆和优先队列
6.关于本公众号
开号不久作者力争持续输出原创干货,如果文章有帮助到你,
希望朋友们多多转发和分享,作者会更加有动力,推出更好的文章,共同进步。
微信公众号:后端技术指南针
深入理解跳表在Redis中的应用的更多相关文章
- 深入理解跳跃链表在Redis中的应用
0.前言 前面写了一篇关于跳表基本原理和特性的文章,本次继续介绍跳表的概率平衡和工程实现,跳表在Redis.LevelDB.ES中都有应用,本文以Redis为工程蓝本,分析跳表在Redis中的工程实现 ...
- 跳表,Redis 为什么用跳表而不用平衡树?
https://juejin.im/post/57fa935b0e3dd90057c50fbc 在 Redis 中,list 有两种存储方式:双链表(LinkedList)和压缩双链表(ziplist ...
- Redis源码研究--跳表
-------------6月29日-------------------- 简单看了下跳表这一数据结构,理解起来很真实,效率可以和红黑树相比.我就喜欢这样的. typedef struct zski ...
- 红黑树、B(+)树、跳表、AVL等数据结构,应用场景及分析,以及一些英文缩写
在网上学习了一些材料. 这一篇:https://www.zhihu.com/question/30527705 AVL树:最早的平衡二叉树之一.应用相对其他数据结构比较少.windows对进程地址空间 ...
- 聊聊Mysql索引和redis跳表 ---redis的有序集合zset数据结构底层采用了跳表原理 时间复杂度O(logn)(阿里)
redis使用跳表不用B+数的原因是:redis是内存数据库,而B+树纯粹是为了mysql这种IO数据库准备的.B+树的每个节点的数量都是一个mysql分区页的大小(阿里面试) 还有个几个姊妹篇:介绍 ...
- Redis 学习笔记(篇三):跳表
跳表 跳表(skiplist)是一种有序的数据结构,是在有序链表的基础上发展起来的. 在 Redis 中跳表是有序集合(sort set)的底层实现之一. 说到 Redis 中的有序集合,是不是和 J ...
- 跳表(SkipList)原理篇
1.什么是跳表? 维基百科:跳表是一种数据结构.它使得包含n个元素的有序序列的查找和插入操作的平均时间复杂度都是 O(logn),优于数组的 O(n)复杂度.快速的查询效果是通过维护一个多层次的链表实 ...
- 跳表--怎么让一个有序链表能够进行"二分"查找?
对于一个有序数组,如果要查找其中的一个数,我们可以使用二分查找(Binary Search)算法,将它的时间复杂度降低为O(logn).那查找一个有序链表,有没有办法将其时间复杂度也降低为O(logn ...
- Redis中为什么使用跳表---------转自http://blog.csdn.net/u010412301/article/details/64923131
最近在研究数据库的一些底层实现,百度的面试官问到了跳表,当时没有回答上来,在csdn上看到了这篇文章,感觉写的比较好,希望大家可以多多交流. Redis里面使用skiplist是为了实现sorted ...
随机推荐
- 浏览器devtools系列(一)
作为一个web开发人员免不了去和浏览器打交道,前端人员更是如此. 测试人员可能在代码测试的时候容易定位,问题出现在哪里. 不过供桌中常用的可能就是几个,比如前端人员经常看控制面板调试问题,打印后台数据 ...
- Rancher与ARM深化战略合作,“软硬结合”加速边缘计算时代
时至今日,许多企业已将边缘计算列为战略目标,对于部分企业而言,边缘计算则已成为它们势在必行的部分.而随着对应用软件和硬件能力的需求不断增长,容器和Kubernetes已发展为边缘计算领域备受瞩目的一项 ...
- 从零开始把项目发布到Nuget仓库中心
从零开始把项目发布到Nuget仓库中心 我的项目地址 https://github.com/Ants-double/dasuan ### 前期准备 下载并注册nuget帐号 下载地址 https:// ...
- vue与element ui的el-checkbox的坑
一,场景 通过使用checkbox,实现如图的场景, 点击某个tag,实现选中和非选中状态. 二, 官网的例子 通过切换checked值为true或者false来实现,一个checkbox的状态切换 ...
- 【ASP.NET Core学习】Razor页面
准备工作 初始化空的项目(终端输入:dotnet new web -n=Razor) Nuget添加Microsoft.EntityFrameworkCore.SqlServer 和 Microsof ...
- Python+Keras+TensorFlow车牌识别
这个是我使用的车牌识别开源项目的地址:https://github.com/zeusees/HyperLPR Python 依赖 Anaconda for Python 3.x on Win64 Ke ...
- SpringBoot与MybatisPlus整合之活动记录(十五)
活动记录和正常的CRUD效果是一样的,此处只当一个拓展,了解即可 pom.xml <dependencies> <dependency> <groupId>org. ...
- python中的列表list练习
列表: 1.增 1.1 append,在列表的末尾追加元素,使用方法:list.append('元素') li = ['alex', 'wusir', 'eric', 'rain', 'alex'] ...
- 搭建邮件服务器,使用Postfix与Dovecot收发电子邮件
小知识: 我们为什么要搭建邮件服务器呢?有时候我们处于一个局域网内,不能及时的分享各自的研究成果,迫切的需要一种能够借助于网络且建立在计算机之间的传输数据的方法.所以我们需要搭建邮件服务器,这样的话既 ...
- 在VMware15中安装虚拟机并使用Xshell连接到此虚拟机(超详细哦)
首先点击创建新的虚拟机. 此处默认, 点击下一步 默认, 点击下一步 此处可以设置你的虚拟机名称和安装位置(强烈建议不要将安装位置放在系统盘). 此处可根据自己的电脑配置来设置(建议2,4),后续可以 ...