keras 学习笔记(一) ——— model.fit & model.fit_generator
from keras.preprocessing.image import load_img, img_to_array
a = load_img('1.jpg')
b = img_to_array(a)
print (type(a),type(b))
输出:
a type:<class 'PIL.JpegImagePlugin.JpegImageFile'>,b type:<class 'numpy.ndarray'>
optimizer:
Adam :
算法思想 [1]:
Adam中动量直接并入了梯度一阶矩(指数加权)的估计。其次,相比于缺少修正因子导致二阶矩估计可能在训练初期具有很高偏置的RMSProp,Adam包括偏置修正,修正从原点初始化的一阶矩(动量项)和(非中心的)二阶矩估计。
数学表达式:
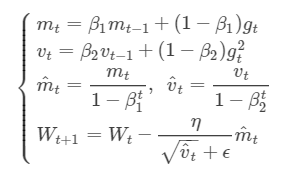
mt和vt分别为一阶动量项和二阶动量项;m^t,v^t为各自的修正值。
beta_1, beta_2为动力值大小通常分别取0.9和0.999。
Wt表示t时刻即第t次迭代模型的参数,gt=ΔJ(Wt)表示t次迭代代价函数关于W的梯度大小
ϵ是一个取值很小的数(一般为1e-8)为了避免分母为0,tensorflow作为backend时,ϵ=1e-7
评价:Adam通常被认为对超参数的选择相当鲁棒,尽管学习率有时需要从建议的默认修改。
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False) lr: float >= 0. Learning rate.
beta_1: float, 0 < beta < 1. Generally close to 1.default 0.9,通常保持不变
beta_2: float, 0 < beta < 1. Generally close to 1.default 0.999,通常保持不变
epsilon: float >= 0. Fuzz factor. If None, defaults to K.epsilon(). decay: float >= 0. Learning rate decay over each update. amsgrad: boolean. Whether to apply the AMSGrad variant of this algorithm
from the paper "On the Convergence of Adam and Beyond".
SGD :
AdaGrad:
Reference:
https://blog.csdn.net/weixin_40170902/article/details/80092628
model.fit()
fit(x=None, y=None, batch_size=None, epochs=1, verbose=1,
callbacks=None, validation_split=0.0, validation_data=None,
shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0,
steps_per_epoch=None, validation_steps=None, validation_freq=1)
model.fit_generator()
使用数据data_generator 传输数据,用于大型数据集,直接读取大型数据集会导致内存占用过高。
fit_generator(generator, steps_per_epoch=None, epochs=1, verbose=1,
callbacks=None, validation_data=None, validation_steps=None,
validation_freq=1, class_weight=None, max_queue_size=10, workers=1,
use_multiprocessing=False, shuffle=True, initial_epoch=0)
callbacks
list()值,当call中条件不满足时停止更新权重,
keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=0, verbose=0, mode='auto', baseline=None, restore_best_weights=False)
monitor:需要监视的值,[acc,loss],如果fit种有validation_data,还可使用val_acc, val_loss等
min_delta: 改变的值如果小于min_delta, 将不视为有提高。
patience: 从最好的开始,经过patience个epoch仍未提高,则停止training
_obtain_input_shape()
keras 2.2.2中,keras.applications.imagenet_utils模块不再有_obtain_input_shape, _obtain_input_shape的根模块改为了keras_applications.imagenet_utils
形式改为了
_obtain_input_shape(input_shape,
default_size = 224,
min_size = 32,
data_format = K.image_data_format(),
require_flatten = True,
weights=None):_obtain_input_shape(input_shape,
default_size=224,
min_size=32,
data_format=K.image_data_format(),
include_top=include_top or weights)
keras 学习笔记(一) ——— model.fit & model.fit_generator的更多相关文章
- 官网实例详解-目录和实例简介-keras学习笔记四
官网实例详解-目录和实例简介-keras学习笔记四 2018-06-11 10:36:18 wyx100 阅读数 4193更多 分类专栏: 人工智能 python 深度学习 keras 版权声明: ...
- Keras学习笔记——Hello Keras
最近几年,随着AlphaGo的崛起,深度学习开始出现在各个领域,比如无人车.图像识别.物体检测.推荐系统.语音识别.聊天问答等等.因此具备深度学习的知识并能应用实践,已经成为很多开发者包括博主本人的下 ...
- Keras学习笔记1--基本入门
""" 1.30s上手keras """ #keras的核心数据结构是“模型”,模型是一种组织网络层的方式,keras 的主要模型是Sequ ...
- keras 学习笔记:从头开始构建网络处理 mnist
全文参考 < 基于 python 的深度学习实战> import numpy as np from keras.datasets import mnist from keras.model ...
- keras学习笔记-bili莫烦
一.keras的backend设置 有两种方式: 1.修改JSON配置文件 修改~/.keras/keras.json文件内容为: { "iamge_dim_ordering":& ...
- Python学习笔记:Flask-Migrate基于model做upgrade的基本原理
1)flask-migrate的官网:https://flask-migrate.readthedocs.io/en/latest/ 2)获取帮助,在pycharm的控制台中输入 flask d ...
- backbone学习笔记:模型(Model)(2)属性验证
Backbone的属性验证有2种方法: 1.Backbone自带简单的验证方法,但是验证规则需要自己实现 通过validate()方法进行验证,验证规则写在此方法里. var RoomModel = ...
- backbone学习笔记:模型(Model)(1)基础知识
backbone为复杂Javascript应用程序提供MVC(Model View Controller)框架,框架里最基本的是Model(模型),它用来处理数据,对数据进行验证,完成后台数据与前台数 ...
- Python-Django学习笔记(三)-Model模型的编写以及Oracle数据库的配置
Django使用的 MTV 设计模式(Models.Templates.Views) 因此本节将围绕这三部分并按照这个顺序来创建第一个页面 模型层models.py 模型是数据唯一而且准确的信息来源. ...
随机推荐
- Linux下查看哪些进程占用的CPU、内存资源
1.CPU占用最多的前10个进程: ps auxw|head -1;ps auxw|sort -rn -k3|head -10 2.内存消耗最多的前10个进程 ps auxw|head -1;ps a ...
- CF414D Mashmokh and Water Tanks
CF414D Mashmokh and Water Tanks 洛谷评测传送门 题目描述 Mashmokh is playing a new game. In the beginning he has ...
- http2多路复用
http2多路复用 HTTP2采用二进制格式传输,取代了HTTP1.x的文本格式,二进制格式解析更高效. 多路复用代替了HTTP1.x的序列和阻塞机制,所有的相同域名请求都通过同一个TCP连接并发完成 ...
- hashlib和hmac模块
目录 一.hashlib模块 1.0.1 hash是什么 1.0.2 撞库破解hash算法加密 一.hashlib模块 1.0.1 hash是什么 hash是一种算法(Python3.版本里使用has ...
- HTML连载50-伪元素选择器、清除浮动方式五
一.伪元素选择器 1.什么是伪元素选择器 伪元素选择器作用给指定标签的内容前面添加一个子元素,或者给指定标签的内容后面添加一个子元素. 2.格式: 标签名称::before{ 属性名称:值: } 给指 ...
- 图解Java常用数据结构
最近在整理数据结构方面的知识, 系统化看了下 Java 中常用数据结构, 突发奇想用动画来绘制数据流转过程. 主要基于 jdk8, 可能会有些特性与 jdk7 之前不相同, 例如 LinkedList ...
- IT兄弟连 HTML5教程 HTML5的靠山 W3C、IETF是什么
无规矩不成方圆,软件开发当然不能例外.Web开发涉及的厂商和技术非常多,所以必须要有参考的标准,而且需要一系列的标准.Web程序都是通过浏览器来解析执行的,通过页面的展示内容与用户互动,所以Web标准 ...
- 解决上一篇bean.xml中<bean>标签报错“ Error while downloading 'http://www.springframework.org/schema/beans/spring-beans.xsd........”
在xml文件中,头部报错如题 一开始查询,说是头部少了“<?xml version="1.0" encoding="UTF-8"?>”,但是我并没有 ...
- python3中的数字类型
今天在学校机房刷python题时发现自己对python中的数字类型不理解,回寝室后百度一下. 现在做一个总结. python中的数字类型有: 整数,布尔值,复数,科学计数法,浮点数 1,整数,大小没有 ...
- 用redis-dump工具对redis集群所有数据进行导出导入
安装redis-dump redis-dump是基于ruby开发,需要ruby环境,而且新版本的redis-dump要求2.2.2以上的ruby版本,centos中yum只能安装2.0版本的ruby. ...