Elasticsearch笔记二之Curl工具基本操作
简介:
Curl工具是一种可以在命令行访问url的工具,支持get和post请求方式。-X指定http请求的方法,-d指定要传输的数据。
创建索引:
Put创建
curl -XPUThttp://localhost:9200/shb01/student/1-d'{"name":"jack","age":30,"info":"Ilove you"}'
{"_index":"shb01","_type":"student","_id":"1","_version":1,"created":true}Youhave new mail in /var/spool/mail/root
执行put后有返回值
_index索引名称
_type类型名
_version版本号
created:true表示是新创建的。
上面的命令每执行一次version就会加1,-XPUT必须制定id。
Post创建索引
curl -XPOSThttp://localhost:9200/shb01/student -d'{"name":"tom","age":21,"info":"tom"}'
{"_index":"shb01","_type":"student","_id":"AVadzuNgxskBS1Rg2tdp","_version":1,"created":true}
使用post创建索引数据,-XPOST可以指定id,此时如果存在相同数据则是修改,不指定id的话会随机生成id,且每次执行都会生成新数据。
如果需要每次执行都产生新的数据可以使用post命令且不指定id。
如果使用put命令则需要增加create,命令格式如下
curl -XPUT http://localhost:9200/shb01/student/1/_create-d '{"name":"jackk","age":31}'
curl -XPUThttp://localhost:9200/shb01/student/1?op_type=create -d'{"name":"jackk","age":31}'
以上两条命令执行时如果存在id相同的数据则会给出error信息
{"error":"DocumentAlreadyExistsException[[shb01][2][student][1]: document already exists]","status":409}
Post与put的区别
Put是等幂操作,即无论执行多少次结果都一样,例如DEL无论删除多少次索引库中的结果都一样,put只要指定了id且数据不变无论执行多少次索引库中的数据都不变,只有version会变化。
Post每次执行都会产生新数据。
查询
1:查询索引库shb01中的类型student
浏览器:http://192.168.79.131:9200/shb01/student/_search?pretty

Curl:curl -XGET http://192.168.79.131:9200/shb01/student/_search?pretty
其显示结果与浏览器一样。
2:查询文档1中的数据
http://192.168.79.131:9200/shb01/student/1?pretty
http://192.168.79.131:9200/shb01/student/1?_source&pretty
两者结果一样
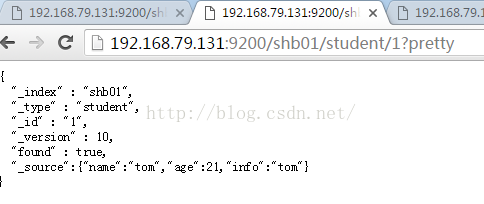
http://192.168.79.131:9200/shb01/student/1?_source=name&pretty
可以通过source指定显示那些字段
3:查询所有索引库信息
浏览器:http://192.168.79.131:9200/_search?pretty

将索引库shb01和shb02的数据都显示出来。
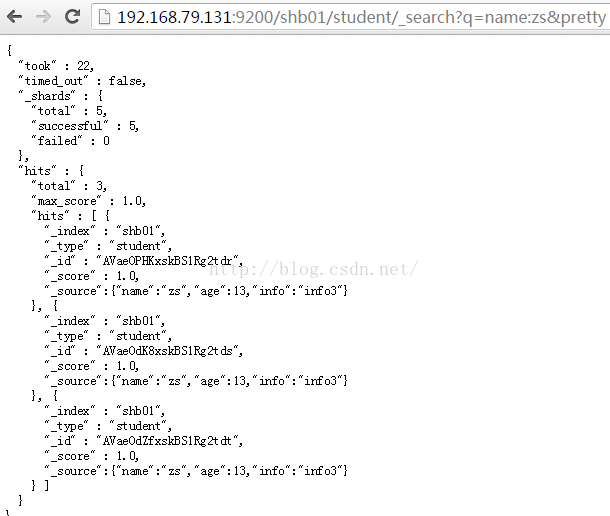
4:根据条件查询
浏览器:http://192.168.79.131:9200/shb01/student/_search?q=name:zs&pretty
查询name为zs的数据
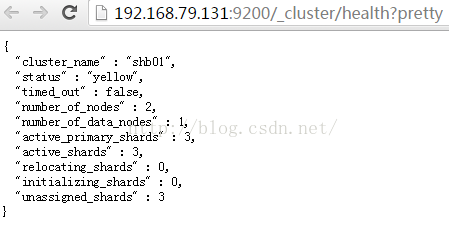
5:查询集群状态
Curl –XGET http://192.168.79.131:9200/_cluster/health?pretty
http://192.168.79.131:9200/_cluster/health?pretty
6:多索引,多类型查询,分页查询,超时
Curl:curl -XGET http://192.168.79.131:9200/shb01,shb02/stu,tea/_search?pretty
curl -XGET http://192.168.79.131:9200/_all/stu,tea/_search?pretty
浏览器去掉curl –XGET即可
分页
curl -XGET http://192.168.79.131:9200/shb01/stu/_search?size=2&from=0
超时
curl -XPOST http://192.168.79.131:9200/_search?_timeout=100
更新
Es
部分更新
如果文档1的字段很多而我们只需要更新其中的一两个字段则可以通过doc指定需要修改的字段其他字段则不必修改。
crul –XPUT
http:192.168.79.131:9200/shb01/student/1/_update?version=1
–d ‘{“doc”:{“name”:”updatename”}’
全量更新:
更新文档1中所有字段的内容。
curl -XPUThttp://192.168.79.131:9200/shb01/student/1 -d'{"name":"will","age":100,"info":"newonw"}'
更新流程
es会将旧的文档进行标记然后再添加新数据,旧的文档也不能再被访问,在后续添加数据时es会清理已经为删除状态的数据。
删除
删除文档并不会立即生效,只会将其标记为已删除,当后续添加更多索引时才会在后台删除。
curl -XDELETE http://192.168.79.131:9200/shb01/student/AVad05EExskBS1Rg2tdq
根据id删除,删除成功返回found:true,找不到found:false,版本号都会加1。
根据条件删除,删除索引shb01,shb02种类型student,tea中所有name为zs的文档
curl -XDELETEhttp://192.168.79.131:9200/shb01,shb02/student,tea/_query?q=name:zs
删除所有的索引库中名称为tom的文档
curl -XDELETE http://192.168.79.131:9200/_all/_query?q=name:tom
批处理
将一批数据加载入内存然后和es交互一次,一次性同时处理多个请求和Redis的管道类似。
格式:
Action:index/create/delete/update
Metadata:_index/_type/_id
Create:如果数据存在则报错;index:如果数据存在仍会执行成功。
步骤:
1:在liunx下创建一个文件request1,vi request1
{"index":{"_index":"shb01","_type":"student","_id":"1"}}
{"name":"st01","age":"10","info":"st01"}
{"create":{"_index":"shb100","_type":"student","_id":"2"}}
{"name":"tea01","age":"10","info":"tea01"}
{"delete":{"_index":"shb01","_type":"student","_id":"AVadzuNgxskBS1Rg2tdp"}
{"update":{"_index":"shb02","_type":"tea","_id":"1"}}
{"doc":{"name":"zszszszs"}}
文件中
index表示操作类型
_index指定索引库,_type指定类型,_id指定操作文档
2:执行批处理命令,关键字_bulk
curl -XPUThttp://192.168.79.131:9200/_bulk --data-binary @/usr/local/request1
注意:--data-binary@之间有空格隔开,我在实验中没有空格一直提示操作参数不对。
3:返回值
{
"took":957,"errors":false,"items":[
{"index":{"_index":"shb01","_type":"student","_id":"1","_version":12,"status":200}},
{"create":{"_index":"shb100","_type":"student","_id":"2","_version":1,"status":201}},
{"delete":{"_index":"shb01","_type":"student","_id":"AVadzuNgxskBS1Rg2tdp","_version":2,"status":200,"found":true}},
{"update":{"_index":"shb02","_type":"tea","_id":"1","_version":2,"status":200}}
]
返回信息中errors表示批处理有没有错误,注意version和status,其中shb100为新创建的索引库
下面是我第二次执行request1文件的返回信息,errors为true,表示批处理中有操作执行失败,可以看到create因为库中已有id相同的文档所以报错。但是虽然存在错误操作但其他的操作依然成功执行。这点和redis中的事务操作类似。
{
"took":22,"errors":true,"items":[
{"index":{"_index":"shb01","_type":"student","_id":"1","_version":13,"status":200}},
{"create":{"_index":"shb100","_type":"student","_id":"2","status":409,"error":"DocumentAlreadyExistsException[[shb100][3][student][2]: document already exists]"}},
{"delete":{"_index":"shb01","_type":"student","_id":"AVadzuNgxskBS1Rg2tdp","_version":1,"status":404,"found":false}},
{"update":{"_index":"shb02","_type":"tea","_id":"1","_version":3,"status":200}}
]
}
4:在命令中指定索引库和类型
创建一个文件,文件中没有配置索引库和类型
{"index":{"_id":"1"}}
{"name":"st1_1","age":"10","info":"st1_1"}
{"create":{"_id":"200"}}
{"name":"st200","age":"10","info":"st200"}
执行如下命令,在命令中指定了索引库和类型
curl -XPUThttp://192.168.79.131:9200/shb01/student/_bulk --data-binary@/usr/local/request2
返回信息
{
"took":24,"errors":false,"items":[
{"index":{"_index":"shb01","_type":"student","_id":"1","_version":17,"status":200}},
{"create":{"_index":"shb01","_type":"student","_id":"200","_version":1,"status":201}}
]
}
5:也可以使用-XPOST替换-XPUT
Elasticsearch笔记二之Curl工具基本操作的更多相关文章
- Java学习笔记二:Java开发工具Eclipse的安装与使用
Java开发工具Eclipse的安装与使用 正如office一样我们在开发java语言过程中同样需要依款不错的开发工具,目前市场上的IDE很多,这里只演示Eclipse的安装: 一:下载软件: 1.下 ...
- Erlang:[笔记二,构建工具rebar之发布应用]
概述 通过rebar可以发布rebar构建的erlang项目,生成可执行的二进制脚本文件,大大降低了执行应用的复杂度.该笔记Erlang环境为Erlang/OTP 19 ,以下适用于Eralng/OT ...
- Elasticsearch学习概念之curl
curl,简单认为是可以在命令行下访问url的一个工具.即增删改查. curl是利用URL语法在命令行方式下工作的开源文件传输工具,使用curl可以简单实现常见的get/post请求. 查看curl的 ...
- java并发编程笔记(二)——并发工具
java并发编程笔记(二)--并发工具 工具: Postman:http请求模拟工具 Apache Bench(AB):Apache附带的工具,测试网站性能 JMeter:Apache组织开发的压力测 ...
- Emacs 笔记二
Emacs 笔记二 Table of Contents 1. 前言 2. emacs基本操作(常用快捷键) 3. emacs模式讲解 4. emacs缓冲区 5. org mode 5.1. 列表 5 ...
- jQuery源码笔记(二):定义了一些变量和函数 jQuery = function(){}
笔记(二)也分为三部分: 一. 介绍: 注释说明:v2.0.3版本.Sizzle选择器.MIT软件许可注释中的#的信息索引.查询地址(英文版)匿名函数自执行:window参数及undefined参数意 ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
- Elasticsearch笔记九之优化
Elasticsearch笔记九之优化 ).get(); } curl命令可以在linux中建立一个定时任务每天执行一次,同样java代码也可以建立一个定时器来执行. 2:内存设置之前介绍过es集群有 ...
随机推荐
- wamp 服务监控和启动
近日我的 wamp 莫名其妙的崩溃重启,apache 能自动起来, mysql 却悲剧了. 于是有了下面的wamp服务监控和启动的批处理文件 @echo off rem define loop tim ...
- Eclipse 3.5 以后安装插件很慢的解决办法
1 .除非你需要,否则不要选择"联接到所有更新站点" 在安装对话框里有一个小复选框,其标示为"在安装过程中联接到所有更新站点从而找到所需的软件."从表面上看,这 ...
- 返回空的list集合*彻底删除删除集合*只是清空集合
---------- 要求返回空的List集合----------- List<String> allList = Collections.emptyList();// 返回空的List集 ...
- getElementById 用法的一个技巧
假设实现把 TextBox1 的字符实时的拷贝到 TextBox2 中,代码如下: <Script language="Javascript"> fun ...
- sqlServer遇到的问题
重置自增列:dbcc checkident(表名,reseed,数字(初始值))
- java之web开发过滤器
我们通常上网的时候都会遇到一个问题,看到一个视频之类的,想要点开观看,点击之后,网页 提醒你:您尚未登录,是否要登录?然后巴拉巴拉跑去输账号密码. 那么这就是一个过滤器的功能,当你要访问一个资源的时候 ...
- vue.js中的全局组件和局部组件
组件(Component)是 Vue.js 最强大的功能之一.组件可以扩展 HTML 元素,封装可重用的代码.在较高层面上,组件是自定义元素, Vue.js 的编译器为它添加特殊功能. 组件的使用有三 ...
- 分布式任务调度平台XXL-JOB
<分布式任务调度平台XXL-JOB> 一.简介 1.1 概述 XXL-JOB是一个轻量级分布式任务调度框架,其核心设计目标是开发迅速.学习简单.轻量级.易扩展.现已开放源代码并 ...
- JavaScirpt的this指向 apply().call(),bind()个人笔记
写在前头: 本站内容为个人学习记录,纯属个人观点,不喜勿喷,欢迎指正! 笔记记录缘由:JavaScript的流行趋势已经势不可挡,衍生的AngularJs,Node.js,BootStrmp中小企业的 ...
- 如何在自定义组件中使用v-model
文章属于速记,有错误欢迎指出.风格什么的不喜勿喷. 先来一个组件,不用vue-model,正常父子通信 <!-- parent --> <template> <div c ...