Hadoop问题:DataNode进程不见了
DataNode进程不见了
问题描述
最近配置Hadoop的时候出现了这么一个现象,启动之后,使用jps命令之后是这样的:
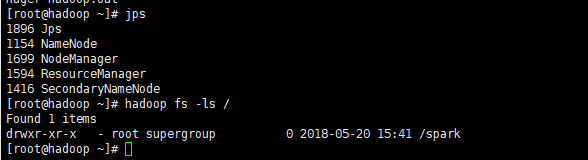
看不到DataNode进程,但是能够正常的工作,是不是很神奇啊?
在一番百度谷歌之后,得出了结论:
我在启动Hadoop之前和启动之后,曾经多次使用如下命令,针对NameNode进行格式化:
hadoop namenode -format这个问题,还不是你直接多次格式化造成的,而是你格式化之后,启动了Hadoop,然后将Hadoop关闭,重新格式化,再启动Hadoop造成的,这个时候你就发现,DataNode线程在jps命令中消失了,还能正常使用,就如我开头的那张图一样。造成这个问题的根源,是NameNode和DataNode的版本号不一致所致。这个问题不仅仅会出现在伪分布式,完全分布式中也会出现。这里以伪分布式进行展示。
如下是正常的两个文件的信息。
NameNode VERSION文件信息:
namespaceID=51628800
clusterID=CID-97bb16dc-c439-427c-9841-5e6e4667cb65
cTime=0
storageType=NAME_NODE
blockpoolID=BP-1918730739-172.17.241.131-1526803461127
layoutVersion=-63DataNode VERSION文件信息:
storageID=DS-4281731b-7a44-4c86-8844-e1927a4fc966
clusterID=CID-97bb16dc-c439-427c-9841-5e6e4667cb65
cTime=0
datanodeUuid=197c3d68-454b-4287-a5e5-90c01ed9be53
storageType=DATA_NODE
layoutVersion=-56所谓版本号不一致,就是说的clusterID的值,上面的信息展示的是一致的,也表明NameNode和DataNode是一组的。
那么这两个文件存放在哪里呢?如下是你在Hadoop配置文件core-site.xml中的一项,就在此项指定的目录之下。
<property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop-2.7.1/tmp</value>
</property>那我就以我这个配置的路径来进行查找,首先到tmp目录下:
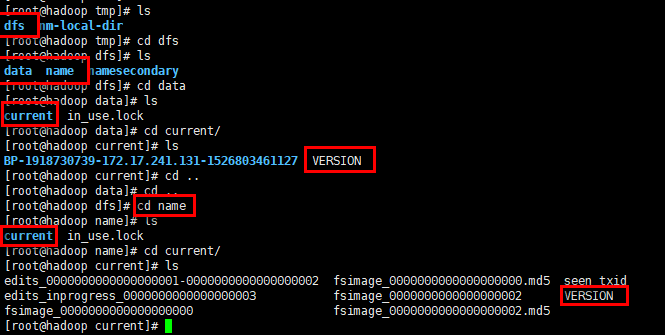
如上图是完整的查找路径。
问题分析
下面进行此问题的分析:
当第一次格式化,启动Hadoop的时候,没有任何问题,任何环节都是新产生的,所以哪怕你在启动Hadoop之前进行多次的NameNode格式化都可以,因为在Hadoop启动之前,DataNode的版本还没有生成,只有Hadoop启动之后DataNode的版本等响应信息才会在指定的目录下生成,这个时候就产生了NameNode和DataNode的一对一的关系。
当你关掉Hadoop之后进行二次NameNode格式化的时候,NameNode的版本信息等进行了重新写入,内容肯定和之前的不一样,这样就造成了,上文中我提到的clusterID不一致的问题,这样,你再次启动Hadoop,所有功能都正常使用,但唯独jps命令下看不到DataNode线程,这当然会使我们每个程序员感到惊慌,怎么办?
解决方案

方案一
首先,在格式化之前,将你设置的存储Hadoop信息目录下清空,即我上图中的例子tmp目录,将此目录清空即可。也可直接删除此目录,然后新建一个。
然后,进行格式化,这样所产生的NameNode和DataNode信息都是新的,也都是一组的,问题就解决了,这个是最简单最有效的方法。
方案二
如果有数据还在,又不想清空数据,那么这个方案就是你的福音。
既然是版本号不一致产生的问题,那么我们就单独解决版本号的问题,将你格式化之后的NameNode的VERSION文件找到,然后将里面的clusterID进行复制,再找到DataNode的VERSION文件,将里面的clusterID进行替换,保存之后重启,那么就可以正常的使用了。查找的的路径,已经在上图中进行了展示,这里不做赘述。
就以上问题,目前我只想到两个解决方案。
Hadoop问题:DataNode进程不见了的更多相关文章
- 解决hadoop no dataNode to stop问题
错误原因: datanode的clusterID 和 namenode的 clusterID 不匹配. 解决办法: 1. 打开 hadoop/tmp/dfs/namenode/name/dir 配置对 ...
- 记一次hadoop datanode进程问题分析
症状:datanode进程还在,但是在web ui接口发现该节点已经被置为dead节点.监测datanode进程日志,开始时一直狂刷很忙,后来停止刷新日志. 分析datanode进程日志,发现如下一些 ...
- hadoop在子节点上没有datanode进程
经常会有这样的事情发生:在主节点上start-all.sh后,子节点有TaskTracker进程,而没有DataNode进程.环境:1NameNode 2DataNode三台机器,Hadoop为1 ...
- 【Hadoop故障处理】全分布下,DataNode进程正常启动,但是网页上不显示,并且DataNode节点为空
[故障背景] DataNode进程正常启动,但是网页上不显示,并且DataNode节点为空. /etc/hosts 的ip和hostname配置正常,各个机器之间能够ping通. [日志错误信息] ...
- Hadoop完全分布式环境下,DataNode进程正常启动,但是网页上不显示DataNode节点
Hadoop完全分布式环境下,上传文件到hdfs上时报错: // :: WARN hdfs.DFSClient: DataStreamer Exception org.apache.hadoop.ip ...
- Hadoop的datanode无法启动
Hadoop的datanode无法启动 hdfs-site中配置的dfs.data.dir为/usr/local/hadoop/hdfs/data 用bin/hadoop start-all.sh启动 ...
- 启动Hadoop时候datanode没有启动的原因及解决方案
有时候我们start-dfs.sh启动了hadoop但是发现datanode进程不存在 一.原因 当我们使用hadoop namenode -format格式化namenode时,会在namenode ...
- hadoop中DataNode消失挂掉的原因及解决方法
昨天在进行Hadoop实验时遇到一个问题,在sbin目录下输入jps命令,查看当前节点的状态时,意外发现DataNode节点不见了!!于是回忆了一下自己之前的操作过程,大概是因为将自己进入文件夹,将某 ...
- hadoop启动守护进程报JAVA_HOME is not set and could not be found
hadoop启动守护进程 sbin/start-dfs.sh 报如下错误:JAVA_HOME is not set and could not be found 解决办法(JAVA_HOME修改为具体 ...
随机推荐
- Qt Creator 更改默认构建目录到工程目录下
Qt Creator 更改默认构建目录到工程目录下 步骤 工具->选项->构建和运行->概要->Default build directory->去掉第一个". ...
- miniui 给表格行添加监听事件的几种方法以及点击某列列名数据不能排序的问题
最近在使用miniui框架做开发,在做表格行的点击监听事件中发现了几个属性,都可以起到监听效果但是执行的结果却大有不同.好了废话不多说,直接上代码. <div id="pageGrid ...
- 致IT之路的先驱者和旅人
1,图灵和香农 故事的开始,要从计算机之父图灵和信息论的创始人香农开始说起.图灵最大的贡献是发明了图灵机,关于图灵机如果要让人明白究竟有什么用,从如何实现一个半导体电路图灵机这方面理解比较好.只要一个 ...
- MTCNN人脸检测 附完整C++代码
人脸检测 识别一直是图像算法领域一个主流话题. 前年 SeetaFace 开源了人脸识别引擎,一度成为热门话题. 虽然后来SeetaFace 又放出来 2.0版本,但是,我说但是... 没有训练代码, ...
- Nodejs经验谈
前言 这里主要说一下之前使用Nodejs开发踩过的坑,只说坑不填坑,那就是赤裸地耍流氓,文中有大量的说明及填坑方法,了解的看官可以直接跳过. PS:说实话,Nodejs的坑确实蛮多的:但是上手简单,扩 ...
- linux(centos 7)学习之 ~目录下的文件anaconda-ks.cfg
这个文件是记录安装系统的一些信息 #version=DEVEL # System authorization information auth --enableshadow --passalgo=sh ...
- IOC框架:Unity
Unity 是一个轻量级.可扩展的依赖注入容器,支持构造函数.属性和方法调用注入. 在进行项目之前通过Nuget安装Unity 简单的例子 定义一个接口 namespace UnityTest { / ...
- 第三章 C++的三种基本控制结构
0x C++提供的三种基本控制结构 顺序结构:按照先后顺序依次执行程序中的语句 选择结构:按照给定条件有选择地执行程序中的语句 循环语句:按照给定规则重复地执行程序中的语句 1x 第一节 C++语句 ...
- ArcCore重构-Makefile模块化
基于官方arc-stable-9c57d86f66be,AUTOSAR版本3.1.5 基本问题 2. 编译系统中代码文件是否编译及目标文件集中定义在boards/board_common.mk,而 ...
- Java多线程:线程间通信之volatile与sychronized
由前文Java内存模型我们熟悉了Java的内存工作模式和线程间的交互规范,本篇从应用层面讲解Java线程间通信. Java为线程间通信提供了三个相关的关键字volatile, synchronized ...