把项目中那些恶心的无处存储的大块数据都丢到FastDFS之快速搭建
在我们开发项目的时候,经常会遇到大块数据的问题(2M-100M),比如说保存报表中1w个人的ID号,他就像一个肿瘤一样,存储在服务器哪里都
觉得恶心,放在redis,mongodb中吧,一下子你就会收到报警,因为内存满了。。。放在mysql吧???你还得建立一个text字段,和一些小字段混在一起,
还是有点恶心,还得单独拆出来,还得怕有些sql不规范的人挺喜欢select * 的,这速度挺恶心的呀。。。直接放到硬盘吧,没扩展性,你1T大小的硬盘又能
怎样,照样撑爆你,放在hadoop里面吧,对.net程序员来说,没有这个缘分,好不容易微软有一个.net hadoop sdk,说放弃就放弃了,兼具以上各种特性,
最后目光只能落到FastDFS上了。
一: FastDFS
fastDFS的本意是一个分布式的文件系统,所以大家可以上传各种小文件,包括这篇和大家说到的那些一坨一坨的数据,同样你也可以认为是一些小文件,
下面我画一下它的大概架构图:
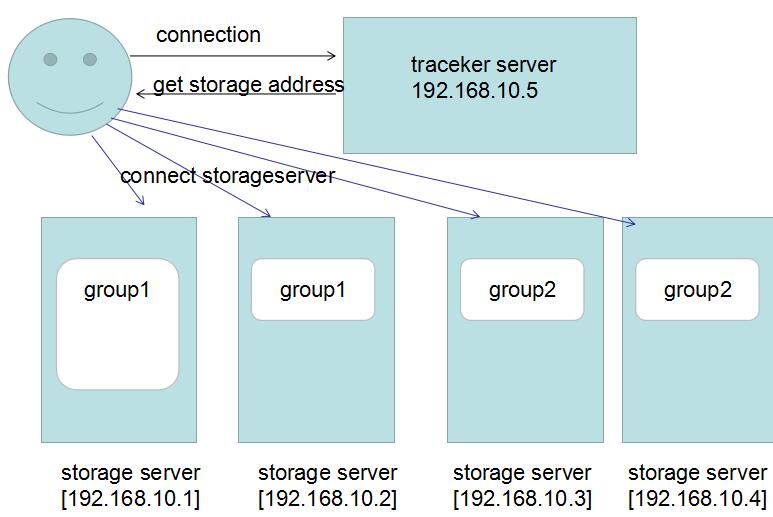
我来解释一下:
1. fastDFS是按照Group的形式对file进行分组存储的,这里的group1你可以理解成C盘,group2理解成D盘,所有的数据都是在Group来划分的。
2. 为了提高读取性能和热备份,我们把group1放到了两台机器上,大概可能觉得有点浪费,对吧,事实就是这样。
3. 为了提高扩展性,因为单机是有存储上限的,这时候你可以再新建一个group2,也就是D盘,放到另外机器上,这样你就扩容了,对吧。
4. trackerServer主要用来保存group和storage的一些状态信息,主要和client端进行交互,返回正确的storeage server地址,这个和hadoop的
namenode其实是同一个角色的。
5. 这里要注意的一个地方就是,client端在存储file的时候,需要告诉trackerserver,你需要存储到哪一个group中,比如group1还是group2?
二:下载安装【CentOS】
为了方便测试,这里我部署到一台CentOS了。
1. 下载fastDFS基础包:https://github.com/happyfish100/libfastcommon/releases
2. 然后下载fast源码包:https://github.com/happyfish100/fastdfs/releases
3. wget之后,先把libfastcommon给安装一下
tar -xzvf V1.0.36
cd libfastcommon-1.0.
./make.sh && ./make.sh install
再把fastdfs安装一下。
tar -xzvf V5.
cd fastdfs-5.11
./make.sh &&./make.sh install
这样的话,我们的fast就算安装好了,因为是默认安装,所以配置文件是在 /etc/fdfs目录下,启动服务在/etc/init.d下。
[root@localhost ~]# cd /etc/fdfs
[root@localhost fdfs]# ls
client.conf client.conf.sample storage.conf.sample storage_ids.conf.sample tracker.conf.sample [root@localhost fdfs]# cd /etc/init.d
[root@localhost init.d]# ls
fdfs_storaged fdfs_trackerd functions netconsole network README
[root@localhost init.d]#
然后再把两个storage.conf.sample 和 tracker.conf.sample中copy出我们需要配置的文件。
[root@localhost fdfs]# cp storage.conf.sample storage.conf
[root@localhost fdfs]# cp tracker.conf.sample tracker.conf
[root@localhost fdfs]# ls
client.conf client.conf.sample storage.conf storage.conf.sample storage_ids.conf.sample tracker.conf tracker.conf.sample
[root@localhost fdfs]#
4. tracker.conf 配置
这个配置文件,主要是配置里面的base_path。
# the base path to store data and log files
base_path=/usr/fast/fastdfs-5.11/data/tracker
指定完路径之后,我们创建一个data文件夹和tracker文件夹。
5. storage.conf 配置
这个配置文件,我们主要配置三样东西。
1. 本storage服务器的groupname,大家看过架构图应该也明白了,对吧。
2. 为了提高磁盘读写,可以指定本groupname的file存储在哪些磁盘上。
3. 指定和哪一台trackerserver进行交互。
# the name of the group this storage server belongs to
#
# comment or remove this item for fetching from tracker server,
# in this case, use_storage_id must set to true in tracker.conf,
# and storage_ids.conf must be configed correctly.
group_name=group1 # the base path to store data and log files
base_path=/usr/fast/fastdfs-5.11/data/storage # path(disk or mount point) count, default value is
store_path_count= # store_path#, based , if store_path0 not exists, it's value is base_path
# the paths must be exist
store_path0=/usr/fast/fastdfs-5.11/data/storage/0
#store_path1=/home/yuqing/fastdfs2 # tracker_server can ocur more than once, and tracker_server format is
# "host:port", host can be hostname or ip address
tracker_server=192.168.23.152:
然后在data目录下创建storage和0文件夹
6.启动 FastDFS,可以看到22122的端口已经启动了,说明搭建成功
[root@localhost ~]# /etc/init.d/fdfs_trackerd start
Starting fdfs_trackerd (via systemctl): [ OK ]
[root@localhost ~]# /etc/init.d/fdfs_storaged start
Starting fdfs_storaged (via systemctl): [ OK ]
[root@localhost ]# netstat -tlnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0.0.0.0:22122 0.0.0.0:* LISTEN /fdfs_trackerd
tcp 192.168.122.1: 0.0.0.0:* LISTEN /dnsmasq
tcp 0.0.0.0: 0.0.0.0:* LISTEN /sshd
tcp 127.0.0.1: 0.0.0.0:* LISTEN /cupsd
tcp 0.0.0.0:23000 0.0.0.0:* LISTEN /fdfs_storaged
tcp 127.0.0.1: 0.0.0.0:* LISTEN /master
tcp6 ::: :::* LISTEN /sshd
tcp6 ::: :::* LISTEN /cupsd
tcp6 ::: :::* LISTEN /master
[root@localhost ]#
三:使用C#客户端
在github上有一个C#的客户端,大概可以使用一下:https://github.com/smartbooks/FastDFS.Client 或者通过nuget上搜一下:
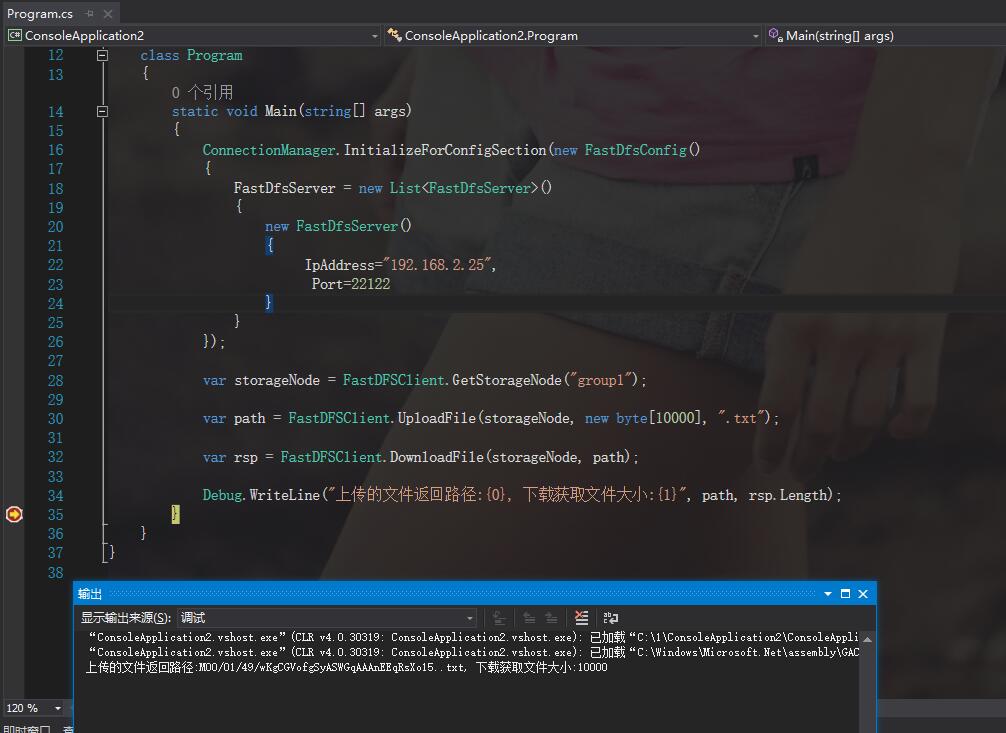
class Program
{
static void Main(string[] args)
{
ConnectionManager.InitializeForConfigSection(new FastDfsConfig()
{
FastDfsServer = new List<FastDfsServer>()
{
new FastDfsServer()
{
IpAddress="192.168.2.25",
Port=
}
}
}); var storageNode = FastDFSClient.GetStorageNode("group1"); var path = FastDFSClient.UploadFile(storageNode, new byte[], ".txt"); var rsp = FastDFSClient.DownloadFile(storageNode, path); Debug.WriteLine("上传的文件返回路径:{0}, 下载获取文件大小:{1}", path, rsp.Length);
}
}
好了,本篇就说这么多了,希望对你有帮助。
把项目中那些恶心的无处存储的大块数据都丢到FastDFS之快速搭建的更多相关文章
- 把项目中的那些恶心的无处存储的大块数据都丢到FastDFS之快速搭建
在我们开发项目的时候,经常会遇到大块数据的问题(2M-100M),比如说保存报表中1w个人的ID号,他就像一个肿瘤一样,存储在服务器哪里都 觉得恶心,放在redis,mongodb中吧,一下子 ...
- 一个Web项目中实现多个数据库存储数据并相互切换用过吗?
最近公司一个项目需要连接多个数据库(A和B)操作,根据不同的业务模块查询不同的数据库,因此需要改造下之前的spring-mybatis.xml配置文件以及jdbc.properties配置文件,项目后 ...
- vue项目中设置全局引入scss,使每个组件都可以使用变量
在Vue项目中使用scss,如果写了一套完整的有变量的scss文件.那么就需要全局引入,这样在每个组件中使用. 可以在mian.js全局引入,下面是使用方法. 1: 安装node-sass.sass- ...
- 在java项目中怎样利用Dom4j解析XML文件获取数据
在曾经的学习.net时常常会遇到利用配置文件来解决项目中一些须要常常变换的数据.比方数据库的连接字符串儿等.这个时候在读取配置文件的时候.我们一般会用到一个雷configuration,通过这个类来进 ...
- WebGIS项目中利用mysql控制点库进行千万条数据坐标转换时的分表分区优化方案
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1. 背景 项目中有1000万条历史案卷,为某地方坐标系数据,我们的真实 ...
- H5中使用Web Storage来存储结构化数据
在上一篇对Web Storage的介绍中,可以看到,使用Storage保存key—value对时,key.value只能是字符串,这对于简单的数据来说已经够了,但是如果需要保存更复杂的数据,比如保存类 ...
- 【spring boot】spring boot 2.0 项目中使用mysql驱动启动创建的mysql数据表,引擎是MyISAM,如何修改启动时创建数据表引擎为【spring boot 2.0】
默认创建数据表使用的引擎是MyISAM 2018-05-14 14:16:37.283 INFO 7328 --- [ restartedMain] org.hibernate.dialect.Dia ...
- Vue项目中实现tab栏和步骤条的数据联动
也就是tab栏切换步骤条随之变化 <template> <div> <!-- 面包屑导航 --> <el-breadcrumb sepa ...
- Linux 运维工作中的经典应用ansible(批量管理)Docker容器技术(环境的快速搭建)
一 Ansible自动化运维工具 Python 在运维工作中的经典应用 ansible(批量管理操作) .安装ansible(需要bese epel 2种源) wget -O /etc/yum.rep ...
随机推荐
- BZOJ_4004_[JLOI2015]装备购买_线性基
BZOJ_4004_[JLOI2015]装备购买_线性基 Description 脸哥最近在玩一款神奇的游戏,这个游戏里有 n 件装备,每件装备有 m 个属性,用向量zi(aj ,.....,am) ...
- Windows上安装配置SSH教程(2)——在Windows XP和Windows 10上安装并配置OpenSSH for Windows
知识点汇总:http://www.cnblogs.com/feipeng8848/p/8559803.html ------------------------ 安装方式有3种: (1)Windows ...
- MYSQL——数据库存储引擎!
本人安装mysql版本为:mysql Ver 14.14 Distrib 5.7.18, for Win64 (x86_64),查看mysql的版本号方式:cmd-->mysql --vers ...
- 如何删除git远程仓库项目的所有内容,重新提交所有内容
如果我们上传了一个项目到git并已经commit和push了所有内容,但是忘记搞gitignore文件, 导致一些不想加入版本控制的文件,如IDE配置文件,编译文件,部署文件等, 现在不知道怎么办了? ...
- jdk源码阅读笔记-String
本人自学java两年,有幸初入这个行业,所以功力尚浅,本着学习与交流的态度写一些学习随笔,什么错误的地方,热烈地希望园友们提出来,我们共同进步!这是我入园写的第一篇文章,写得可能会很乱. 一.什么是S ...
- 基于udp的套接字编程
一,简单明了了解udp套接字编程 客户端: #Author : Kelvin #Date : 2019/1/30 11:07 from socket import * ip_conf=("1 ...
- Java核心技术梳理-基础类库
一.引言 Oracle为Java提供了丰富的基础类库,Java 8 提供了4000多个基础类库,熟练掌握这些基础类库可以提高我们的开发效率,当然,记住所有的API是不可能也没必要的,我们可以通过API ...
- C#ComboBox控件“设置 DataSource 属性后无法修改项集合”的解决方法
在使用ComboBox控件时,遇到了重新绑定赋值出问题的情况.正常情况下,对于数据重新赋值的或者绑定数据源的时候,为了防止数据出现问题,都会先清空原来数据,所以就这样写了,但是没有相当恰恰这样写就出现 ...
- Mysql常用基础操作(备忘录)
常常忘记mysql的一些命令行操作,甚至于说,比较复杂的sql格式记不住或忘记了,也可能根本不会考虑去记,因此,做一下汇总,当下次出现恍惚时不至于去百度挨个找,有时就是记不起来,但是只要给点药引子,立 ...
- WebGL three.js学习笔记 阴影与实现物体的动画
实现物体的旋转.跳动以及场景阴影的开启与优化 本程序将创建一个场景,并实现物体的动画效果 运行的结果如图: 完整代码如下: <!DOCTYPE html> <html lang=&q ...