什么是索引?
“索引”是为了能够更快地查询数据。比如一本书的目录,就是这本书的内容的索引,读者可以通过在目录中快速查找自己想要的内容,然后根据页码去找到具体的章节。
数据库也是一样,如果查询语句使用到了索引,会先去索引里面查询,取得数据所在行的物理地址,进而访问数据。
索引的优缺点
优势:以快速检索,减少I/O次数,加快检索速度;根据索引分组和排序,可以加快分组和排序;
劣势:索引本身也是表,因此会占用存储空间。索引的维护和创建需要时间成本,这个成本随着数据量增大而增大;构建索引会降低数据表的修改操作(删除,添加,修改)的效率,因为在修改数据表的同时还需要修改索引表。
索引的分类
在MySQL中,常见的索引类型有:主键索引、唯一索引、普通索引、全文索引、组合索引。创建语法分别为:

其中,组合索引又称为多列索引,上述代码中最后一个例子就是建立了3列的索引。MySQL在根据索引查询时,会遵循“最左匹配”原则,即先根据col1的条件查,再根据col2的条件查,然后再根据col3的条件去查。
如果跳过了一个列直接查后面的列,比如下面的语句,就不能使用上面创建的索引了:
这里有一个小技巧,如果你前面的列是一个简单的枚举类型,比如性别等,可以用在where语句中加 col1 in(MALE, FEMALE) 来“跳过” col1 列,并使用上述索引。
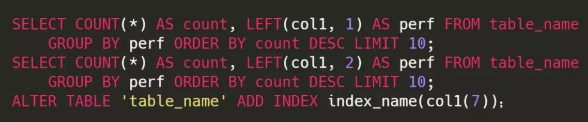
对于某列如果是字符串且比较长(比如UUID),推荐使用前缀索引,即匹配前n个字符。具体这个n取值多少是根据你的数据来的,通过使用 LEFT 函数查询,从1开始,不断增加n的值,直到查询结果的行数接近完整列的查询结果的行数,就是合适的n的值。
索引的实现原理
MySQL的索引是由存储引擎来实现的。由于存储引擎不同,所以具有不同的索引类型,如BTree索引,B+Tree索引,哈希索引,全文索引等。这里由于主要介绍BTree索引和B+Tree索引,我们平时使用最多的InnoDB引擎就是基于B+Tree索引的。
目前版本的MySQL InnoDB引擎已经支持全文索引,但不支持中文,可以通过使用ngram插件开始支持中文。
从二叉搜索树开始
了解过数据结构的应该知道一种叫二叉树的数据结构。二叉树根据用途不同,衍生了不同的变种,比如堆,比如二叉搜索树。
而二叉搜索树中,为了防止极端情况树的高度过大影响查询效率,所以衍生出了一些平衡二叉查找树,最典型的就是AVL和红黑树。
但二叉树在数据量较大时,深度过深,不太适合数据库的查询,所以数据库使用了多叉树。
BTree
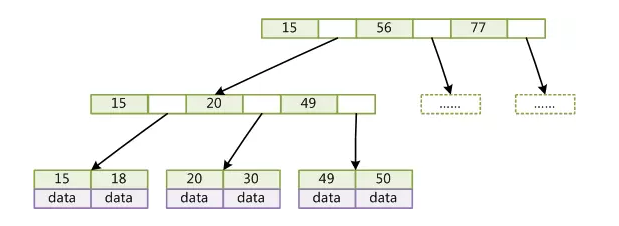
BTree(又称为B-Tree)是一个平衡搜索多叉树。BTree的结构如下图:
设树的度为2d(d>1),高度为h,那么BTree有以下性质:
每个叶子结点的高度一样,等于h;
每个非叶子结点由n-1个key和n个指针组成,key和指针相互隔离,结点两端一定是key;
叶子结点指针为null;
非叶子结点的key都是[key,data]二元组,其中key表示作为索引的键,data为键值所在行的其它列的数据;
在BTree中,对索引列是顺序存储的,所以很适合查找范围数据和ORDER BY操作。
B+Tree
B+Tree是BTree的一种变种。B+Tree和BTree的不同主要在于:
B+Tree中的非叶子结点不存储数据,只存储键值;
B+Tree的叶子结点没有指针,所有键值都会出现在叶子结点上,且key存储的键值对应data数据的物理地址;
B+Tree的每个非叶子节点由n个键值key和n个指针point组成;
结构图:
B+Tree对比BTree的优点:
一般来说B+Tree比BTree更适合实现外存的索引结构,因为存储引擎的设计专家巧妙的利用了外存(磁盘)的存储结构。
磁盘的最小存储单位是扇区(sector),而操作系统的块(block)通常是整数倍的sector,操作系统以页(page)为单位管理内存,一页(page)通常默认为4K,数据库的页通常设置为操作系统页的整数倍,因此索引结构的节点被设计为一个页的大小,然后利用外存的“预读取”原则,每次读取的时候,把整个节点的数据读取到内存中,然后在内存中查找。
已知内存的读取速度是外存读取I/O速度的几百倍,那么提升查找速度的关键就在于尽可能少的磁盘I/O,那么可以知道,每个节点中的key个数越多,那么树的高度越小,需要I/O的次数越少,因此一般来说B+Tree比BTree更快,因为B+Tree的非叶节点中不存储data,就可以存储更多的key。
带顺序索引的B+Tree
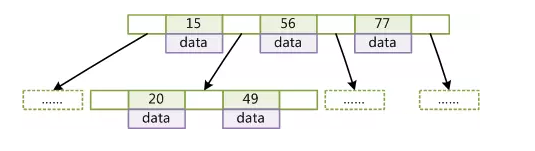
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。
在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,不用从头再查询一次,极大提到了区间查询效率。
聚簇索引和非聚簇索引
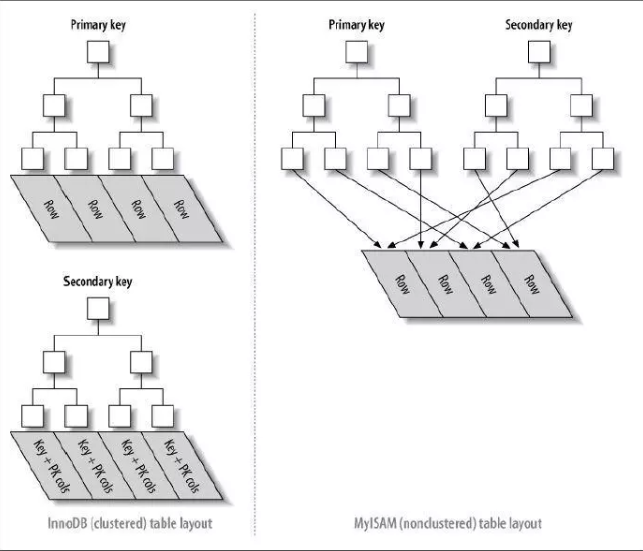
MySQL中最常见的两种存储引擎分别是MyISAM和InnoDB,分别实现了非聚簇索引和聚簇索引。
前段时间看到一个问题:“你知道为什么InnoDB非主键索引普遍比主键索引要慢吗?”答案是InnoDB使用了聚簇索引,主键索引主需要查询一次,而非主键索引需要查询两次。
为什么非主键索引需要查询两次呢?且看接下来的内容。
主索引与辅助索引
首先介绍一下基础的概念。在索引的分类中,我们可以按照索引的键是否为主键来分为“主索引”和“辅助索引”,使用主键键值建立的索引称为“主索引”,其它的称为“辅助索引”。因此主索引只能有一个,辅助索引可以有很多个。
为什么需要用到辅助索引?因为前面我们介绍了,查询语句如果想要使用索引,是需要满足最左匹配原则的。有时候我们的查询并不会使用到主键列,所以需要在其它列建立索引,即辅助索引。
非聚簇索引
非聚簇索引的主索引和辅助索引几乎是一样的,只是主索引不允许重复,不允许空值,他们的叶子结点的key都存储指向键值对应的数据的物理地址。
非聚簇索引的数据表和索引表是分开存储的。非聚簇索引中的数据是根据数据的插入顺序保存。因此非聚簇索引更适合单个数据的查询。插入顺序不受键值影响。
聚簇索引
聚簇索引的主索引的叶子结点存储的是键值对应的数据本身,辅助索引的叶子结点存储的是键值对应的数据的主键键值。因此主键的值长度越小越好,类型越简单越好。
聚簇索引的数据和主键索引存储在一起。
聚簇索引的数据是根据主键的顺序保存。因此适合按主键索引的区间查找,可以有更少的磁盘I/O,加快查询速度。但是也是因为这个原因,聚簇索引的插入顺序最好按照主键单调的顺序插入,否则会频繁的引起页分裂(BTree插入时的一个操作),严重影响性能。
在InnoDB中,如果只需要查找索引的列,就尽量不要加入其它的列,这样会提高查询效率。
聚簇索引与非聚簇索引的区别:
对于很多数据库的索引原理的分析还有查找判断方案还有很多细节的东西,鉴于实际问题比较多,可以加QQ:647617935 进行交流

- MySql 缓存查询原理与缓存监控 和 索引监控
MySql缓存查询原理与缓存监控 And 索引监控 by:授客 QQ:1033553122 查询缓存 1.查询缓存操作原理 mysql执行查询语句之前,把查询语句同查询缓存中的语句进行比较,且是按字节 ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- 【转】由浅入深探究mysql索引结构原理、性能分析与优化
摘要: 第一部分:基础知识 第二部分:MYISAM和INNODB索引结构 1.简单介绍B-tree B+ tree树 2.MyisAM索引结构 3.Annode索引结构 4.MyisAM索引与Inno ...
- 重新学习MySQL数据库4:Mysql索引实现原理
重新学习Mysql数据库4:Mysql索引实现原理 MySQL索引类型 (https://www.cnblogs.com/luyucheng/p/6289714.html) 一.简介 MySQL目前主 ...
- MySQL索引的原理,B+树、聚集索引和二级索引
MySQL索引的原理,B+树.聚集索引和二级索引的结构分析 一.索引类型 1.1 B树 1.2 B+树 1.3 哈希索引 1.4 聚集索引(clusterd index) 1.5 二级索引(secon ...
- MySQL——索引实现原理
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式. MyISAM索引实现 MyISAM引擎使用B+Tr ...
- mysql索引工作原理、分类
一.概述 在mysql中,索引(index)又叫键(key),它是存储引擎用于快速找到所需记录的一种数据结构.在越来越大的表中,索引是对查询性能优化最有效的手段,索引对性能影响非常关键.另外,mysq ...
- 重新学习Mysql数据库4:Mysql索引实现原理和相关数据结构算法
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
- MySQL索引结构原理分析
我们在学习MySQL的时候经常会听到索引这个词,大概也知道这是什么,但是深究下去又说不出什么道道来.下面将会比较全面的介绍一下关于索引! 1 索引是什么? 这里用百度百科的一句话来说,在关系数据库中, ...
随机推荐
- Spring源码学习笔记之bean标签属性介绍及作用
传统的Spring项目, xml 配置bean在代码中是经常遇到, 那么在配置bean的时候,这些属性的作用是什么呢? 虽然说现在boot项目兴起,基于xml配置的少了很多, 但是如果能够了解这些标签 ...
- HTML5学习第二天!
学习了一天,然后整理内容到现在,感觉昨天的学习效率有点差,哎! 感受尽在代码中,布局真的脑壳疼,仅仅只整理了CSS中的list: <!DOCTYPE html> <html> ...
- 2017 CCPC秦皇岛 E题 String of CCPC
BaoBao has just found a string of length consisting of 'C' and 'P' in his pocket. As a big fan of ...
- Happy Birthday! 今天我 1 周岁生日啦!
2018.09.28,我第 1 天分享文章. 2019.09.28,我连续分享的第 365 天. 今天我 1 周岁啦! 生日意味着一个新的开端, 意味着重新把握生活的机会. 新的一岁,从新头像开始 愿 ...
- 利用PyCharm操作Github:仓库新建、更新,代码回滚
Github是目前世界上最流行的代码存储和分享平台,而PyCharm是Python圈中最流行的IDE,它很好地支持了Git操作.本文将会介绍如何利用PyCharm来连接Github,同时演示Git ...
- 建议2:注意Javascript数据类型的特殊性---(2)慎用JavaScript类型自动转换
在JavaScript中能够自动转换变量的数据类型,这种转换是一种隐性行为.在自动转换数据类型时,JavaScript一般遵循:如果某个类型的值被用于需要其它类型的值的环境中,JavaScript就自 ...
- 2016/11/10 kettle概述
ETL(Extract-Transform-Load,即抽取,转换,加载),数据仓库技术,是用来处理将数据从来源(以前做的项目)经过抽取,转换,加载到达目的端(正在做的项目)的过程.也就是新的项目需要 ...
- .NET Core依赖注入集成Dynamic Proxy
在<Castle DynamicProxy基本用法>中介绍了如何将DP与Autofac集成使用,而 .NET Core有自己的依赖注入容器,在不依赖第三方容器的基础上,如何实现动态代理就成 ...
- Python批量更新模块的方法【面试必学】
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:ranchlin 小编的环境为win10+python 3. ...
- 微信小程序 存储数据到本地以及本地获取数据
1.wx存储数据到本地以及本地获取数据 存到本地就是存到你的手机 wx.setStorageSync与wx.setStorage 1.1 wx.setStorageSync(string key, a ...