关于Kafka __consumer_offests的讨论
众所周知,__consumer__offsets是一个内部topic,对用户而言是透明的,除了它的数据文件以及偶尔在日志中出现这两点之外,用户一般是感觉不到这个topic的。不过我们的确知道它保存的是Kafka新版本consumer的位移信息。本文我们简单梳理一下这个内部topic(以1.0.0代码为分析对象)
一、何时被创建?
首先,我们先来看下 它是何时被创建的?__consumer_offsets创建的时机有很多种,主要包括:
- broker响应FindCoordinatorRequest请求时
- broker响应MetadataRequest显式请求__consumer_offsets元数据时
其中以第一种最为常见,而第一种时机的表现形式可能有很多,比如用户启动了一个消费者组(下称consumer group)进行消费或调用kafka-consumer-groups --describe等
二、消息种类
__consumer_offsets中保存的记录是普通的Kafka消息,只是它的格式完全由Kafka来维护,用户不能干预。严格来说,__consumer_offsets中保存三类消息,分别是:
- Consumer group组元数据消息
- Consumer group位移消息
- Tombstone消息
2.1 Consumer group组元数据消息
我们都知道__consumer_offsets是保存位移的,但实际上每个消费者组的元数据信息也保存在这个topic。这些元数据包括:
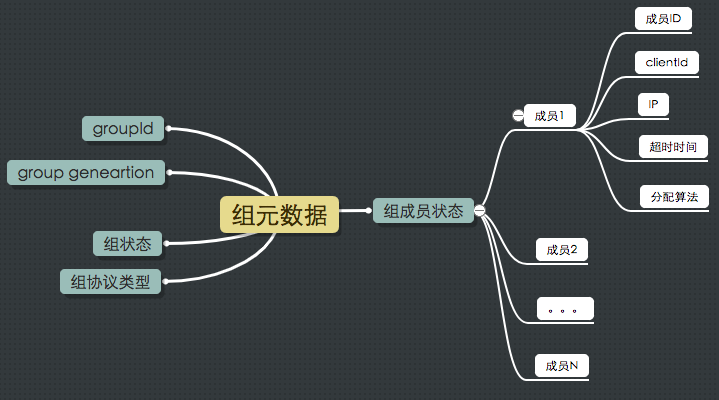
这里不详细展开组元数据各个字段的含义。我们只需要知道组元数据消息也是保存在__consumer_offsets中即可。值得一提的是, 如果用户使用standalone consumer(即consumer.assign(****)方法),那么就不会写入这类消息,毕竟我们使用的是独立的消费者,而没有使用消费者组。
这类消息的key是一个二元组,格式是【版本+groupId】,这里的版本表征这类消息的版本号,无实际用途;而value就是上图所有这些信息打包而成的字节数组。
2.2 Consumer group组位移提交消息
如果只允许说出__consumer_offsets的一个功能,那么我们就记住这个好了:__consumer_offsets保存consumer提交到Kafka的位移数据。这句话有两个要点:1. 只有当consumer group向Kafka提交位移时才会向__consumer_offsets写入这类消息。如果你的consumer压根就不提交位移,或者你将位移保存到了外部存储中(比如Apache Flink的检查点机制或老版本的Storm Kafka Spout),那么__consumer_offsets中就是无位移数据;2. 这句话中的consumer既包含consumer group也包含standalone consumer。也就是说,只要你向Kafka提交位移,不论使用哪种java consumer,它都是向__consumer_offsets写消息。
这类消息的key是一个三元组,格式是【groupId + topic + 分区号】,value则是要提交的位移信息,如下图所示:
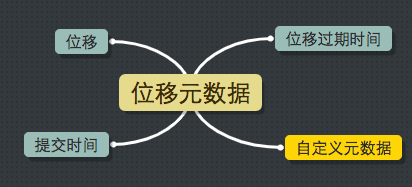
位移就是待提交的位移,提交时间是提交位移时的时间戳,而过期时间则是用户指定的过期时间。由于目前consumer代码在提交位移时并没有明确指定过期间隔,故broker端默认设置过期时间为提交时间+offsets.retention.minutes参数值,即提交1天之后自动过期。Kafka会定期扫描__consumer_offsets中的位移消息并删除掉那些过期的位移数据。
上图中还有个“自定义元数据”,实际上consumer允许用户在提交位移时指定一些特殊的自定义信息。我们不对此进行详细展开,因为java consumer根本就没有使用到它。相反地,Kafka Streams利用该字段来完成某些定制任务。
2.3 tombstone消息或Delete Mark消息
第三类消息成为tombstone消息或delete mark消息。这类消息只出现在源码中而不暴露给用户。它和第一类消息很像,key都是二元组【版本+groupId】,唯一的区别在于这类消息的消息体是null,即空消息体。何时写入这类消息?前面说过了,Kafka会定期扫描过期位移消息并删除之。一旦某个consumer group下已没有任何active成员且所有的位移数据都已被删除时,Kafka会将该group的状态置为Dead并向__consumer__offsets对应分区写入tombstone消息,表明要彻底删除这个group的信息。简单来说,这类消息就是用于彻底删除group信息的。
三、何时写入?
第一类消息是在组rebalance时写入的;第二类消息是在提交位移时写入的;第三类消息是在Kafka后台线程扫描并删除过期位移或者__consumer_offsets分区副本重分配时写入的。
四、消息留存策略
__consumer_offsets目前的留存策略是compact,__consumer_offsets会定期对消息内容进行compact操作——用户也可以同时启用两种留存策略来减少该topic所占的磁盘空间,不过要承担可能丢失位移数据的风险。
五、副本因子
__consumer_offest不受server.properties中num.partitions和default.replication.factor参数的制约。相反地,它的分区数和备份因子分别由offsets.topic.num.partitions和offsets.topic.replication.factor参数决定。这两个参数的默认值分别是50和1,表示该topic有50个分区,副本因子是1。鉴于位移和group元数据等信息都保存在该topic中,实际使用过程中很多用户都会将offsets.topic.replication.factor设置成大于1的数以增加可靠性,这是推荐的做法。不过在0.11.0.0之前,这个设置是有缺陷的:假设你设置了offsets.topic.replication.factor = 3,只要Kafka创建该topic时可用broker数<3,那么创建出来的__consumer_offsets的备份因子就是2。也就是说Kafka并没有尊重我们设置的offsets.topic.replication.factor参数。好在这个问题在0.11.0.0版本得到了解决,现在用户在使用时,一旦需要创建__consumer_offsets了Kafka一定会保证凑齐足量的broker才会开始创建,否则就抛出异常给用户。
日常使用中,另一个常见的问题是如何扩展该topic的副本因子。由于它依然是一个Kafka topic,因此我们可以调用bin/kafka-reassign-partitions.sh(bat)脚本来扩展replication factor。做法如下:
1. 构造一个json文件,如下所示,其中1,2,3表示3台broker的ID
{"version":1, "partitions":[
{"topic":"__consumer_offsets","partition":0,"replicas":[1,2,3]},
{"topic":"__consumer_offsets","partition":1,"replicas":[2,3,1]},
{"topic":"__consumer_offsets","partition":2,"replicas":[3,1,2]},
{"topic":"__consumer_offsets","partition":3,"replicas":[1,2,3]},
...
{"topic":"__consumer_offsets","partition":49,"replicas":[2,3,1]}
]}
2. 运行bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file reassign.json --execute
如果一切正常,你会发现__consumer_offsets的replication factor已然被扩展为3。
六、如何删除group信息
首先明确一点,Kafka是会删除consumer group信息的,既包括位移信息,也包括组元数据信息。对于位移信息而言,前面提到过每条位移消息都设置了过期时间。每个Kafka broker在后台会启动一个线程,定期(由offsets.retention.check.interval.ms确定,默认10分钟)扫描过期位移,并删除之。而对组元数据而言,删除它们的条件有两个:1. 这个group下不能存在active成员,即所有成员都已经退出了group;2. 这个group的所有位移信息都已经被删除了。当满足了这两个条件后,Kafka后台线程会删除group运输局信息。
好了, 我们总说删除,那么Kafka到底是怎么删除的呢——正是通过写入具有相同key的tombstone消息。我们举个例子,假设__consumer_offsets当前保存有一条位移消息,key是【testGroupid,test, 0】(三元组),value是待提交的位移信息。无论何时,只要我们向__consumer_offsets相同分区写入一条key=【testGroupid,test, 0】,value=null的消息,那么Kafka就会认为之前的那条位移信息是可以删除的了——即相当于我们向__consumer_offsets中插入了一个delete mark。
再次强调一下,向__consumer_offsets写入tombstone消息仅仅是标记它之前的具有相同key的消息是可以被删除的,但删除操作通常不会立即开始。真正的删除操作是由log cleaner的Cleaner线程来执行的。
鉴于目前水平有限,能想到的就这么多。有相关问题的读者可以将问题发动评论区,如果具有较大的共性,我会添加到本文的末尾~~
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px Menlo; color: #000000; background-color: #ffffff }
span.s1 { }
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px Menlo; color: #000000; background-color: #ffffff }
span.s1 { }
关于Kafka __consumer_offests的讨论的更多相关文章
- 关于Kafka配额的讨论(2)
继续前一篇的讨论.前文中提到了两大类配额管理:基于带宽的以及基于CPU线程使用时间的.本文着重探讨基于CPU线程时间的配额管理. 定义 这类配额管理被称为请求配额(request quota),管理起 ...
- 关于Kafka配额的讨论(1)
Kafka自0.9.0.0版本引入了配额管理(quota management),旨在broker端对clients发送请求进行限流(throttling).目前Kafka支持两大类配额管理: 网络带 ...
- Kafka是分布式发布-订阅消息系统
Kafka是分布式发布-订阅消息系统 https://www.biaodianfu.com/kafka.html Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apa ...
- DataPipeline |《Apache Kafka实战》作者胡夕:Apache Kafka监控与调优
胡夕 <Apache Kafka实战>作者,北航计算机硕士毕业,现任某互金公司计算平台总监,曾就职于IBM.搜狗.微博等公司.国内活跃的Kafka代码贡献者. 前言 虽然目前Apache ...
- DataPipeline |ApacheKafka实战作者胡夕:Apache Kafka监控与调优
https://baijiahao.baidu.com/s?id=1610644333184173190&wfr=spider&for=pc DataPipeline |ApacheK ...
- Spark Streaming揭秘 Day15 No Receivers方式思考
Spark Streaming揭秘 Day15 No Receivers方式思考 在前面也有比较多的篇幅介绍了Receiver在SparkStreaming中的应用,但是我们也会发现,传统的Recei ...
- alpakka-kafka(1)-producer
alpakka项目是一个基于akka-streams流处理编程工具的scala/java开源项目,通过提供connector连接各种数据源并在akka-streams里进行数据处理.alpakka-k ...
- Kafka水位(high watermark)与leader epoch的讨论
~~~这是一篇有点长的文章,希望不会令你昏昏欲睡~~~ 本文主要讨论0.11版本之前Kafka的副本备份机制的设计问题以及0.11是如何解决的.简单来说,0.11之前副本备份机制主要依赖水位(或水印) ...
- 关于Kafka日志留存策略的讨论
关于Kafka日志留存(log retention)策略的介绍,网上已有很多文章.不过目前其策略已然发生了一些变化,故本文针对较新版本的Kafka做一次统一的讨论.如果没有显式说明,本文一律以Kafk ...
随机推荐
- IOS常见的加密方法,常用的MD5和Base64
iOS代码加密常用加密方式 iOS代码加密常用加密方式,常见的iOS代码加密常用加密方式算法包括MD5加密.AES加密.BASE64加密,三大算法iOS代码加密是如何进行加密的,且看下文 MD5 iO ...
- LeetCode(33)-Pascal's Triangle II
题目: Given an index k, return the kth row of the Pascal's triangle. For example, given k = 3, Return ...
- MOOS学习笔记——多线程
/* * A simple example showing how to use a comms client */ #include "MOOS/libMOOS/Comms/MOOSAsy ...
- PM2 Quick Start
PM2教程 @(Node)[负载均衡|进程管理器] [TOC] PM2简介 PM2 是一个带有负载均衡功能的Node应用的进程管理器. 当你要把你的独立代码利用全部的服务器上的所有CPU,并保证进程永 ...
- Javac的实现过程
主要介绍Javac的实现过程及原理. 首先弄明白什么是Javac? Javac是一种编译器,将一种语言转换为另一种语言规范.编译器的作用就是将符合java语言规范的源代码转化为JVM虚拟机能够识别的字 ...
- 菜鸟级Git GitHub创建仓库
菜鸟标准:知道pwd ,rm 命令是什么. 一.Git 是什么. git 是目前世界上最先进的分布式版本控制系统 二.SVN与Git 1.版本控制系统 SVN 是集中式版本控制系统,版本库是集中放在中 ...
- 小试cordova
Cordova就是以前的PhoneGap捐献给Apache的最新开源版本. 安装一定要走npm网络方式,需要装Node.js,npm(windows nodejs安装包包含npm),Git.因为必须要 ...
- 全屏slider--swiper
这两年,这种滑动器技术在互联网产品介绍页设计上非常常用,最近某个项目需要这种设计,在网上找了一下,有个老外产的这种设计组件swiper已经非常成熟,原来这个东西设计初衷是pad之类的移动触摸交互设备, ...
- nginx防盗链
盗链是指一个网站的资源(图片或附件)未经允许在其它网站提供浏览和下载.尤其热门资源的盗链,对网站带宽的消耗非常大,本文通过nginx的配置指令location来实现简单的图片和其它类型文件的防盗链. ...
- 神奇的ASCⅡ码图
神奇的ASCⅡ码图 可能在网上也常见了asc2码图,但你知道是怎么做出来的吗?(总不可能是人一个一个字码进去的吧,当然,不排除有这种神人的可能