分布式缓存管理平台XXL-CACHE
《分布式缓存管理平台XXL-CACHE》
一、简介
1.1 概述
XXL-CACHE是一个分布式缓存管理平台,其核心设计目标是“让分布式缓存的接入和管理的更加的简洁和高效”。现已开放源代码,开箱即用。
XXL-CACHE核心思想:将分布式缓存抽象成公共RPC服务,对外提供公共API进行缓存操作; 提供缓存公共的管理和监控平台:方便的查询、管理和监控线上缓存数据;
1.2 特性
- 1、多种缓存支持:支持Redis、Memcached两种缓存在线的查询和管理;
- 2、分布式缓存管理:支持分布式环境下,集群缓存服务的查询和管理,自动命中缓存服务节点;
- 3、方便:支持通过Web界管理缓存模板,查询和管理缓存数据;
- 4、透明:集群节点变动时,缓存命中的分片逻辑保持线上一致,自动命中缓存数据;
- 5、查看序列化缓存数据:通常缓存中保存的是序列化的Java数据,因此当需要查看缓存键值数据非常麻烦,本系统支持方便的查看缓存数据内容,反序列化数据;
- 6、查看缓存数据长度:直观显示缓存数据的长度;
- 7、查看缓存JSON格式内容:支持将缓存数据转换成JSON格式,直观查看缓存数据内容;
1.3 下载
文档地址
源码仓库地址
| 源码仓库地址 | Release Download |
|---|---|
| https://github.com/xuxueli/xxl-cache | Download |
| http://gitee.com/xuxueli0323/xxl-cache | Download |
技术交流
1.4 环境
- Maven3+
- Jdk1.7+
- Tomcat7+
- Mysql5.5+
二、快速入门
2.1 初始化“数据库”
请下载项目源码并解压,获取 "调度数据库初始化SQL脚本"(脚本文件为: 源码解压根目录/xxl-cache/doc/db/xxl-cache-mysql.sql) 并执行即可。
2.2 编译源码
解压源码,按照maven格式将源码导入IDE, 使用maven进行编译即可,源码结构如下图所示:

- xxl-cache-admin:缓存管理平台
- xxl-cache-core:公共依赖,为缓存服务抽象成公共RPC服务做准备
2.3 配置部署“缓存管理平台”
项目:xxl-cache-admin
作用:查询和管理线上分布式缓存数据
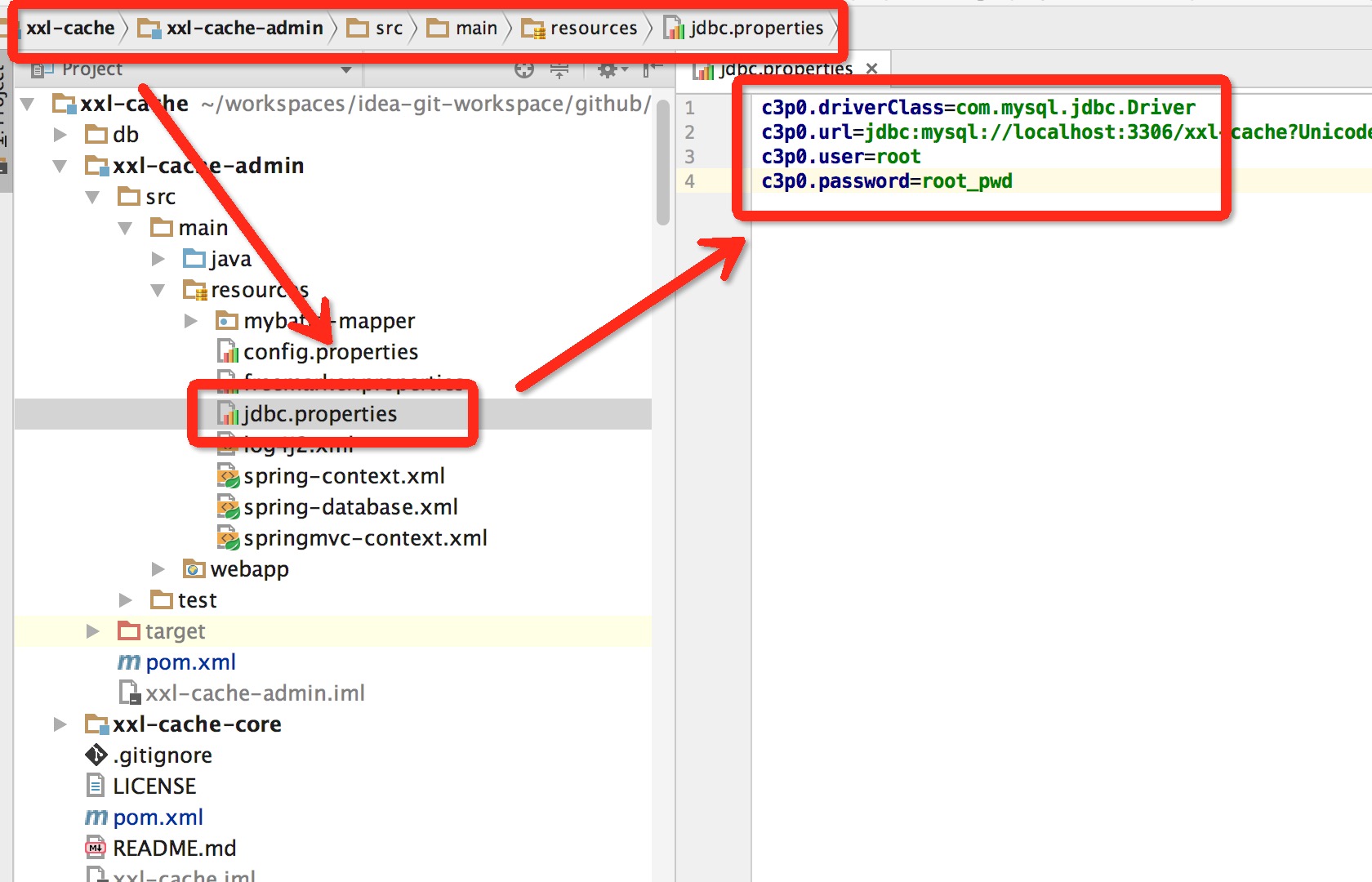
- A:配置“JDBC链接”:请在下图所示位置配置jdbc链接地址,链接地址请保持和 2.1章节 所创建的调度数据库的地址一致。
- B:配置“分布式缓存配置”:请在下图所示位置配置分布树缓存信息,和线上项目中缓存配置务必保持一致。
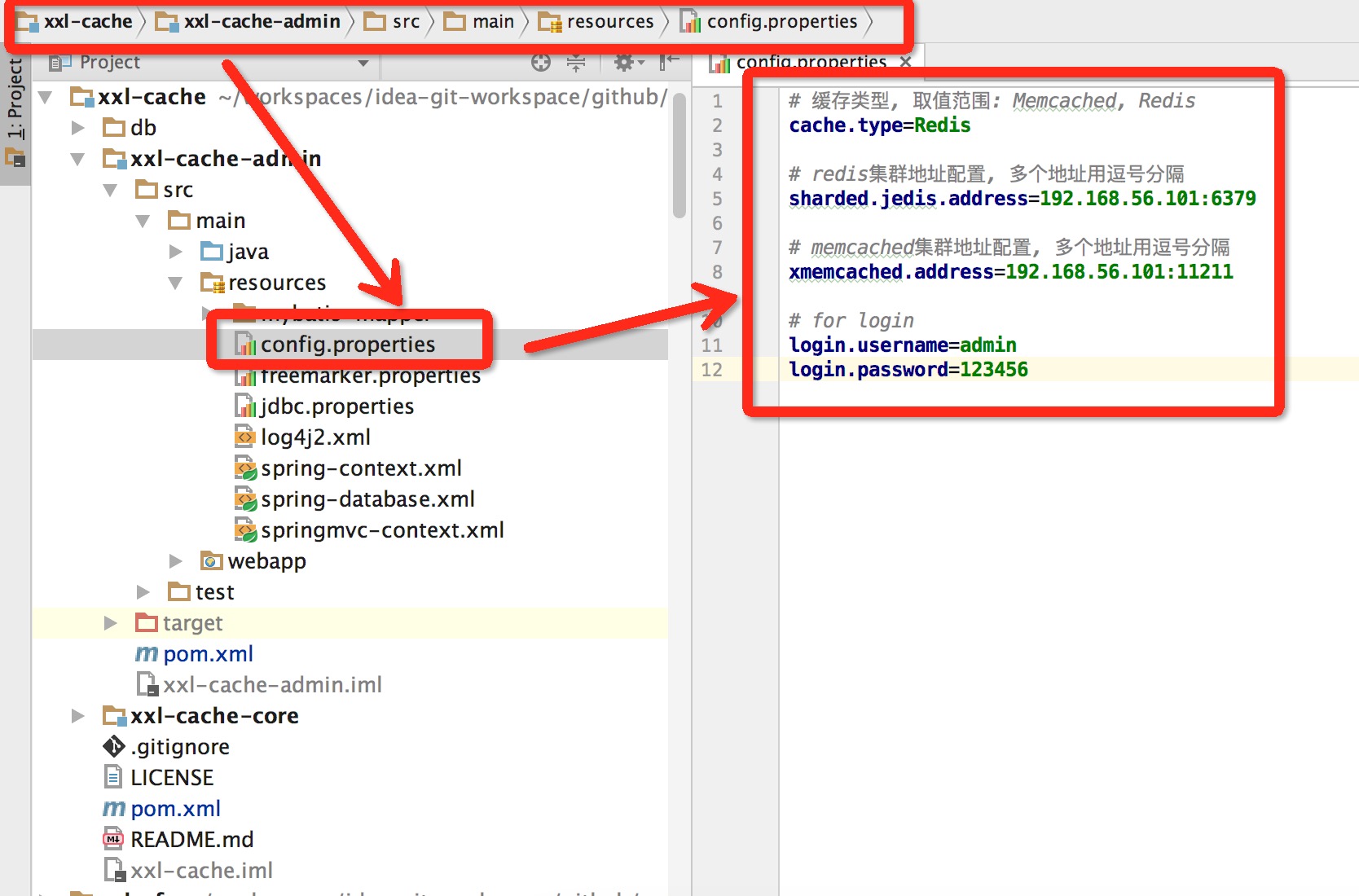
配置详解:
# 缓存类型, 取值范围: Memcached, Redis;(如配置Redis,则Redis地址生效,Memcached配置则被忽略,可删除)
cache.type=Redis
# redis集群地址配置, 多个地址用逗号分隔(当cache.type为Redis时生效)
sharded.jedis.address=192.168.56.101:6379
# memcached集群地址配置, 多个地址用逗号分隔(当cache.type为Memcached时生效)
xmemcached.address=192.168.56.101:11211
# for login (登录账号)
login.username=admin
login.password=123456
2.4 查询线上缓存
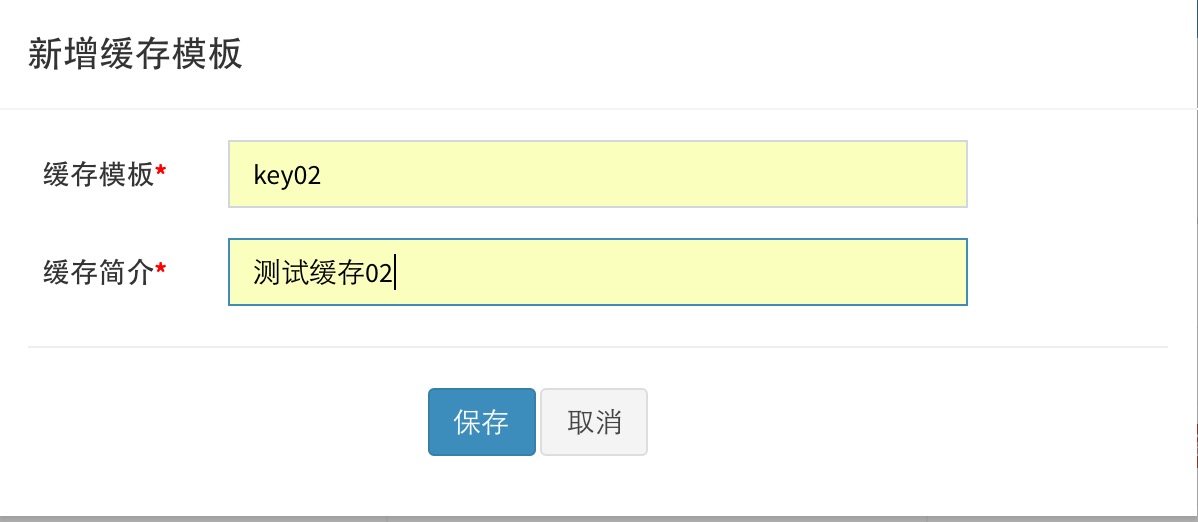
进入“缓存管理”界面,点击“新增缓存模板界面”,配置模板信息
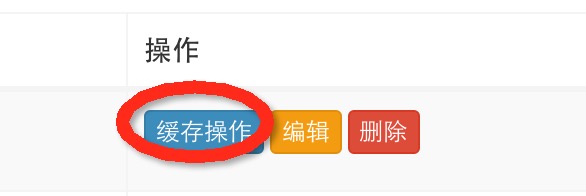
然后,点击缓存模板右侧的“缓存操作”按钮
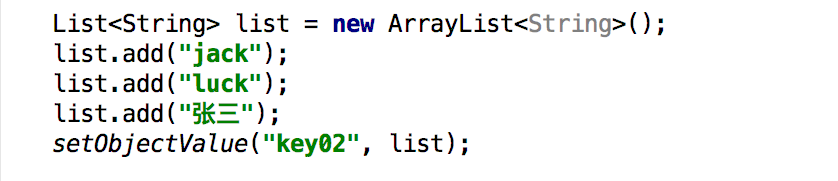
Set缓存数据,代码如下
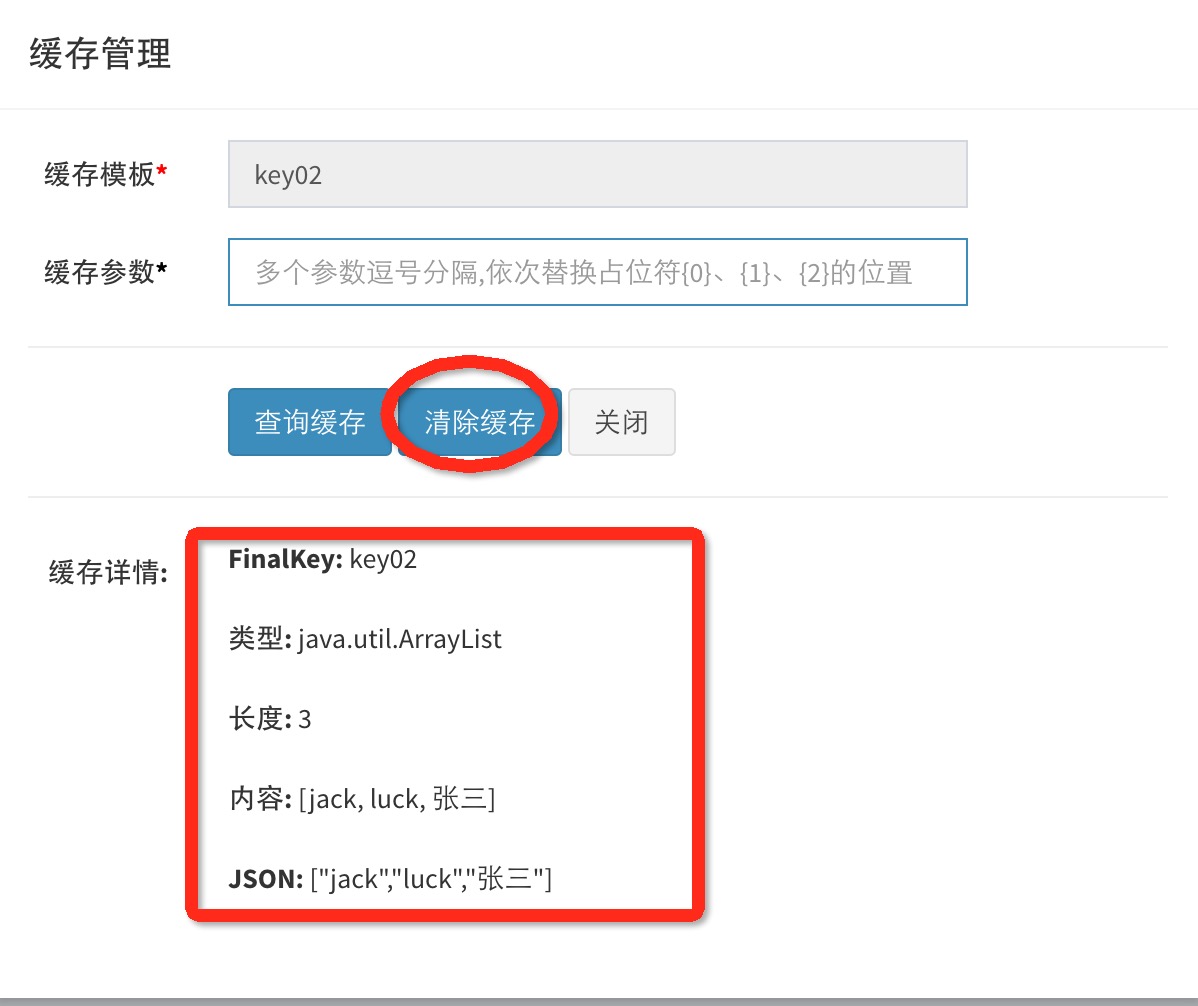
点击“查询缓存”,即可直观查看缓存信息
二、缓存模板详解
3.1 XXl-CACHE系统中常用名词(缓存属性)解释
缓存模板:生成缓存Key的模板,占位符用{0}、{1}、{2}依次替代;
缓存描述:缓存的描述说明;
缓存参数:“缓存模板”中占位符对应的参数,多个参数逗号分隔,依次替换占位符{0}、{1}、{2}的位置;
FinalKey:保存在分布式缓存服务中最终的Key的值,根据“缓存模板”和“缓存参数”生成;
四、缓存管理
略
五、总体设计
5.1 源码目录介绍
- /db :“数据库”建表脚本
- /xxl-cache-admin :缓存管理平台,项目源码;
- /xxl-cache-core : 公共依赖;(规划中)
5.2 核心思想
XXL-CACHE核心思想:
1、将分布式缓存抽象成公共RPC服务,对外提供公共API进行缓存操作:
- 1、项目接入缓存服务更加方便:接入方只需要依赖一个RPC服务的API即可;
- 2、统一监控和维护缓存服务;
- 3、方便控制client连接数量;
- 4、缓存节点变更更加方便;
- 5、在节点变更时, 缓存分片很大可能会受影响, 这将导致不同服务的分片逻辑出现不一致的情况, 统一缓存服务可以避免之;
- 6、可以屏蔽底层API操作,提供公共API,避免API误操作;
2、提供缓存管理和监控平台:方便的查询、管理和监控线上缓存数据;
规划中
- 1、支持遍历线上缓存, 比如Redis模式, 通过 keys * 获取线上所有缓存Key的列表;
六、历史版本
版本1.0.0
时间:2016年7月下旬;
特性:
- 1、多种缓存支持:支持Redis、Memcached两种缓存在线的查询和管理;
- 2、分布式缓存管理:支持分布式环境下,集群缓存服务的查询和管理,自动命中缓存服务节点;
- 3、方便:支持通过Web界管理缓存模板,查询和管理缓存数据;
- 4、透明:集群节点变动时,缓存命中的分片逻辑保持线上一致,自动命中缓存数据;
- 5、查看序列化缓存数据:通常缓存中保存的是序列化的Java数据,因此当需要查看缓存键值数据非常麻烦,本系统支持方便的查看缓存数据内容,反序列化数据;
- 6、查看缓存数据长度:直观显示缓存数据的长度;
- 7、查看缓存JSON格式内容:支持将缓存数据转换成JSON格式,直观查看缓存数据内容;
七、其他
7.1 报告问题
XXL-CACHE托管在Github上,如有问题可在 ISSUES 上提问,也可以加入上文技术交流群;
7.2 接入登记
更多接入公司,欢迎在github 登记
分布式缓存管理平台XXL-CACHE的更多相关文章
- 分布式逻辑管理平台XXL-GLUE
<分布式逻辑管理平台XXL-GLUE> 一.简介 1.1 概述 XXL-GLUE 是一个分布式环境下的 "可执行逻辑单元" 管理平台, 学习简单,扩展JVM的动态 ...
- HDFS集中式缓存管理(Centralized Cache Management)
Hadoop从2.3.0版本号開始支持HDFS缓存机制,HDFS同意用户将一部分文件夹或文件缓存在HDFS其中.NameNode会通知拥有相应块的DataNodes将其缓存在DataNode的内存其中 ...
- 分布式爬虫管理平台Crawlab安装与使用
Why,为什么需要爬虫管理平台? 以下摘自官方文档: Crawlab主要解决的是大量爬虫管理困难的问题,例如需要监控上百个网站的参杂scrapy和selenium的项目不容易做到同时管理,而且命令行管 ...
- .net 分布式架构之分布式缓存中间件
开源git地址: http://git.oschina.net/chejiangyi/XXF.BaseService.DistributedCache 分布式缓存中间件 方便实现缓存的分布式,集群, ...
- HDFS集中式的缓存管理原理与代码剖析--转载
原文地址:http://yanbohappy.sinaapp.com/?p=468 Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache ...
- HDFS集中式的缓存管理原理与代码剖析
转载自:http://www.infoq.com/cn/articles/hdfs-centralized-cache/ HDFS集中式的缓存管理原理与代码剖析 Hadoop 2.3.0已经发布了,其 ...
- Crawlab Lite 正式发布,更轻量的爬虫管理平台
Crawlab 是一款基于 Golang 的分布式爬虫管理平台,产品发布已经一年有余,经过开发团队的不断打磨,即将迭代到 v0.5 版本.在这期间我们为 Crawlab 加入了大量社区用户共同期望的功 ...
- 爬虫管理平台以及wordpress本地搭建
爬虫管理平台以及wordpress本地搭建 学习目标: 各爬虫管理平台了解 scrapydweb gerapy crawlab 各爬虫管理平台的本地搭建 Windows下的wordpress搭建 爬虫 ...
- NCache:最新发布的.NET平台分布式缓存系统
NCache:最新发布的.NET平台分布式缓存系统在等待Microsoft完成Velocity这个.NET平台下的分布式内存缓存系统的过程中,现在让我们将目光暂时投向其他已经有所建树的软件开发商.Al ...
随机推荐
- Ubuntu 16.04 LTS今日发布
Ubuntu 16.04 LTS今日发布 Ubuntu16.04 LTS 发布日期已正式确定为 2016 年 4 月 21 日,代号为 Xenial Xerus.Ubuntu16.04 将是非常受欢迎 ...
- (NO.00001)iOS游戏SpeedBoy Lite成形记(十七)
因为现在游戏内容原来越多了,里面需要存储的数据也多了起来,所以一个较好的办法是将所有的比赛数据存到同一个地方便于存取. 我们需要新建一个游戏数据类,该类贯穿所有需要的场景,存放一切比赛需要的数据.从这 ...
- Leetcode_172_Factorial Trailing Zeroes
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/42417535 Given an integer n, re ...
- DBUtils源码分析
其实,在这篇文章里,我只是分析了dbutis的query的运作流程. 至于类为什么要这样设计,蕴含的设计模式等等高级知识点咱们在下节再探讨. 先看看最简单的DBUtils是如何工作的. 数据库里有一张 ...
- rhel6.4 安装nodejs和Mysql DB服务
rhel6.4 安装nodejs和Mysql DB服务 安装好redhat6.4虚拟机后, 安装软件: # yum install gcc-c++ openssl-devel Loaded plugi ...
- tomcat中的线程问题2
最近在看线程的有关知识,碰到一个小问题,目前还没有解决,现记录下来. 如果在我们自己写的servlet里有成员变量,因为多线程的访问就会出现一些线程问题.这点大家都知道,我们看下面的例子. publi ...
- Android ROM开发(三)——精简官方ROM并且内置ROOT权限,开启Romer之路
Android ROM开发(三)--精简官方ROM并且内置ROOT权限,开启Romer之路 相信ROM的相关信息大家通过前几篇的学习都是有所了解了,这里就不在一一提示了,这里我们下载一个官方包,我们还 ...
- ROS探索总结(十五)——amcl(导航与定位)
在理解了move_base的基础上,我们开始机器人的定位与导航.gmaping包是用来生成地图的,需要使用实际的机器人获取激光或者深度数据,所以我们先在已有的地图上进行导航与定位的仿真. amcl是移 ...
- iOS和Android开发异同点(一)
说到移动开发,目前主流平台有谷歌的android os 系统,苹果iOS系统,和微软主打的windows Phone OS 系统,至于目前为啥移动开发中,安卓和iOS比较受欢迎,者要看三家产品的历史由 ...
- java--jdk api中其他对象(System,Runtime,Calendar,Math,Random,Date)
转载请申明出处:http://blog.csdn.net/xmxkf/article/details/9796729 day18-01-其他对象(System) SystemDemo java.lan ...