Spark安装与部署
1.首先安装scala(找到合适版本的具体地址下载)
wget https://www.scala-lang.org/download/****
2.安装spark
wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
tar -zxvf spark-2.4.-bin-hadoop2..tgz
rm spark-2.4.-bin-hadoop2..tgz
3.配置环境变量
vim /etc/profile
4.刷新环境变量
source /etc/profile
5.复制配置文件
cp slaves.template slaves
cp spark-env.sh.template spark-env.sh
6.接着进行以下配置
vim /etc/profile(查看其它配置文件直接复制即可)
vim ./spark-2.4.-bin-hadoop2./conf
vim spark-env.sh
7.启动spark环境
1)先启动Hadoop环境
/usr/local/hadoop-2.7./sbin/start-all.sh
2) 启动Spark环境
/usr/local/spark-2.4.-bin-hadoop2./sbin/start-all.sh
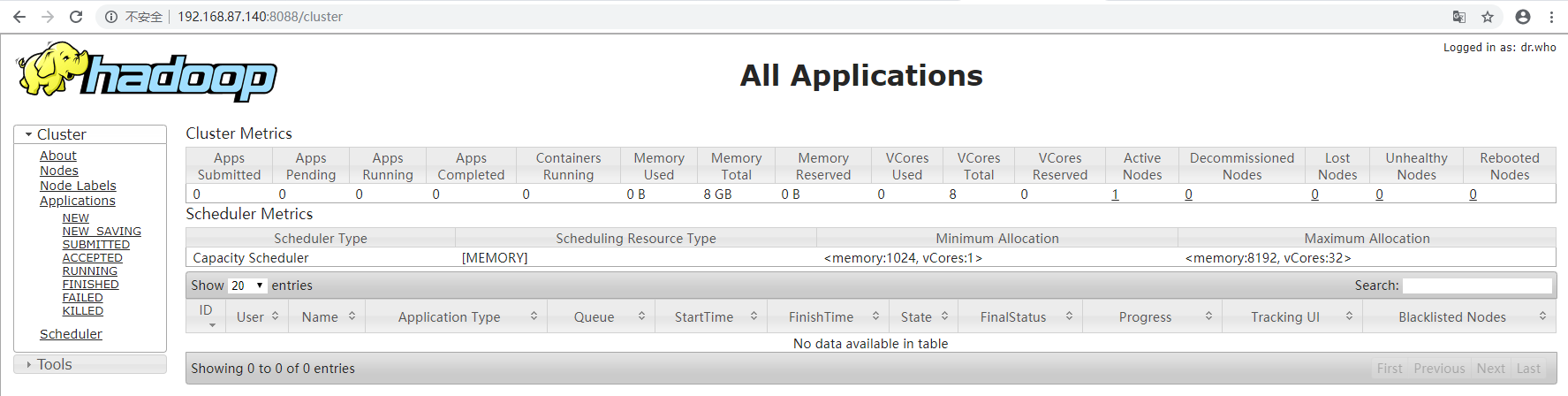
8.查看spark的web控制界面

9.查看Hadoop的web端界面
10.验证Spark是否安装成功
bin/run-example SparkPi

bin/run-example SparkPi >& | grep "Pi is"

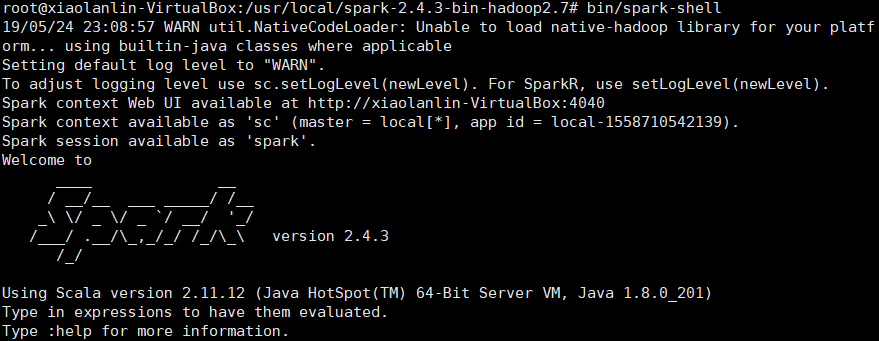
11.使用Spark Shell编写代码
1)启动Spark Shell
bin/spark-shell
2)加载text文件
3)简单RDD操作
scala> textFile.first() // 获取RDD文件textFile的第一行内容
scala> textFile.count() // 获取RDD文件textFile的所有项的计数

scala> val lineWithSpark=textFile.filter(line=>line.contains("Spark"))// 抽取含有“Spark”的行,返回一个新的RDD

scala> lineWithSpark.count() //统计新的RDD的行数

4)可以通过组合RDD操作进行组合,可以实现简易MapReduce操作
scala> textFile.map(line=>line.split(" ").size).reduce((a,b)=>if(a>b) a else b) //找出文本中每行的最多单词数

5)退出Spark shell
:quit

Spark安装与部署的更多相关文章
- Spark入门实战系列--2.Spark编译与部署(中)--Hadoop编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Hadooop 1.1 搭建环境 1.1.1 安装并设置maven 1. 下载mave ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- Spark安装部署(local和standalone模式)
Spark运行的4中模式: Local Standalone Yarn Mesos 一.安装spark前期准备 1.安装java $ sudo tar -zxvf jdk-7u67-linux-x64 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Spark 安装部署与快速上手
Spark 介绍 核心概念 Spark 是 UC Berkeley AMP lab 开发的一个集群计算的框架,类似于 Hadoop,但有很多的区别. 最大的优化是让计算任务的中间结果可以存储在内存中, ...
- spark-2.2.0安装和部署——Spark集群学习日记
前言 在安装后hadoop之后,接下来需要安装的就是Spark. scala-2.11.7下载与安装 具体步骤参见上一篇博文 Spark下载 为了方便,我直接是进入到了/usr/local文件夹下面进 ...
- Spark学习(一) -- Spark安装及简介
标签(空格分隔): Spark 学习中的知识点:函数式编程.泛型编程.面向对象.并行编程. 任何工具的产生都会涉及这几个问题: 现实问题是什么? 理论模型的提出. 工程实现. 思考: 数据规模达到一台 ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- Spark on Mesos部署
一.Mesos的安装和部署 1.下载mesos源码和依赖包 部署环境 centOS 6.6 mesos-0.21.0 spark-1.4.1 因为mesos官方只提供源码,所以必须要自己进行编译安装使 ...
随机推荐
- .Net Core 学习新建Core MVC 项目
一.新建空的Core web项目 二.在Startup文件中添加如下配置 1. 在ConfigureServices 方法中添加 services.AddMvc();MVC服务 2. app.Use ...
- 【题解】【合并序列(水题)P1628】
原题链接 这道题目如果连字符串的基本操作都没学建议不要做. 学了的很简单就可以切,所以感觉没什么难度- 主要讲一下在AC基础上的优化(可能算不上剪枝) 很明显,这道题我们要找的是前缀,那么在字符串数组 ...
- Linux 文件编程、时间编程基本函数
文件编程 文件描述符 fd --->>>数字(文件的身份证,代表文件身份),通过 fd 可找到正在操作或需要打开的文件. 基本函数操作: 1)打开/创建文件 int open (co ...
- //Thread::Stop();
//Thread::Stop(); Thread::StopSoon();
- SpringBoot2.x 整合Spring-Session实现Session共享
SpringBoot2.x 整合Spring-Session实现Session共享 1.前言 发展至今,已经很少还存在单服务的应用架构,不说都使用分布式架构部署, 至少也是多点高可用服务.在多个服务器 ...
- 洛谷P2057 [SHOI2007]善意的投票 题解
题目链接: https://www.luogu.org/problemnew/show/P2057 分析: 由0和1的选择我们直觉的想到0与S一堆,1与T一堆. 但是发现,刚开始的主意并不一定是最终的 ...
- SpringBoot第二十二篇:应用监控之Actuator
作者:追梦1819 原文:https://www.cnblogs.com/yanfei1819/p/11226397.html 版权声明:本文为博主原创文章,转载请附上博文链接! 引言 很多文章都 ...
- 解决Windows10下安装Ubuntu16.04双系统后开机没有Ubuntu引导
转载 https://blog.csdn.net/qq_27838307/article/details/79149791 1.按照网上教程在磁盘中压缩硬盘并且不需要给他新建卷标,就让他显示空闲就好了 ...
- rabbitMQ_workQueue(二)
生产者发送多个消息到队列,由多个消费者消费. 如果一个消费者需要处理一个耗时的任务,那么队列中其他的任务将被迫等待这个消费者处理完成,所以为了避免这样的情况,可以建立对个消费者进行工作. 本例中使 ...
- TestNG使用@Parameter给要测试的方法传递参数
当需要测试的方法含有参数时,可以通过@Parameters 注解给该方法传递参数. 比如下面这个类,要调用whoami则必须写一个main函数,然后在main函数中调用该函数,并传入参数,使用Test ...