Redis集群模式下的redis-py-cluster方式读写测试
与MySQL主从复制,从节点可以分担部分读压力不一样,甚至可以增加slave或者slave的slave来分担读压力,Redis集群中的从节点,默认是不分担读请求的,从节点只作为主节点的备份,仅负责故障转移。
如果是主节点读写压力过大,可以通过增加集群节点数量的方式来分担压力。
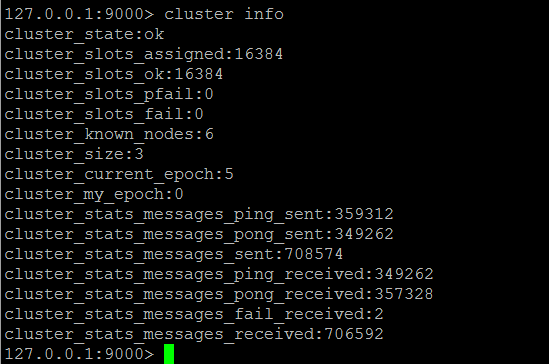
以下简单测试Redis集群读写时候的节点相应情况,节点集群关系如下,三个主节点组成集群,分别对应三个从节点



往集群中写入10W条“字符串类型”的测试数据
#!/usr/bin/env python3
import time
from time import ctime,sleep
from rediscluster import StrictRedisCluster startup_nodes = [
{"host":"127.0.0.1", "port":9000},
{"host":"127.0.0.1", "port":9001},
{"host":"127.0.0.1", "port":9002},
{"host":"127.0.0.1", "port":9003},
{"host":"127.0.0.1", "port":9004},
{"host":"127.0.0.1", "port":9005}
]
redis_conn= StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True) for i in range(0, 100000):
try:
redis_conn.set('name'+str(i),str(i)
except:
print("connect to redis cluster error")
#time.sleep(2)
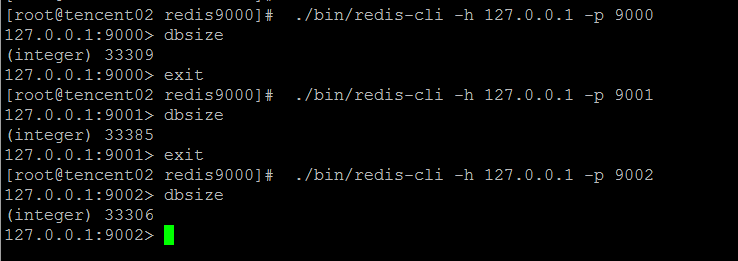
10W个key值基本上均匀地落在三个节点上
连续读数据测试,同时观察某一个主从节点的负载
#!/usr/bin/env python3
import time
from time import ctime,sleep
from rediscluster import StrictRedisCluster startup_nodes = [
{"host":"127.0.0.1", "port":9000},
{"host":"127.0.0.1", "port":9001},
{"host":"127.0.0.1", "port":9002},
{"host":"127.0.0.1", "port":9003},
{"host":"127.0.0.1", "port":9004},
{"host":"127.0.0.1", "port":9005}
]
redis_conn= StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True) for i in range(0, 100000):
try:
redis_conn.get('name'+str(i))
except:
print("connect to redis cluster error")
time.sleep(2)
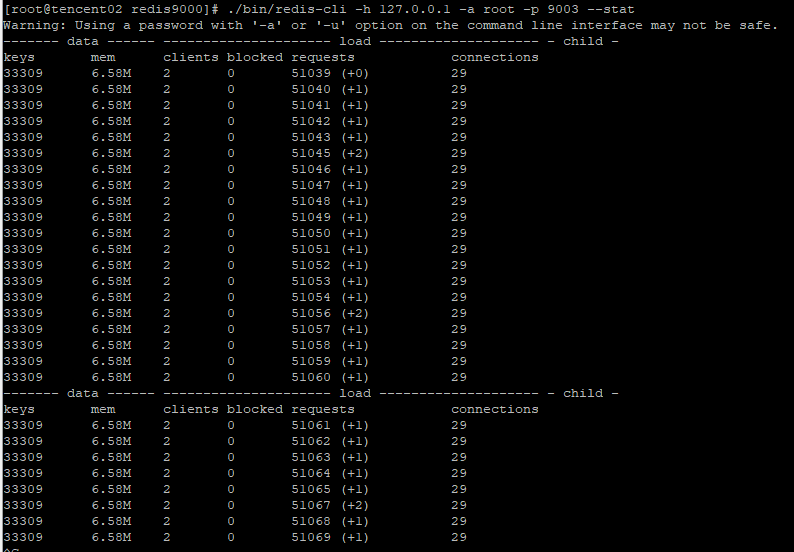
这里以9000和9003集群中的一对主从节点为例,当查询发起时,同时观察这两个节点的负载,
可以发现主节点9000负责处理定位到当前节点的请求,与此同时,而对应的从节点9003则没有处理请求信息。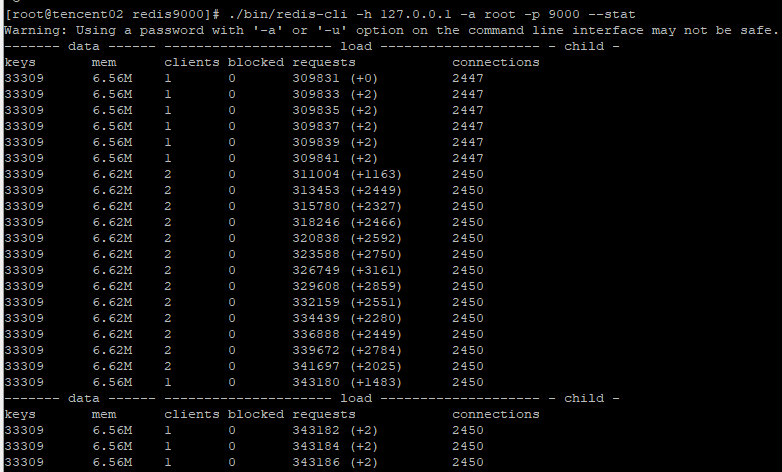
Redis集群中,默认情况下,查询是根据key值的slot信息找到其对应的主节点,然后进行查询,而不会在从节点上发起查询

使用readonly命令打开客户端连接只读状态,则从节点可以接受读请求(当然在slave节点上读,因为复制延迟造成的问题另说)
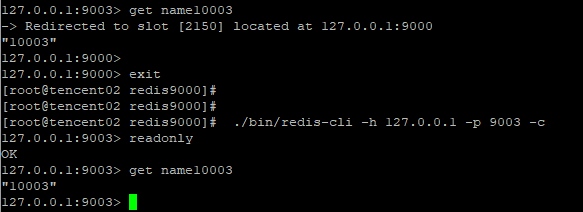
根据https://redis-py-cluster.readthedocs.io/en/master/readonly-mode.html中的说明,
You can overcome this limitation [for scaling read with READONLY mode](http://redis.io/topics/cluster-spec#scaling-reads-using-slave-nodes).
redis-py-cluster also implements this mode. You can access slave by passing readonly_mode=True to StrictRedisCluster (or RedisCluster) constructor.
通过以readonly_mode=True的方式连接至集群,重复一下测试,发现从节点依然没有处理读请求
#!/usr/bin/env python3
import time
from time import ctime,sleep
from rediscluster import StrictRedisCluster startup_nodes = [
{"host":"127.0.0.1", "port":9000},
{"host":"127.0.0.1", "port":9001},
{"host":"127.0.0.1", "port":9002},
{"host":"127.0.0.1", "port":9003},
{"host":"127.0.0.1", "port":9004},
{"host":"127.0.0.1", "port":9005}
]
redis_conn= StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True, readonly_mode=True) for i in range(0, 100000):
try:
print(redis_conn.get('name'+str(i)))
except:
print("connect to redis cluster error")
time.sleep(2000)
Redis版本为 5.0.4

不知道为什么slave节点没有请求读处理,观察Redis请求处理的stat状态,依旧重定向到了master节点,不知道是否与单机多实例有关
如果每个实例独立部署在一台机器上,readonly_mode=True的访问模式,slave节点就可以处理读请求?
ps:测试环境是在腾讯云服务器EC2上安装的Redis,如果要在本地访问,需要bind的IP为内网的IP,然后本地用公网IP访问,而不是直接bind公网IP,为此折腾了一阵子。
Redis集群模式下的redis-py-cluster方式读写测试的更多相关文章
- 7.redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗?
作者:中华石杉 面试题 redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗? 面试官心理分析 在前几年, ...
- 就publish/subscribe功能看redis集群模式下的队列技术(一)
Redis 简介 Redis 是完全开源免费的,是一个高性能的key-value数据库. Redis 与其他 key - value 缓存产品有以下三个特点: Redis支持数据的持久化,可以将内存中 ...
- 【Redis集群原理专题】分析一下相关的Redis集群模式下的脑裂问题!
技术格言 世界上并没有完美的程序,但是我们并不因此而沮丧,因为写程序就是一个不断追求完美的过程. 什么是脑裂 字面含义 首先,脑裂从字面上理解就是脑袋裂开了,就是思想分家了,就是有了两个山头,就是有了 ...
- 深入剖析Redis系列: Redis集群模式搭建与原理详解
前言 在 Redis 3.0 之前,使用 哨兵(sentinel)机制来监控各个节点之间的状态.Redis Cluster 是 Redis 的 分布式解决方案,在 3.0 版本正式推出,有效地解决了 ...
- Redis集群模式介绍
前言: 一.为什么要使用redis 1,解决应用服务器的cpu和内存压力 2,减少io的读操作,减轻io的压力(内存中读取) 3,关系型数据库扩展性,不强,难以改变表的结构 二.优点 1,nosql数 ...
- 突破Java面试-Redis集群模式的原理
1 面试题 Redis集群模式的工作原理说一下?在集群模式下,key是如何寻址的?寻址都有哪些算法?了解一致性hash吗? 2 考点分析 Redis不断在发展-Redis cluster集群模式,可以 ...
- Redis集群模式之分布式集群模式
前言 Redis集群模式主要有2种: 主从集群 分布式集群. 前者主要是为了高可用或是读写分离,后者为了更好的存储数据,负载均衡. 本文主要讲解主从集群.本章主要讲解后一半部分,Redis集群. 与本 ...
- Springboot2.x集成Redis集群模式
Springboot2.x集成Redis集群模式 说明 Redis集群模式是Redis高可用方案的一种实现方式,通过集群模式可以实现Redis数据多处存储,以及自动的故障转移.如果想了解更多集群模式的 ...
- 单个机器部署redis集群模式(一键部署脚本)
一.检查机器是否安装gcc.unzip.wget 二.部署模式 #模式1: 将所有主从节点以及sentinel节点部署在同一台机器上 #模式2: 将一个数据节点和一个sentinel节点部署在一台机器 ...
随机推荐
- sass 安装过程中的坑
1,需要在项目中使用sass/scss 功能需要先在项目中安装,安装方法: cnpm install node-sass --save-dev //安装node-sass cnpm install s ...
- 大数据之Linux网卡配置
当你安装好一台Linux之后,第一步自然是配置网卡,让你的Linux上网. 配置网卡大多数有两种模式,一种是桥接,一种是NAT 首先讲一下桥接网卡的上网原理,他是等同于在你现有的网络环境上直接现加一台 ...
- Create an Embedded Framework in Xcode with Swift
转自:http://zappdesigntemplates.com/create-an-embedded-framework-in-xcode-with-swift/ Post Series: Cre ...
- Day 02 计算机的基本组成及工作原理
目录 计算机的构成 CPU 控制器 运算器 存储器 内存 外存 I/O (input & output) 输入设备 输出设备 什么是编程语言 什么是编程 为什么要编程 多核CPU 32位和64 ...
- 【JS】307- 复习 Object.assign 原理及其实现
点击上方"前端自习课"关注,学习起来~ }let b = { name: "muyiy", book: { title: " ...
- Spring 学习,看松哥这一篇万余字干货就够了!
1. Spring 简介 我们常说的 Spring 实际上是指 Spring Framework,而 Spring Framework 只是 Spring 家族中的一个分支而已.那么 Spring 家 ...
- JS中&&和||的理解
运算符可以从三个不同的层次进行理解. 第一层理解 当操作数都是布尔值时,"&&"对两个值执行布尔与(AND)操作. 复制代码代码如下: x==0 && ...
- Scala函数式编程(四)函数式的数据结构 下
前情提要 Scala函数式编程指南(一) 函数式思想介绍 scala函数式编程(二) scala基础语法介绍 Scala函数式编程(三) scala集合和函数 Scala函数式编程(四)函数式的数据结 ...
- 更新Preloader与uboot
1.用bsp-editor 产生Preloader 参考https://rocketboards.org/foswiki/Documentation/AVGSRD160Preloader 根据QSYS ...
- java设计模式(二)单例模式,一生只爱一人,只争一朝一夕
单例模式:保证一个类在内存中的对象唯一,有且仅能实例化一次.(如多个代码块需要读取配置文件,or开启事务,orjdbc读取数据源就是个经典例子)参考:吟啸且徐行 实现步骤: 私有构造方法.保证唯一的 ...