python网络爬虫(14)使用Scrapy搭建爬虫框架
目的意义
爬虫框架也许能简化工作量,提高效率等。scrapy是一款方便好用,拓展方便的框架。
本文将使用scrapy框架,示例爬取自己博客中的文章内容。
说明
学习和模仿来源:https://book.douban.com/subject/27061630/。
创建scrapy工程
首先当然要确定好,有没有完成安装scrapy。在windows下,使用pip install scrapy,慢慢等所有依赖和scrapy安装完毕即可。然后输入scrapy到cmd中测试。
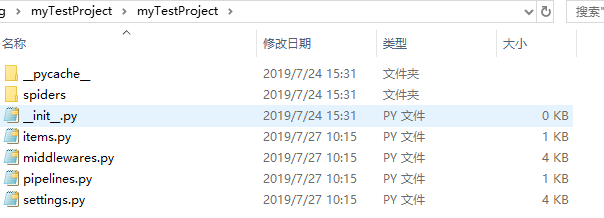
建立工程使用scrapy startproject myTestProject,会在工程下生成文件。
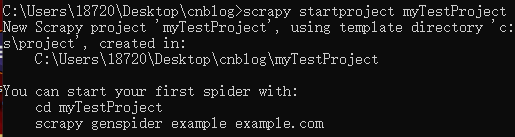
一些介绍说明
在生成的文件中,
创建爬虫模块-下载
在路径./myTestProject/spiders下,放置用户自定义爬虫模块,并定义好name,start_urls,parse()。
如在spiders目录下建立文件CnblogSpider.py,并填入以下:
import scrapy
class CnblogsSpider(scrapy.Spider):
name="cnblogs"
start_urls=["https://www.cnblogs.com/bai2018/default.html?page=1"]
def parse(self,response):
pass
在cmd中,切换到./myTestProject/myTestProject下,再执行scrapy crawl cnblogs(name)测试,观察是否报错,响应代码是否为200。其中的parse中参数response用于解析数据,读取数据等。
强化爬虫模块-解析
在CnblogsSpider类中的parse方法下,添加解析功能。通过xpath、css、extract、re等方法,完成解析。
调取元素审查分析以后添加,成为以下代码:
import scrapy
class CnblogsSpider(scrapy.Spider):
name="cnblogs"
start_urls=["https://www.cnblogs.com/bai2018/"]
def parse(self,response):
papers=response.xpath(".//*[@class='day']")
for paper in papers:
url=paper.xpath(".//*[@class='postTitle']/a/@href").extract()
title=paper.xpath(".//*[@class='postTitle']/a/text()").extract()
time=paper.xpath(".//*[@class='dayTitle']/a/text()").extract()
content=paper.xpath(".//*[@class='postCon']/div/text()").extract()
print(url,title,time,content)
pass
找到页面中,class为day的部分,然后再找到其中各个部分,提取出来,最后通过print方案输出用于测试。
在正确的目录下,使用cmd运行scrapy crawl cnblogs,完成测试,并观察显示信息中的print内容是否符合要求。
强化爬虫模块-包装数据
包装数据的目的是存储数据。scrapy使用Item类来满足这样的需求。
框架中的items.py用于定义存储数据的Item类。
在items.py中修改MytestprojectItem类,成为以下代码:
import scrapy
class MytestprojectItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url=scrapy.Field()
time=scrapy.Field()
title=scrapy.Field()
content=scrapy.Field()
pass
然后修改CnblogsSpider.py,成为以下内容:
import scrapy
from myTestProject.items import MytestprojectItem
class CnblogsSpider(scrapy.Spider):
name="cnblogs"
start_urls=["https://www.cnblogs.com/bai2018/"]
def parse(self,response):
papers=response.xpath(".//*[@class='day']")
for paper in papers:
url=paper.xpath(".//*[@class='postTitle']/a/@href").extract()
title=paper.xpath(".//*[@class='postTitle']/a/text()").extract()
time=paper.xpath(".//*[@class='dayTitle']/a/text()").extract()
content=paper.xpath(".//*[@class='postCon']/div/text()").extract() item=MytestprojectItem(url=url,title=title,time=time,content=content)
yield item
pass
将提取出的内容封装成Item对象,使用关键字yield提交。
强化爬虫模块-翻页
有时候就是需要翻页,以获取更多数据,然后解析。
修改CnblogsSpider.py,成为以下内容:
import scrapy
from scrapy import Selector
from myTestProject.items import MytestprojectItem
class CnblogsSpider(scrapy.Spider):
name="cnblogs"
allowd_domains=["cnblogs.com"]
start_urls=["https://www.cnblogs.com/bai2018/"]
def parse(self,response):
papers=response.xpath(".//*[@class='day']")
for paper in papers:
url=paper.xpath(".//*[@class='postTitle']/a/@href").extract()
title=paper.xpath(".//*[@class='postTitle']/a/text()").extract()
time=paper.xpath(".//*[@class='dayTitle']/a/text()").extract()
content=paper.xpath(".//*[@class='postCon']/div/text()").extract() item=MytestprojectItem(url=url,title=title,time=time,content=content)
yield item
next_page=Selector(response).re(u'<a href="(\S*)">下一页</a>')
if next_page:
yield scrapy.Request(url=next_page[0],callback=self.parse)
pass
在scrapy的选择器方面,使用xpath和css,可以直接将CnblogsSpider下的parse方法中的response参数使用,如response.xpath或response.css。
而更通用的方式是:使用Selector(response).xxx。针对re则为Selector(response).re。
关于yield的说明:https://blog.csdn.net/mieleizhi0522/article/details/82142856
强化爬虫模块-存储
当Item在Spider中被收集时候,会传递到Item Pipeline。
修改pipelines.py成为以下内容:
import json
from scrapy.exceptions import DropItem
class MytestprojectPipeline(object):
def __init__(self):
self.file=open('papers.json','wb')
def process_item(self, item, spider):
if item['title']:
line=json.dumps(dict(item))+"\n"
self.file.write(line.encode())
return item
else:
raise DropItem("Missing title in %s"%item)
重新实现process_item方法,收集item和该item对应的spider。然后创建papers.json,转化item为字典,存储到json表中。
另外,根据提示打开pipelines.py的开关。在settings.py中,使能ITEM_PIPELINES的开关如下:

然后在cmd中执行scrapy crawl cnblogs即可
另外,还可以使用scrapy crawl cnblogs -o papers.csv进行存储为csv文件。
需要更改编码,将csv文件以记事本方式重新打开,更正编码后重新保存,查看即可。
强化爬虫模块-图像下载保存
设定setting.py
ITEM_PIPELINES = {
'myTestProject.pipelines.MytestprojectPipeline':300,
'scrapy.pipelines.images.ImagesPipeline':1
}
IAMGES_STORE='.//cnblogs'
IMAGES_URLS_FIELD = 'cimage_urls'
IMAGES_RESULT_FIELD = 'cimages'
IMAGES_EXPIRES = 30
IMAGES_THUMBS = {
'small': (50, 50),
'big': (270, 270)
}
修改items.py为:
import scrapy
class MytestprojectItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url=scrapy.Field()
time=scrapy.Field()
title=scrapy.Field()
content=scrapy.Field() cimage_urls=scrapy.Field()
cimages=scrapy.Field()
pass
修改CnblogsSpider.py为:
import scrapy
from scrapy import Selector
from myTestProject.items import MytestprojectItem
class CnblogsSpider(scrapy.Spider):
name="cnblogs"
allowd_domains=["cnblogs.com"]
start_urls=["https://www.cnblogs.com/bai2018/"]
def parse(self,response):
papers=response.xpath(".//*[@class='day']")
for paper in papers:
url=paper.xpath(".//*[@class='postTitle']/a/@href").extract()[0]
title=paper.xpath(".//*[@class='postTitle']/a/text()").extract()
time=paper.xpath(".//*[@class='dayTitle']/a/text()").extract()
content=paper.xpath(".//*[@class='postCon']/div/text()").extract() item=MytestprojectItem(url=url,title=title,time=time,content=content)
request=scrapy.Request(url=url, callback=self.parse_body)
request.meta['item']=item yield request
next_page=Selector(response).re(u'<a href="(\S*)">下一页</a>')
if next_page:
yield scrapy.Request(url=next_page[0],callback=self.parse)
pass def parse_body(self, response):
item = response.meta['item']
body = response.xpath(".//*[@class='postBody']")
item['cimage_urls'] = body.xpath('.//img//@src').extract()
yield item
总之,修改以上三个位置。在有时候配置正确的时候却出现图像等下载失败,则可能是由于setting.py的原因,需要重新修改。
启动爬虫
建立main函数,传递初始化信息,导入指定类。如:
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings from myTestProject.spiders.CnblogSpider import CnblogsSpider if __name__=='__main__':
process = CrawlerProcess(get_project_settings())
process.crawl('cnblogs')
process.start()
修正
import scrapy
from scrapy import Selector
from cnblogSpider.items import CnblogspiderItem
class CnblogsSpider(scrapy.Spider):
name="cnblogs"
allowd_domains=["cnblogs.com"]
start_urls=["https://www.cnblogs.com/bai2018/"]
def parse(self,response):
papers=response.xpath(".//*[@class='day']")
for paper in papers:
urls=paper.xpath(".//*[@class='postTitle']/a/@href").extract()
titles=paper.xpath(".//*[@class='postTitle']/a/text()").extract()
times=paper.xpath(".//*[@class='dayTitle']/a/text()").extract()
contents=paper.xpath(".//*[@class='postCon']/div/text()").extract()
for i in range(len(urls)):
url=urls[i]
title=titles[i]
time=times[0]
content=contents[i]
item=CnblogspiderItem(url=url,title=title,time=time,content=content)
request = scrapy.Request(url=url, callback=self.parse_body)
request.meta['item'] = item
yield request
next_page=Selector(response).re(u'<a href="(\S*)">下一页</a>')
if next_page:
yield scrapy.Request(url=next_page[0],callback=self.parse)
pass def parse_body(self, response):
item = response.meta['item']
body = response.xpath(".//*[@class='postBody']")
item['cimage_urls'] = body.xpath('.//img//@src').extract()
yield item
我的博客即将同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=813cva9t28s6
python网络爬虫(14)使用Scrapy搭建爬虫框架的更多相关文章
- Python网络编程相关的库与爬虫基础
PythonWeb编程 ①相关的库:urlib.urlib2.requests python中自带urlib和urlib2,他们主要使用函数如下: urllib: urlib.urlopen() ur ...
- 5、爬虫系列之scrapy框架
一 scrapy框架简介 1 介绍 (1) 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能 ...
- 爬虫系列之Scrapy框架
一 scrapy框架简介 1 介绍 (1) 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能 ...
- 爬虫开发7.scrapy框架简介和基础应用
scrapy框架简介和基础应用阅读量: 1432 scrapy 今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数 ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- 【python 网络爬虫】之scrapy系列
网络爬虫之scripy系列 [scrapy网络爬虫]之0 爬虫与反扒 [scrapy网络爬虫]之一 scrapy框架简介和基础应用 [scrapy网络爬虫]之二 持久化操作 [scrapy网络爬虫]之 ...
- python网络爬虫(2)——scrapy框架的基础使用
这里写一下爬虫大概的步骤,主要是自己巩固一下知识,顺便复习一下. 一,网络爬虫的步骤 1,创建一个工程 scrapy startproject 工程名称 创建好工程后,目录结构大概如下: 其中: sc ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- Python网络爬虫-Scrapy框架
一.简介 Spider是所有爬虫的基类,其设计原则只是为了爬取start_url列表中网页,而从爬取到的网页中提取出的url进行继续的爬取工作使用CrawlSpider更合适. 二.使用 1.创建sc ...
随机推荐
- 第四章 .net core做一个简单的登录
项目目标部署环境:CentOS 7+ 项目技术点:.netcore2.0 + Autofac +webAPI + NHibernate5.1 + mysql5.6 + nginx 开源地址:https ...
- vue.js与后台模板引擎“双花括号”冲突时的解决办法
后台渲染模板如swig,也使用“{{ }}“作为渲染,与前端vue的产生冲突,此时只要在新建Vue对象时,添加delimiters: ['${', '}'],就搞定了,代码如下 <!DOCTYP ...
- 深入解析Hyperledger Fabric启动的全过程
在这篇文章中,使用fabric-samples/first-network中的文件进行fabric网络(solo类型的网络)启动全过程的解析.如有错误欢迎批评指正. 至于Fabric网络的搭建这里不再 ...
- laravel中的构造函数依赖注入理解
laravel中的自动依赖注入是非常强大的,刚开始会疑惑为什么只要在构造函数中传入一个强制类型的变量(就是参数有类型限制)过去就行了? 通过查看源码即查阅资料发现其实这其中有一个php技术,就是反射技 ...
- java 字符串内存分配的分析与总结
经常在网上各大版块都能看到对于java字符串运行时内存分配的探讨,形如:String a = "123",String b = new String("123" ...
- linux 安装 websocketd
1.下载 wget https://github.com/joewalnes/websocketd/releases/download/v0.3.0/websocketd-0.3.0-linux_am ...
- 机器学习经典算法之EM
一.简介 EM 的英文是 Expectation Maximization,所以 EM 算法也叫最大期望算法. 我们先看一个简单的场景:假设你炒了一份菜,想要把它平均分到两个碟子里,该怎么分? 很少有 ...
- 并发编程-concurrent指南-原子操作类-AtomicInteger
在java并发编程中,会出现++,--等操作,但是这些不是原子性操作,这在线程安全上面就会出现相应的问题.因此java提供了相应类的原子性操作类. 1.AtomicInteger
- Kafka Eagle V1.3.4更新预览
1.概述 Kafka Eagle是一款开源的Kafka集群监控系统,源代码托管在Github.目前Kafka Eagle已更新到V1.3.4版本,域名已经统一更新为http://www.kafka-e ...
- Android实现跳转到应用市场进行版本更新功能
最近需要做应用版本更新功能,因为之前已经写过一篇版本更新的功能了,虽然请求接口还是用的HttpUrlConnection,想着改改现在应用使用的请求方式也挺快的嘛,心里开始暗喜,可以偷偷懒了,哈哈哈. ...