避免HBase PageFilter踩坑,这几点你必须要清楚
有这样一个场景,在HBase中需要分页查询,同时根据某一列的值进行过滤。
不同于RDBMS天然支持分页查询,HBase要进行分页必须由自己实现。据我了解的,目前有两种方案, 一是《HBase权威指南》中提到的用PageFilter加循环动态设置startRow实现,详细见这里。但这种方法效率比较低,且有冗余查询。因此京东研发了一种用额外的一张表来保存行序号的方案。 该种方案效率较高,但实现麻烦些,需要维护一张额外的表。
不管是方案也好,人也好,没有最好的,只有最适合的。
在我司的使用场景中,对于性能的要求并不高,所以采取了第一种方案。本来使用的美滋滋,但有一天需要在分页查询的同时根据某一列的值进行过滤。根据列值过滤,自然是用SingleColumnValueFilter(下文简称SCVFilter)。代码大致如下,只列出了本文主题相关的逻辑,
Scan scan = initScan(xxx);
FilterList filterList=new FilterList();
scan.setFilter(filterList);
filterList.addFilter(new PageFilter(1));
filterList.addFilter(new SingleColumnValueFilter(FAMILY,ISDELETED, CompareFilter.CompareOp.EQUAL, Bytes.toBytes(false)));
数据如下
row1 column=f:content, timestamp=1513953705613, value=content1
row1 column=f:isDel, timestamp=1513953705613, value=1
row1 column=f:name, timestamp=1513953725029, value=name1
row2 column=f:content, timestamp=1513953705613, value=content2
row2 column=f:isDel, timestamp=1513953744613, value=0
row2 column=f:name, timestamp=1513953730348, value=name2
row3 column=f:content, timestamp=1513953705613, value=content3
row3 column=f:isDel, timestamp=1513953751332, value=0
row3 column=f:name, timestamp=1513953734698, value=name3
在上面的代码中。向scan添加了两个filter:首先添加了PageFilter,限制这次查询数量为1,然后添加了一个SCVFilter,限制了只返回isDeleted=false的行。
上面的代码,看上去无懈可击,但在运行时却没有查询到数据!
刚好最近在看HBase的代码,就在本地debug了下HBase服务端Filter相关的查询流程。
Filter流程
首先看下HBase Filter的流程,见图:
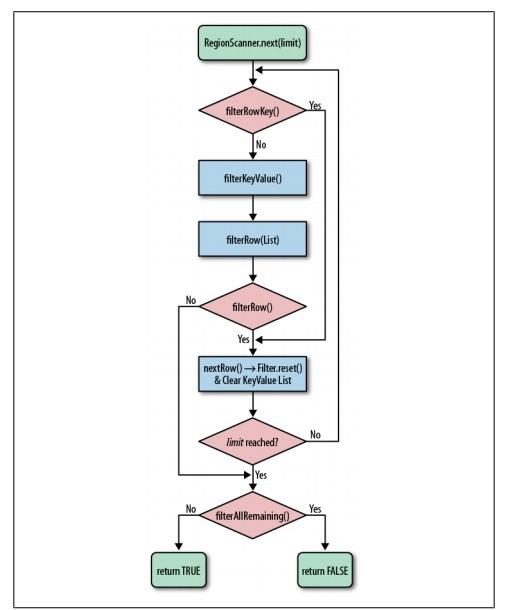
然后再看PageFilter的实现逻辑。
public class PageFilter extends FilterBase {
private long pageSize = Long.MAX_VALUE;
private int rowsAccepted = 0;
/**
* Constructor that takes a maximum page size.
*
* @param pageSize Maximum result size.
*/
public PageFilter(final long pageSize) {
Preconditions.checkArgument(pageSize >= 0, "must be positive %s", pageSize);
this.pageSize = pageSize;
}
public long getPageSize() {
return pageSize;
}
@Override
public ReturnCode filterKeyValue(Cell ignored) throws IOException {
return ReturnCode.INCLUDE;
}
public boolean filterAllRemaining() {
return this.rowsAccepted >= this.pageSize;
}
public boolean filterRow() {
this.rowsAccepted++;
return this.rowsAccepted > this.pageSize;
}
}
其实很简单,内部有一个计数器,每次调用filterRow的时候,计数器都会+1,如果计数器值大于pageSize,filterrow就会返回true,那之后的行就会被过滤掉。
再看SCVFilter的实现逻辑。
public class SingleColumnValueFilter extends FilterBase {
private static final Log LOG = LogFactory.getLog(SingleColumnValueFilter.class);
protected byte [] columnFamily;
protected byte [] columnQualifier;
protected CompareOp compareOp;
protected ByteArrayComparable comparator;
protected boolean foundColumn = false;
protected boolean matchedColumn = false;
protected boolean filterIfMissing = false;
protected boolean latestVersionOnly = true;
/**
* Constructor for binary compare of the value of a single column. If the
* column is found and the condition passes, all columns of the row will be
* emitted. If the condition fails, the row will not be emitted.
* <p>
* Use the filterIfColumnMissing flag to set whether the rest of the columns
* in a row will be emitted if the specified column to check is not found in
* the row.
*
* @param family name of column family
* @param qualifier name of column qualifier
* @param compareOp operator
* @param comparator Comparator to use.
*/
public SingleColumnValueFilter(final byte [] family, final byte [] qualifier,
final CompareOp compareOp, final ByteArrayComparable comparator) {
this.columnFamily = family;
this.columnQualifier = qualifier;
this.compareOp = compareOp;
this.comparator = comparator;
}
@Override
public ReturnCode filterKeyValue(Cell c) {
if (this.matchedColumn) {
// We already found and matched the single column, all keys now pass
return ReturnCode.INCLUDE;
} else if (this.latestVersionOnly && this.foundColumn) {
// We found but did not match the single column, skip to next row
return ReturnCode.NEXT_ROW;
}
if (!CellUtil.matchingColumn(c, this.columnFamily, this.columnQualifier)) {
return ReturnCode.INCLUDE;
}
foundColumn = true;
if (filterColumnValue(c.getValueArray(), c.getValueOffset(), c.getValueLength())) {
return this.latestVersionOnly? ReturnCode.NEXT_ROW: ReturnCode.INCLUDE;
}
this.matchedColumn = true;
return ReturnCode.INCLUDE;
}
private boolean filterColumnValue(final byte [] data, final int offset,
final int length) {
int compareResult = this.comparator.compareTo(data, offset, length);
switch (this.compareOp) {
case LESS:
return compareResult <= 0;
case LESS_OR_EQUAL:
return compareResult < 0;
case EQUAL:
return compareResult != 0;
case NOT_EQUAL:
return compareResult == 0;
case GREATER_OR_EQUAL:
return compareResult > 0;
case GREATER:
return compareResult >= 0;
default:
throw new RuntimeException("Unknown Compare op " + compareOp.name());
}
}
public boolean filterRow() {
// If column was found, return false if it was matched, true if it was not
// If column not found, return true if we filter if missing, false if not
return this.foundColumn? !this.matchedColumn: this.filterIfMissing;
}
}
在HBase中,对于每一行的每一列都会调用到filterKeyValue,SCVFilter的该方法处理逻辑如下:
1. 如果已经匹配过对应的列并且对应列的值符合要求,则直接返回INCLUE,表示这一行的这一列要被加入到结果集
2. 否则如latestVersionOnly为true(latestVersionOnly代表是否只查询最新的数据,一般为true),并且已经匹配过对应的列(但是对应的列的值不满足要求),则返回EXCLUDE,代表丢弃该行
3. 如果当前列不是要匹配的列。则返回INCLUDE,否则将matchedColumn置为true,代表以及找到了目标列
4. 如果当前列的值不满足要求,在latestVersionOnly为true时,返回NEXT_ROW,代表忽略当前行还剩下的列,直接跳到下一行
5. 如果当前列的值满足要求,将matchedColumn置为true,代表已经找到了对应的列,并且对应的列值满足要求。这样,该行下一列再进入这个方法时,到第1步就会直接返回,提高匹配效率再看filterRow方法,该方法调用时机在filterKeyValue之后,对每一行只会调用一次。
SCVFilter中该方法逻辑很简单:
1. 如果找到了对应的列,如其值满足要求,则返回false,代表将该行加入到结果集,如其值不满足要求,则返回true,代表过滤该行
2. 如果没找到对应的列,返回filterIfMissing的值。猜想:
是不是因为将PageFilter添加到SCVFilter的前面,当判断第一行的时候,调用PageFilter的filterRow,导致PageFilter的计数器+1,但是进行到SCVFilter的filterRow的时候,该行又被过滤掉了,在检验下一行时,因为PageFilter计数器已经达到了我们设定的pageSize,所以接下来的行都会被过滤掉,返回结果没有数据。
验证:
在FilterList中,先加入SCVFilter,再加入PageFilter
Scan scan = initScan(xxx);
FilterList filterList=new FilterList();
scan.setFilter(filterList);
filterList.addFilter(new SingleColumnValueFilter(FAMILY,ISDELETED, CompareFilter.CompareOp.EQUAL, Bytes.toBytes(false)));
filterList.addFilter(new PageFilter(1));
结果是我们期望的第2行的值。
结论
当要将PageFilter和其他Filter使用时,最好将PageFilter加入到FilterList的末尾,否则可能会出现结果个数小于你期望的数量。
(其实正常情况PageFilter返回的结果数量可能大于设定的值,因为服务器集群的PageFilter是隔离的。)
彩蛋
其实,在排查问题的过程中,并没有这样顺利,因为问题出在线上,所以我在本地查问题时自己造了一些测试数据,令人惊讶的是,就算我先加入SCVFilter,再加入PageFilter,返回的结果也是符合预期的。
测试数据如下:
row1 column=f:isDel, timestamp=1513953705613, value=1
row1 column=f:name, timestamp=1513953725029, value=name1
row2 column=f:isDel, timestamp=1513953744613, value=0
row2 column=f:name, timestamp=1513953730348, value=name2
row3 column=f:isDel, timestamp=1513953751332, value=0
row3 column=f:name, timestamp=1513953734698, value=name3
当时在本地一直不能复现问题。很是苦恼,最后竟然发现使用SCVFilter查询的结果还和数据的列的顺序有关。
在服务端,HBase会对客户端传递过来的filter封装成FilterWrapper。
class RegionScannerImpl implements RegionScanner {
RegionScannerImpl(Scan scan, List<KeyValueScanner> additionalScanners, HRegion region)
throws IOException {
this.region = region;
this.maxResultSize = scan.getMaxResultSize();
if (scan.hasFilter()) {
this.filter = new FilterWrapper(scan.getFilter());
} else {
this.filter = null;
}
}
....
}
在查询数据时,在HRegion的nextInternal方法中,会调用FilterWrapper的filterRowCellsWithRet方法
FilterWrapper相关代码如下:
/**
* This is a Filter wrapper class which is used in the server side. Some filter
* related hooks can be defined in this wrapper. The only way to create a
* FilterWrapper instance is passing a client side Filter instance through
* {@link org.apache.hadoop.hbase.client.Scan#getFilter()}.
*
*/ final public class FilterWrapper extends Filter {
Filter filter = null; public FilterWrapper( Filter filter ) {
if (null == filter) {
// ensure the filter instance is not null
throw new NullPointerException("Cannot create FilterWrapper with null Filter");
}
this.filter = filter;
} public enum FilterRowRetCode {
NOT_CALLED,
INCLUDE, // corresponds to filter.filterRow() returning false
EXCLUDE // corresponds to filter.filterRow() returning true
} public FilterRowRetCode filterRowCellsWithRet(List<Cell> kvs) throws IOException {
this.filter.filterRowCells(kvs);
if (!kvs.isEmpty()) {
if (this.filter.filterRow()) {
kvs.clear();
return FilterRowRetCode.EXCLUDE;
}
return FilterRowRetCode.INCLUDE;
}
return FilterRowRetCode.NOT_CALLED;
} }
这里的kvs就是一行数据经过filterKeyValue后没被过滤的列。
可以看到当kvs不为empty时,filterRowCellsWithRet方法中会调用指定filter的filterRow方法,上面已经说过了,PageFilter的计数器就是在其filterRow方法中增加的。
而当kvs为empty时,PageFilter的计数器就不会增加了。再看我们的测试数据,因为行的第一列就是SCVFilter的目标列isDeleted。回顾上面SCVFilter的讲解我们知道,当一行的目标列的值不满足要求时,该行剩下的列都会直接被过滤掉!
对于测试数据第一行,走到filterRowCellsWithRet时kvs是empty的。导致PageFilter的计数器没有+1。还会继续遍历剩下的行。从而使得返回的结果看上去是正常的。
而出问题的数据,因为在列isDeleted之前还有列content,所以当一行的isDeleted不满足要求时,kvs也不会为empty。因为列content的值已经加入到kvs中了(这些数据要调用到SCVFilter的filterrow的时间会被过滤掉)。
感想
从实现上来看HBase的Filter的实现还是比较粗糙的。效率也比较感人,不考虑网络传输和客户端内存的消耗,基本上和你在客户端过滤差不多。
本人免费整理了Java高级资料,涵盖了Java、Redis、MongoDB、MySQL、Zookeeper、Spring Cloud、Dubbo高并发分布式等教程,一共30G,需要自己领取。
传送门:https://mp.weixin.qq.com/s/JzddfH-7yNudmkjT0IRL8Q
避免HBase PageFilter踩坑,这几点你必须要清楚的更多相关文章
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- [转]Spark 踩坑记:数据库(Hbase+Mysql)
https://cloud.tencent.com/developer/article/1004820 Spark 踩坑记:数据库(Hbase+Mysql) 前言 在使用Spark Streaming ...
- Spark踩坑记——数据库(Hbase+Mysql)转
转自:http://www.cnblogs.com/xlturing/p/spark.html 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库 ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark踩坑记——共享变量
[TOC] 前言 Spark踩坑记--初试 Spark踩坑记--数据库(Hbase+Mysql) Spark踩坑记--Spark Streaming+kafka应用及调优 在前面总结的几篇spark踩 ...
- Spark踩坑记——从RDD看集群调度
[TOC] 前言 在Spark的使用中,性能的调优配置过程中,查阅了很多资料,之前自己总结过两篇小博文Spark踩坑记--初试和Spark踩坑记--数据库(Hbase+Mysql),第一篇概况的归纳了 ...
- Spark踩坑记:Spark Streaming+kafka应用及调优
前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从k ...
- 一次flume exec source采集日志到kafka因为单条日志数据非常大同步失败的踩坑带来的思考
本次遇到的问题描述,日志采集同步时,当单条日志(日志文件中一行日志)超过2M大小,数据无法采集同步到kafka,分析后,共踩到如下几个坑.1.flume采集时,通过shell+EXEC(tail -F ...
- 一次shardingjdbc踩坑引起的胡思乱想
项目里面的一个分表用到了sharding-jdbc 当时纠结过是用mycat还是用sharding-jdbc的, 但是最终还是用了sharding-jdbc, 原因如下: 1. mycat比较重, 相 ...
随机推荐
- centos7下编译安装python3.7,且与python2.7.5共存
环境:Centos7.6 x64 一.安装python3.7 下载python源码包: wget https://www.python.org/ftp/python/3.7.4/Python-3.7. ...
- 做一个vue轮播图组件
根据huangyi老师的慕课网vue项目跟着做的,下面大概记录了下思路 1.轮播图的图 先不做轮播图逻辑部分,先把数据导进来,看看什么效果.在recommend组件新建一个recommends的数组, ...
- git设置多账户
1.设置公司gitlab 0.先给git 设置一个全局的账户, 如果是公司的电脑环境, 全局的账户当然是用你在公司的邮箱了 git config --global user.name "yo ...
- 详细设计文档(final)
1. 引言 1.1编写目的 本部分旨在阐明编写详细设计的目的,面向读者对象. 本文档主要描述各个模块的细节设计,明确软件的结构与实现过程,分析各个模块,描述模块的功能.性能和结构等方面包括模块接口.调 ...
- Ubantu搭建虚拟环境
配置虚拟环境 Ubantu16.0.4 1.安装python虚拟环境 sudo apt-get install virtualenv 2.vrtaulenvwrapper是virtualenv的扩展包 ...
- liteos分散加载(十四)
1. 概述 1.1 基本概念 分散加载是一种实现特定代码快速启动的技术,通过优先加载特定代码到内存,达到缩短从系统开机到特定代码执行的时间.可被应用来实现关键业务的快速启动. 嵌入式系统通过uboot ...
- Python异常类型及处理、自定义异常类型、断言
异常的概念.识别报错信息 异常处理 断言的基本使用 异常类型(异常就是报错) 常见异常 NameError:名称错误 SyntaxError:语法错误 TypeError:类型错误 错误回溯 查看报错 ...
- G1 垃圾收集器架构和如何做到可预测的停顿(阿里)
CMS垃圾回收机制 参考:图解 CMS 垃圾回收机制原理,-阿里面试题 CMS与G1的区别 参考:CMS收集器和G1收集器优缺点 写这篇文章是基于阿里面试官的一个问题:众所周期,G1跟其他的垃圾回收算 ...
- 【转】带栗子的GDB教程
带栗子的GDB教程 原文链接:http://www.cprogramming.com/gdb.html作者:Manasij Mukherjee 一个好的调试软件是一个程序猿的工具箱里最重要的工具之一, ...
- c# 第33节 类的封装--访问修饰符
本节内容: 1:封装的简介 2:封装怎么实现 3:访问修饰符 1:封装的简介 2:封装怎么实现 3:访问修饰符 4:访问修饰符注意点