nltk的安装和简单使用
使用python进行自然语言处理,有一些第三方库供大家使用:
·NLTK(Python自然语言工具包)用于诸如标记化、词形还原、词干化、解析、POS标注等任务。该库具有几乎所有NLP任务的工具。
·Spacy是NLTK的主要竞争对手。这两个库可用于相同的任务。
·Scikit-learn为机器学习提供了一个大型库。此外还提供了用于文本预处理的工具。
·Gensim是一个主题和向量空间建模、文档集合相似性的工具包。
·Pattern库的一般任务是充当Web挖掘模块。因此,它仅支持自然语言处理(NLP)作为辅助任务。
·Polyglot是自然语言处理(NLP)的另一个Python工具包。它不是很受欢迎,但也可以用于各种NLP任务。
先由nltk入手学习。
1. NLTK安装
简单来说还是跟python其他第三方库的安装方式一样,直接在命令行运行:pip install nltk
2. 运行不起来?
当你安装完成后,想要试试下面的代码对一段英文文本进行简单的切分:
import nltk
text=nltk.word_tokenize("PierreVinken , 59 years old , will join as a nonexecutive director on Nov. 29 .")
print(text)
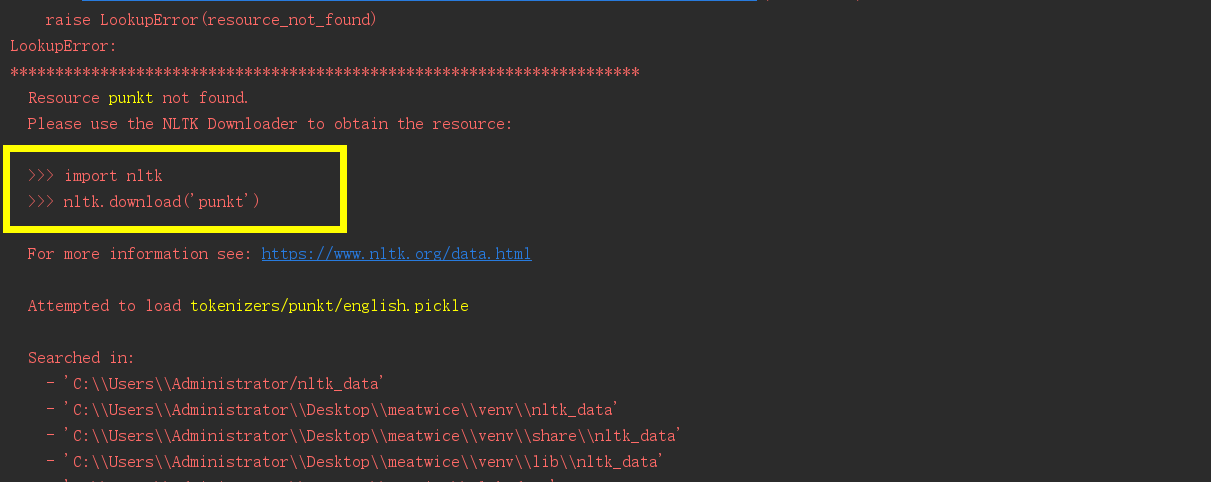
运行结果, 报错如下:
...
raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource punkt not found.
Please use the NLTK Downloader to obtain the resource: >>> import nltk
>>> nltk.download('punkt') For more information see: https://www.nltk.org/data.html Attempted to load tokenizers/punkt/english.pickle Searched in:
- 'C:\\Users\\Administrator/nltk_data'
- 'C:\\Users\\Administrator\\Desktop\\meatwice\\venv\\nltk_data'
- 'C:\\Users\\Administrator\\Desktop\\meatwice\\venv\\share\\nltk_data'
- 'C:\\Users\\Administrator\\Desktop\\meatwice\\venv\\lib\\nltk_data'
- 'C:\\Users\\Administrator\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
- ''
**********************************************************************
3. 解决方法:
不用着急,解决方法在异常中已经给出来了
命令行进入python交互模式,运行如下:
import nltk
nltk.download()
然后会弹出一个窗口,点击models,找到punkt,双击进行下载即可。

然后运行开始的那段python代码,对文本进行切分:
import nltk
text=nltk.word_tokenize("PierreVinken , 59 years old , will join as a nonexecutive director on Nov. 29 .")
print(text)
结果如下,不会报错:

4. nltk的简单使用方法。
上面看了一个简单的nltk的使用示例,下面来具体看看其使用方法。
4.1 将文本切分为语句, sent_tokenize()
from nltk.tokenize import sent_tokenize
text=" Welcome readers. I hope you find it interesting. Please do reply."
print(sent_tokenize(text))
从标点处开始切分,结果:

4.2 将句子切分为单词, word_tokenize()
from nltk.tokenize import word_tokenize
text=" Welcome readers. I hope you find it interesting. Please do reply."
print(word_tokenize(text))
切分成单个的单词,运行结果:

4.3.1 使用 TreebankWordTokenizer 进行切分
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
print(tokenizer.tokenize("What is Love? I know this question exists in each human being's mind including myse\
lf. If not it is still waiting to be discovered deeply in your heart. What do I think of love? For me, I belie\
ve love is a priceless diamond, because a diamond has thousands of reflections, and each reflection represent\
s a meaning of love."))
也是将语句切分成单词,运行结果:

nltk的安装和简单使用的更多相关文章
- NLTK的安装与简单测试
1.NLTK简介 Natural Language Toolkit,自然语言处理工具包,在NLP领域中,最常使用的一个Python库.NLTK是一个开源的项目,包含:Python模块,数据集和教程,用 ...
- (转)python requests的安装与简单运用
requests是python的一个HTTP客户端库,跟urllib,urllib2类似,那为什么要用requests而不用urllib2呢?官方文档中是这样说明的: python的标准库urllib ...
- MongoDB在Windows下安装、Shell客户端的使用、Bson扩充的数据类型、MongoVUE可视化工具安装和简单使用、Robomongo可视化工具(2)
一.Windows 下载安装 1.去http://www.mongodb.org/downloads下载,mongodb默认安装在C:\Program Files\MongoDB目录下,到F:\Off ...
- python requests的安装与简单运用
requests是python的一个HTTP客户端库,跟urllib,urllib2类似,那为什么要用requests而不用urllib2呢?官方文档中是这样说明的: python的标准库urllib ...
- memcache的windows下的安装和简单使用
原文:memcache的windows下的安装和简单使用 memcache是为了解决网站访问量大,数据库压力倍增的解决方案之一,由于其简单实用,很多站点现在都在使用memcache,但是memcach ...
- 【RabbitMQ】RabbitMQ在Windows的安装和简单的使用
版本说明 使用当前版本:3.5.4 安装与启动 在官网上下载其Server二进制安装包,在Windows上的安装时简单的,与一般软件没什么区别. 安装前会提示你,还需要安装Erlang,并打开下载页面 ...
- Thrift的安装和简单演示样例
本文仅仅是简单的解说Thrift开源框架的安装和简单使用演示样例.对于具体的解说,后面在进行阐述. Thrift简述 ...
- libmemcached安装及简单例子
libmemcached安装及简单例子 1.下载安装libmemcached $ wget http://launchpad.net/libmemcached/1.0/0.44/+download/ ...
- [hadoop系列]Pig的安装和简单演示样例
inkfish原创,请勿商业性质转载,转载请注明来源(http://blog.csdn.net/inkfish ).(来源:http://blog.csdn.net/inkfish) Pig是Yaho ...
随机推荐
- C#语法--委托,架构的血液
委托的定义 什么是委托? 委托实际上是一种类型,是一种引用类型. 微软用delegate关键字来声明委托,delegate与int,string,double等关键字一样.都是声明用的. 下面先看下声 ...
- Python文本转化语音模块大比拼,看看青铜与王者的差别!
文本转语音 如果把Python比喻成游戏中的一个英雄,你觉得它是谁?对于Dota老玩家来说,我会想到钢琴手卡尔!感觉Python和卡尔一样,除了生孩子什么都可以做的角色.日常生活中,我们会涉及到很多语 ...
- springboot执行延时任务-DelayQueue的使用
DelayQueue简介 在很多场景我们需要用到延时任务,比如给客户异步转账操作超时后发通知告知用户,还有客户下单后多长时间内没支付则取消订单等等,这些都可以使用延时任务来实现. jdk中DelayQ ...
- luogu P1976 鸡蛋饼
题目背景 Czyzoiers 都想知道小 x 为什么对鸡蛋饼情有独钟.经过一番逼问,小 x 道出了实情:因为他喜欢圆. 题目描述 最近小 x 又发现了一个关于圆的有趣的问题:在圆上有 2N 个不同的点 ...
- luogu P5002 专心OI - 找祖先
题目描述 这个游戏会给出你一棵树,这棵树有NN个节点,根结点是RR,系统会选中MM个点P_1,P_2...P_MP 1 ,P 2 ...P M ,要Imakf回答有多少组点对(u_i,v_ ...
- 数学工具(三)scipy中的优化方法
给定一个多维函数,如何求解全局最优? 文章包括: 1.全局最优的求解:暴力方法 2.全局最优的求解:fmin函数 3.凸优化 函数的曲面图 import numpy as np import matp ...
- 从零开始的openGL——四、纹理贴图与n次B样条曲线
前言 在上篇文章中,介绍了如何加载绘制模型以及鼠标交互的实现,并且遗留了个问题,就是没有模型表面没有纹理,看起来很丑.这篇文章将介绍如何贴纹理,以及曲线的绘制. 纹理贴图 纹理加载 既然是贴图,那首先 ...
- Win32_Processor CPU 参数说明
转载自:https://blog.csdn.net/yeyingss/article/details/49385421 AddressWidth --在32位操作系统,该值是32,在64位操作系统是 ...
- Vue-router的实现原理
参考博客:https://www.jianshu.com/p/4295aec31302 参考博客:https://segmentfault.com/a/1190000015123061
- 11个点让你的Spring Boot启动更快
前言 使用的是 OpenJDK 11. java --version openjdk 11.0.1 2018-10-16 OpenJDK Runtime Environment 18.9 (build ...