selenium获取百度账户cookies
【效果图】
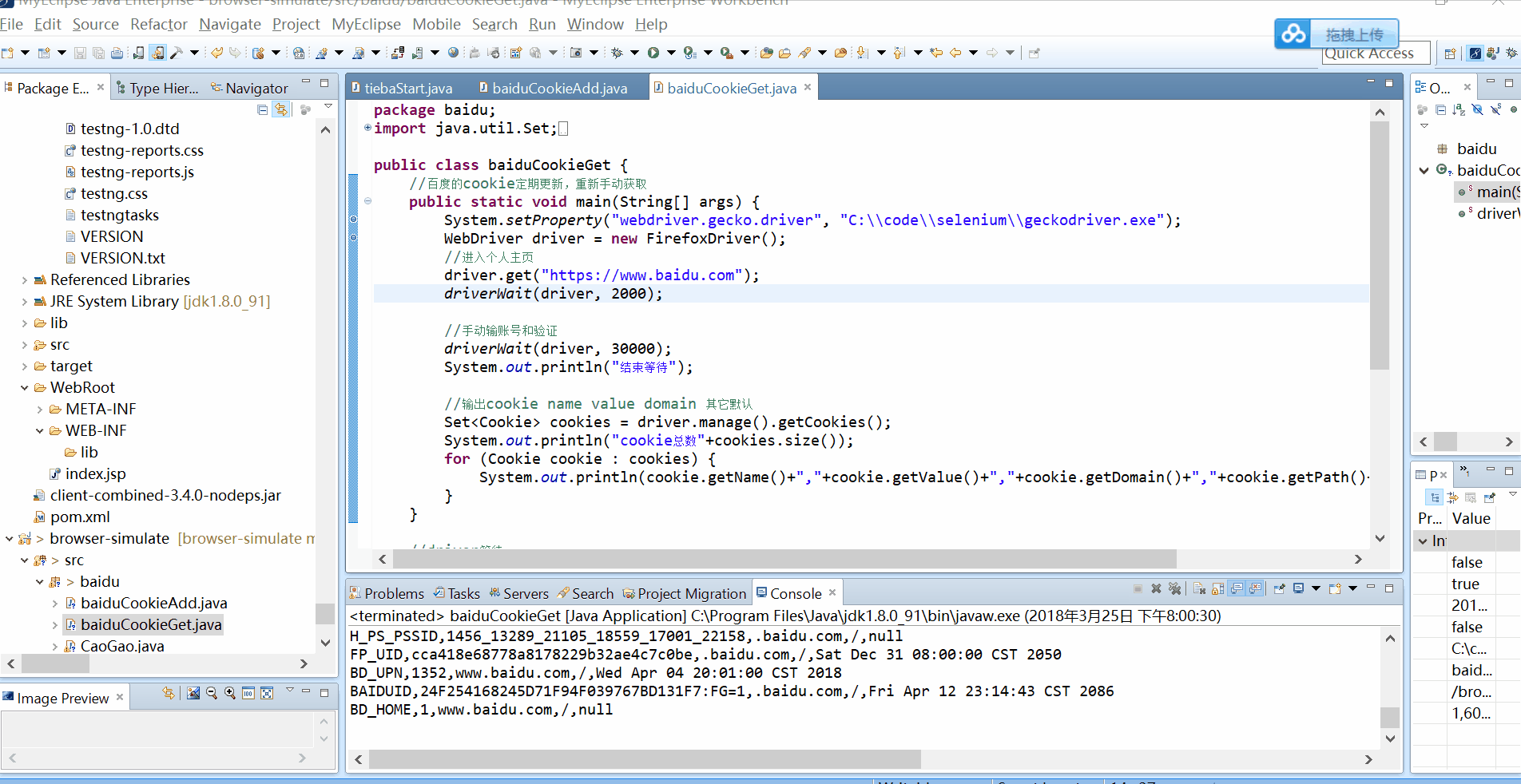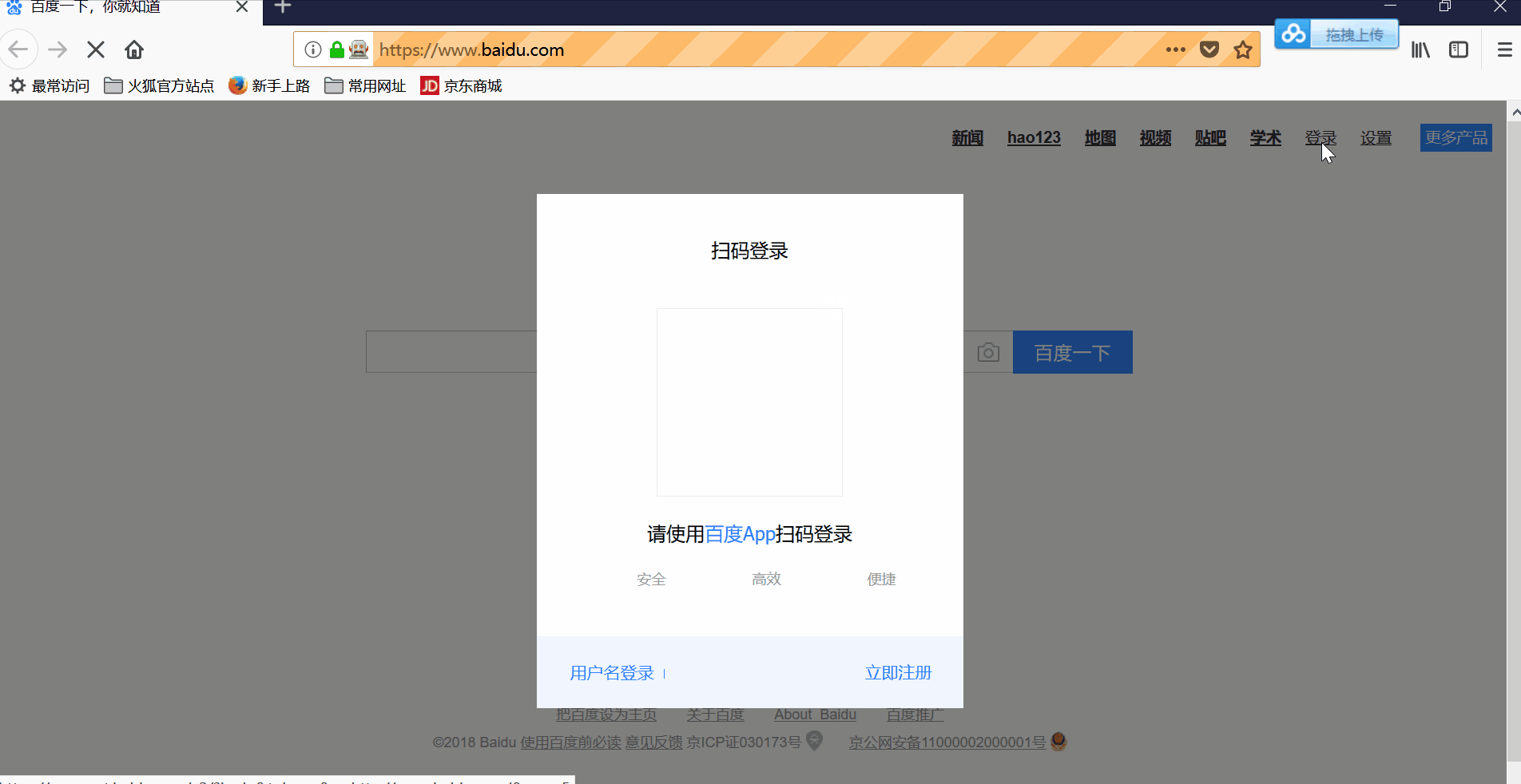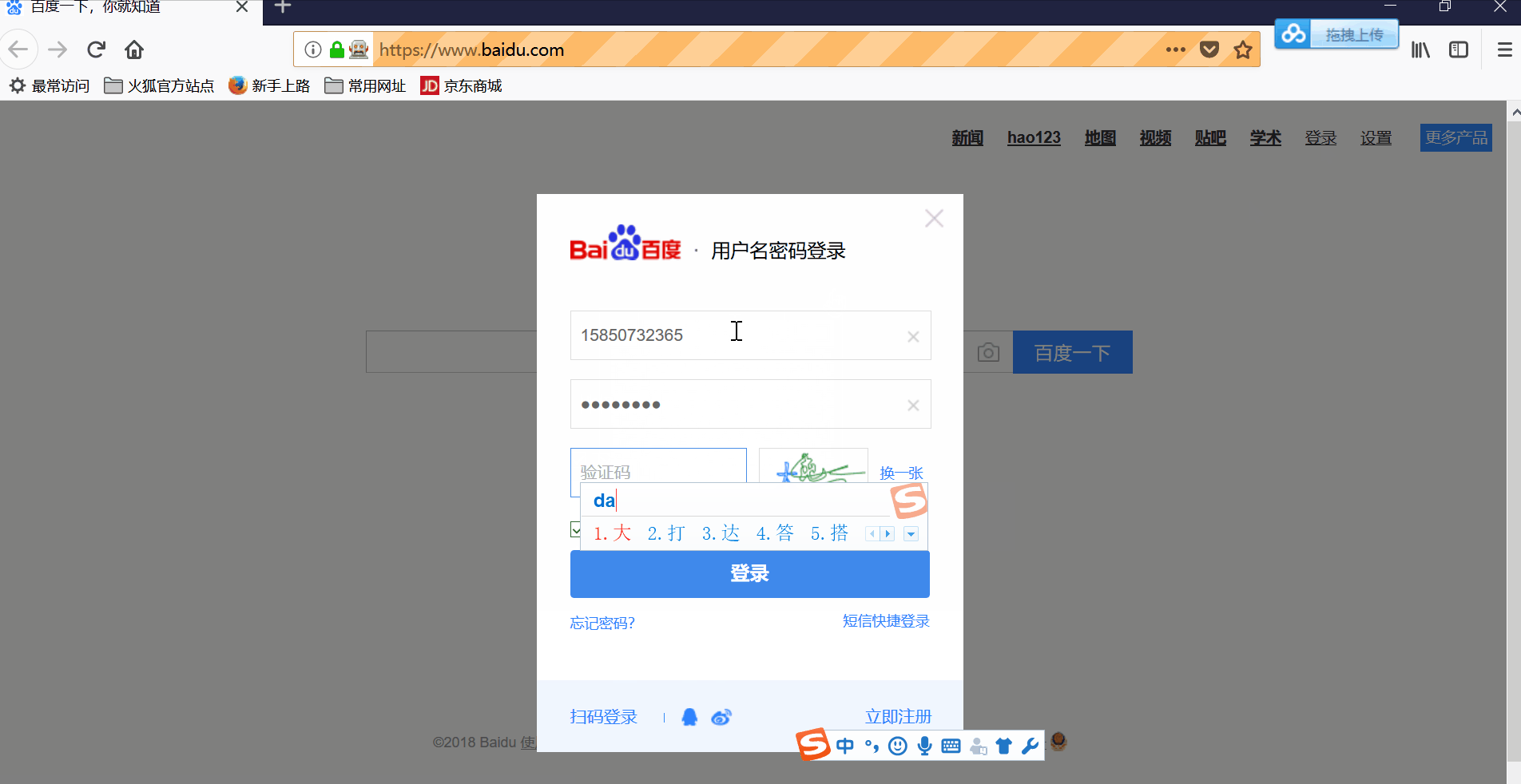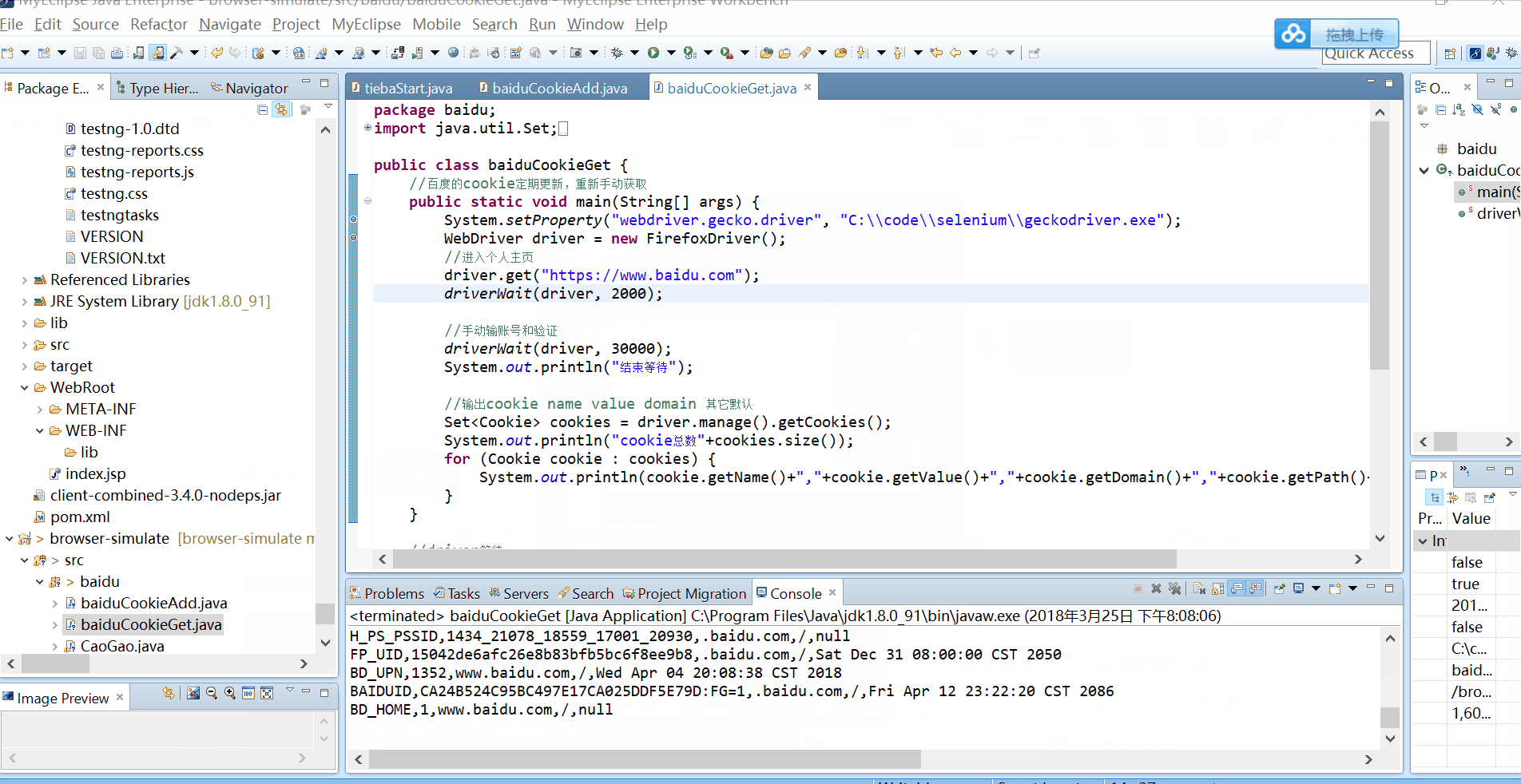
效果图最后即为获取到的cookies,百度账户的cookies首次获取,需要手动登录,之后就可以注入cookies,实现免密登录。
【代码】
public class baiduCookieGet {
//百度的cookie定期更新,重新手动获取
public static void main(String[] args) {
System.setProperty("webdriver.gecko.driver", "C:\\code\\selenium\\geckodriver.exe");
WebDriver driver = new FirefoxDriver();
//进入个人主页
driver.get("https://www.baidu.com");
driverWait(driver, 2000);
//手动输账号和验证
driverWait(driver, 30000);
System.out.println("结束等待");
//输出cookie name value domain 其它默认
Set<Cookie> cookies = driver.manage().getCookies();
System.out.println("cookie总数"+cookies.size());
for (Cookie cookie : cookies) {
System.out.println(cookie.getName()+","+cookie.getValue()+","+cookie.getDomain()+","+cookie.getPath()+","+cookie.getExpiry());
}
}
//driver等待
public static void driverWait(WebDriver driver,long time) {
try {
synchronized (driver) {
System.out.println("begin wait() ThreadName="
+ Thread.currentThread().getName());
driver.wait(time);
System.out.println(" end wait() ThreadName="
+ Thread.currentThread().getName());
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
【结束语】
获取cookies是免密登录的最重要一步,如果不能实现cookies登录,就要应付烦人的各种验证码了。
selenium获取百度账户cookies的更多相关文章
- [Python爬虫] Selenium获取百度百科旅游景点的InfoBox消息盒
前面我讲述过如何通过BeautifulSoup获取维基百科的消息盒,同样可以通过Spider获取网站内容,最近学习了Selenium+Phantomjs后,准备利用它们获取百度百科的旅游景点消息盒(I ...
- day95_11_28,selenium定位元素,cookies获取
一.selenium selenium可以将一些资源定位: # 1.find_element_by_id 根据id找 # 2.find_element_by_link_text 根据链接名字找到控件( ...
- 用selenium获取cookies
前言:由于登录反爬措施的越来越麻烦,甚至出现了12306这种看图识物的无敌验证码,我只能说,我选择死亡.这就衍生出了使用selenium来获取获取cookies. 实例:获取qq空间cookies,亲 ...
- selenium获取cookies并持久化登陆
selenium获取cookies并持久化登陆 需求背景: 这几天需要写一个接口,用来批量上传数据,最开始考虑的是 UI 自动化,然后选值的时候自动化难以判别,最终选择 接口 自动化. 然后操 ...
- 在CentOS下利用Python+selenium获取腾讯首页的今日话题。
1.安装依赖包 yum install wget firefox gcc zlib zlib-devel Xvfb 2.安装setuptools 官网地址:https://pypi.python.or ...
- selenium获取多窗口句柄并一一切换至原窗口句柄(三个窗口)
网上有很多是selenium基于python来获取两个窗口句柄与切换,本文实现用python+selenium获取多窗口句柄并一一切换至原窗口句柄(三个窗口),且在每个窗口下进行一个搜索或翻译,然后截 ...
- selenium 之百度搜索,结果列表翻页查询
selenium之百度搜索,结果列表翻页查询 by:授客 QQ:1033553122 实例:百度搜索,结果列表翻页查询 解决问题:解决selenium driver获取web页面元素时,元素过期问题 ...
- 关于阻止百度滥用cookies的想法
Chrome浏览器支持禁止指定的cookies,因此可以作为阻止百度滥用cookies的突破口,最好的方案应该是制作chrome插件(国内厂商的浏览器基本都是基于谷歌开源的 Chromium计划,基本 ...
- selenium获取多窗口句柄并一切换至原窗口句柄(三个窗口)
网上有很多是selenium基于python来获取两个窗口句柄与切换,本文实现用python+selenium获取多窗口句柄并一一切换至原窗口句柄(三个窗口),且在每个窗口下进行一个搜索或翻译,然后截 ...
随机推荐
- 输入过滤器——InputFilter
一般情况下我们通过请求体读取器InputStreamInputBuffer获取的仅仅是源数据,即未经过任何处理发送方发来的字节.但有些时候在这个读取的过程中希望做一些额外的处理,并且这些额外处理可能是 ...
- UNIX网络编程——socket概述和字节序、地址转换函数
一.什么是socket socket可以看成是用户进程与内核网络协议栈的编程接口.socket不仅可以用于本机的进程间通信,还可以用于网络上不同主机的进程间通信. socket API是一层抽象的网络 ...
- 第七天:创建WBS
- Android进阶(四)一个APP引发的思索之ArrayList的add总是添加相同的值
解决"ArrayList的add总是添加相同的值"问题 前言 最近在写一个小的Android APP,在用ArrayList的add时,总是出现添加相同值的现象.如下图所示: 错误 ...
- Maven项目中获取classpath和资源文件的路径
假设资源文件放在maven工程的 src/main/resources 资源文件夹下,源码文件放在 src/main/java/下, 那么java文件夹和resources文件夹在运行时就是cl ...
- gradle 修改生成的apk的名字
在app的module里的build.gradle文件中,在android { ...}里面加上这样一段代码,即可修改生成的apk的文件名. android.applicationVariants.a ...
- Ubuntu文件中文乱码
如图,该文件在gedit打开中文显示正常 在命令行中用vim打开,显示内容如下: 使用命令进行编码转换 iconv -f gbk -t utf8 ./SogouQ.mini > ./sougou ...
- 从JDK源码角度看java并发线程的中断
线程的定义给我们提供了并发执行多个任务的方式,大多数情况下我们会让每个任务都自行执行结束,这样能保证事务的一致性,但是有时我们希望在任务执行中取消任务,使线程停止.在java中要让线程安全.快速.可靠 ...
- TCP的ACK确认系列 — 快速确认
主要内容:TCP的快速确认.TCP_QUICKACK选项的实现. 内核版本:3.15.2 我的博客:http://blog.csdn.net/zhangskd 快速确认模式 (1) 进入快速确认模式 ...
- Linux多线程实践(1) --线程理论
线程概念 在一个程序里的一个执行路线就叫做线程(thread).更准确的定义是:线程是"一个进程内部的控制序列/指令序列"; 一切进程至少有一个执行线程; 进程 VS. 线程 ...