ELK日志收集平台部署
需求背景
由于公司的后台服务有三台,每当后台服务运行异常,需要看日志排查错误的时候,都必须开启3个ssh窗口进行查看,研发们觉得很不方便,于是便有了统一日志收集与查看的需求。
这里,我用ELK集群,通过收集三台后台服务的日志,再统一进行日志展示,实现了这一需求。
当然,当前只是进行了简单的日志采集,如果后期相对某些日志字段进行分析,则可以通过logstash以及Kibana来实现。
部署环境
系统:CentOS 7
软件:
elasticsearch-6.1.1
logstash-6.1.1
kibana-6.1.1
下载地址:https://www.elastic.co/cn/products
搭建步骤
一:elasticsearch:
elasticsearch是用于存储日志的数据库。
下载elasticsearch软件,解压:
|
1
2
|
# tar -zxvf elasticsearch-6.1.1.tar.gz # mv elasticsearch-6.1.1 /opt/apps/elasticsearch |
由于elasticsearch建议使用非root用户启动,使用root启动会报错,故需创建一个普通用户,并进行一些简单配置:
|
1
2
3
4
5
6
|
# useradd elk# vi /opt/apps/elasticsearch/config/elasticsearch.ymlnetwork.host: 0.0.0.0http.port: 9200http.cors.enabled: truehttp.cors.allow-origin: "*" |
启动,并验证:
|
1
2
3
4
5
6
7
|
# su - elk$ nohup /opt/apps/elasticsearch/bin/elasticsearch &# netstat -ntpl | grep 9200tcp 0 0 0.0.0.0:9200 0.0.0.0:* LISTEN 6637/java #curl 'localhost:9200/_cat/health?v'epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent1514858033 09:53:53 elasticsearch yellow 1 1 241 241 0 0 241 0 - 50.0% |
如果报错:OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N 说明需要加CPU和内存
bootstrap checks failed
max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方案
1、vi /etc/sysctl.conf
设置fs.file-max=655350
vm.max_map_count=262144
保存之后sysctl -p使设置生效
2、vi /etc/security/limits.conf 新增
* soft nofile 655350
* hard nofile 655350
3、重新使用SSH登录,再次启动elasticsearch即可。
二:logstash
logstash用于收集各服务器上的日志,然后把收集到的日志,存储进elasticsearch。收集日志的方式有很多种,例如结合redis或者filebeat,这里我们使用redis收集的方式。
安装logstash:
|
1
2
3
|
在所有服务器上:# tar -zxvf logstash-6.1.1.tar.gz# mv logstash-6.1.1 /opt/apps/logstash/ |
配置后台服务器,收集相关的日志:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
在三台后台服务器上新建logstash文件,配置日志收集:# vi /opt/conf/logstash/logstash.conf input { file { #指定type type => "web_stderr" #匹配多行的日志 codec => multiline { pattern => "^[^0-9]" what => "previous" } #指定本地的日志路径 path => [ "/opt/logs/web-stderr.log"] sincedb_path => "/opt/logs/logstash/sincedb-access" } file { type => "web_stdout" codec => multiline { pattern => "^[^0-9]" what => "previous" } path => [ "/opt/logs/web-stdout.log"] sincedb_path => "/opt/logs/logstash/sincedb-access" } #收集nginx日志 file { type => "nginx" path => [ "/opt/logs/nginx/*.log"] sincedb_path => "/opt/logs/logstash/sincedb-access" }}output { #指定输出的目标redis redis { host => "xx.xx.xx.xx" port => "6379" data_type => "list" key => "logstash" }} |
配置elk日志服务器上的logstash,从redis队列中读取日志,并存储到elasticsearch中:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# vi /opt/conf/logstash/logstash-server.conf#配置从redis队列中读取收集的日志input { redis { host => "xx.xx.xx.xx" port => "6379" type => "redis-input" data_type => "list" key => "logstash" threads => 10 }}#把日志输出到elasticsearch中output { elasticsearch { hosts => "localhost:9200" index => "logstash-%{type}.%{+YYYY.MM.dd}" } #这里把日志收集到本地文件 file { path => "/opt/logs/logstash/%{type}.%{+yyyy-MM-dd}" codec => line { format => "%{message}"} }} |
启动logstash进程:
|
1
2
3
4
|
后台服务器:# nohup /opt/apps/logstash/bin/logstash -f /opt/conf/logstash/logstash.conf --path.data=/opt/data/logstash/logstash &elk日志服务器:# nohup /opt/apps/logstash/bin/logstash -f /opt/conf/logstash/logstash-server.conf --path.data=/opt/data/logstash/logstash-server & |
三:kibana
kibana用于日志的前端展示。
安装、配置kibana:
|
1
2
3
4
5
6
7
8
|
# tar -zxvf kibana-6.1.1-linux-x86_64.tar.gz# mv kibana-6.1.1-linux-x86_64 /opt/apps/kibana配置elasticsearch链接:# vi /opt/apps/kibana/config/kibana.ymlserver.port: 5601server.host: "0.0.0.0"#配置elasticsearch链接:elasticsearch.url: "http://localhost:9200" |
启动kibana:
|
1
|
nohup /opt/apps/kibana/bin/kibana & |
访问kibana:
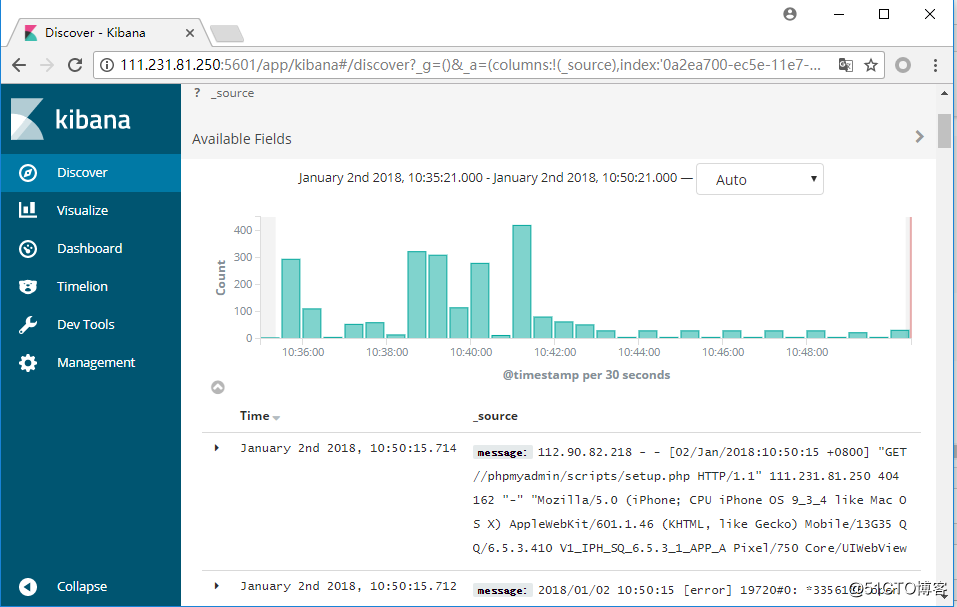
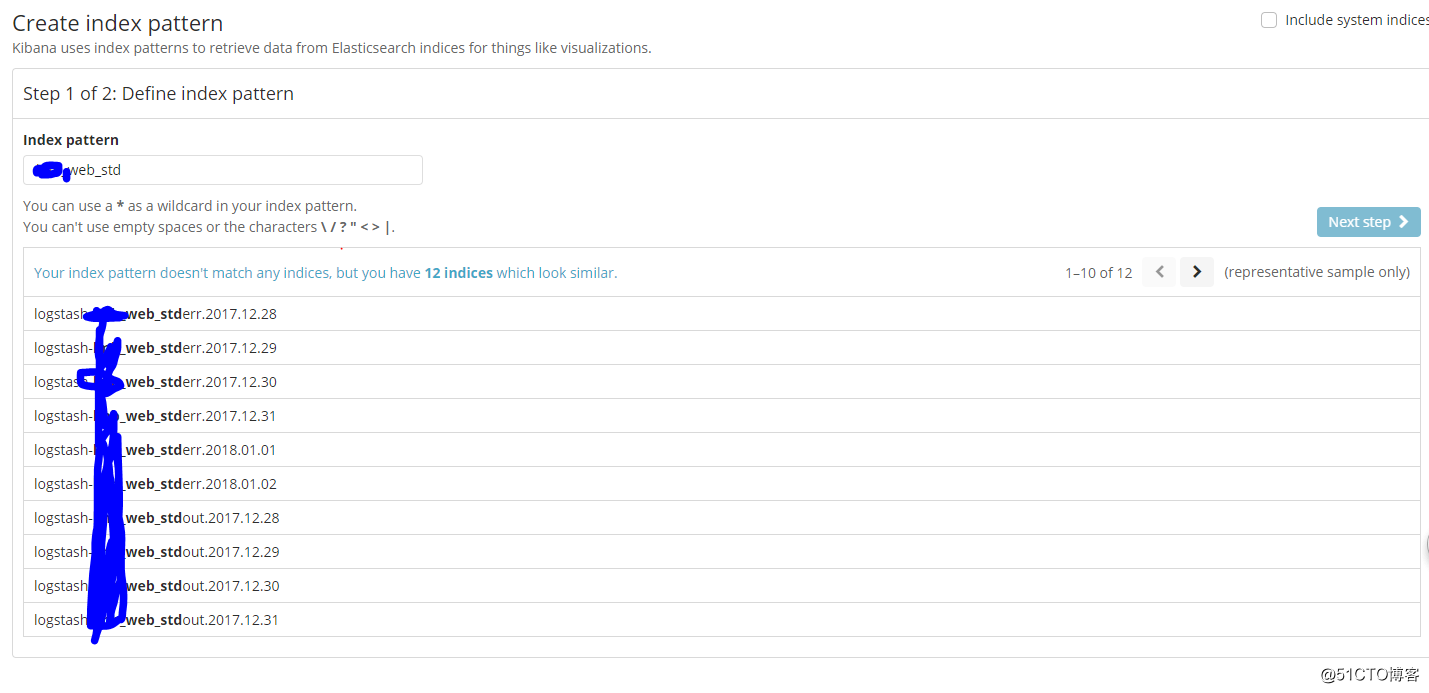
可以根据我们在logstash中配置的type,创建索引:
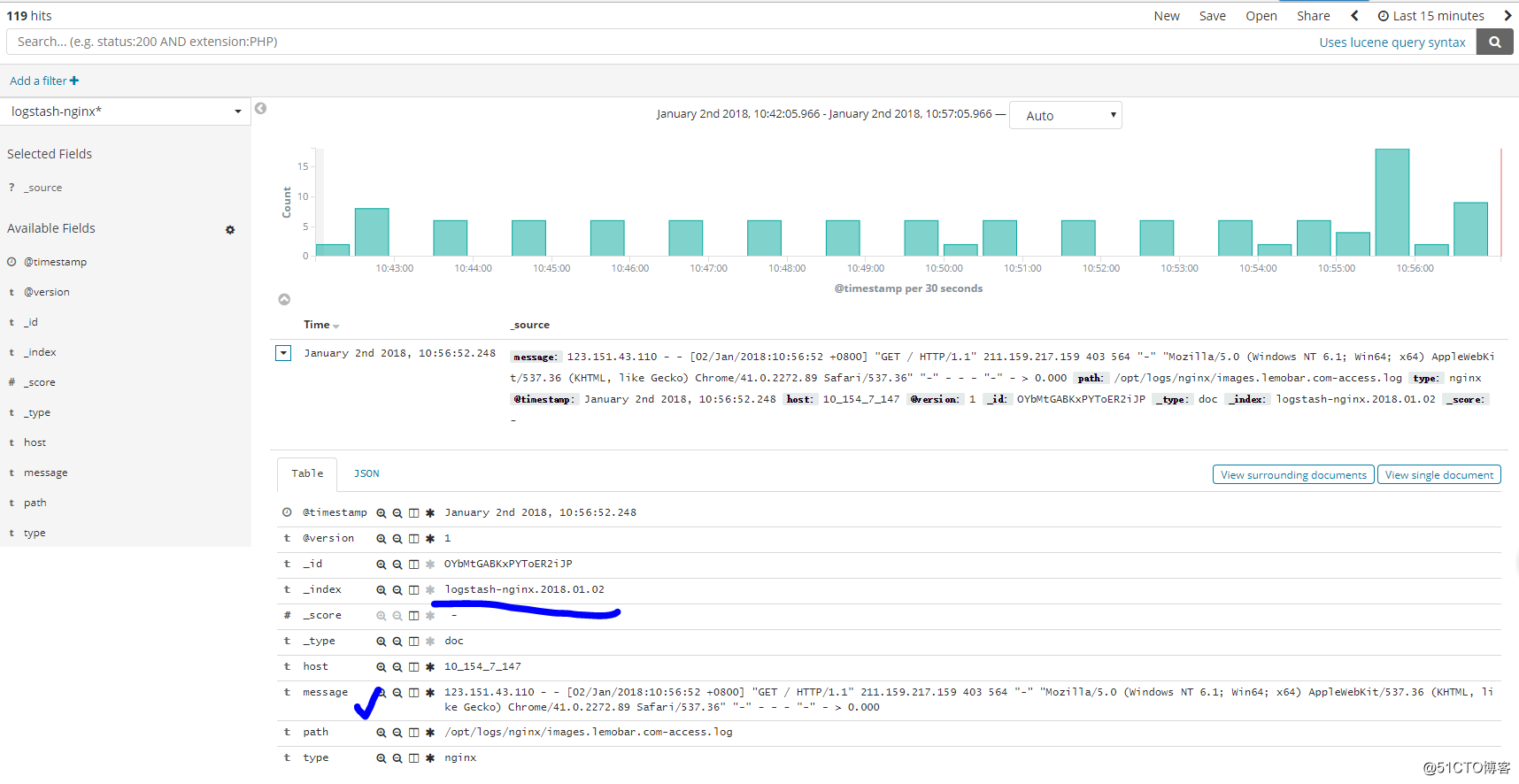
可以根据我们创建的索引,进行查看(这里查看nginx日志):
后记:
当然了,结合logstash和kibana不单单仅能实现收集日志的功能,通过对字段的匹配、筛选以及结合kibana的图标功能,能对我们想要的字段进行分析,实现相应的数据报表等。
ELK日志收集平台部署的更多相关文章
- FILEBEAT+ELK日志收集平台搭建流程
filebeat+elk日志收集平台搭建流程 1. 整体简介: 模式:单机 平台:Linux - centos - 7 ELK:elasticsearch.logstash.kiban ...
- ELK+Kafka 企业日志收集平台(一)
背景: 最近线上上了ELK,但是只用了一台Redis在中间作为消息队列,以减轻前端es集群的压力,Redis的集群解决方案暂时没有接触过,并且Redis作为消息队列并不是它的强项:所以最近将Redis ...
- 利用ELK构建一个小型的日志收集平台
利用ELK构建一个小型日志收集平台 伴随着应用以及集群的扩展,查看日志的方式总是不方便,我们希望可以有一个便于我们查询及提醒功能的平台:那么首先需要剖析有几步呢? 格式定义 --> 日志收集 - ...
- ELK日志监控平台安装部署简介--Elasticsearch安装部署
最近由于工作需要,需要搭建一个ELK日志监控平台,本次采用Filebeat(采集数据)+Elasticsearch(建立索引)+Kibana(展示)架构,实现日志搜索展示功能. 一.安装环境描述: 1 ...
- elk日志分析平台安装
ELK安装 前言 什么是ELK? 通俗来讲,ELK是由Elasticsearch.Logstash.Kibana 三个开源软件的组成的一个组合体,这三个软件当中,每个软件用于完成不同的功能,ELK 又 ...
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
笔记内容:搭建ELK日志分析平台(上)-- ELK介绍及搭建 Elasticsearch 分布式集群笔记日期:2018-03-02 27.1 ELK介绍 27.2 ELK安装准备工作 27.3 安装e ...
- ELK日志分析平台.1-搭建
ELK日志分析平台.1-搭建 2017-12-28 | admin 一.简介1.核心组成 ELK由Elasticsearch.Logstash和Kibana三部分组件组成: Elastic ...
- ELK日志分析平台
ELK日志分析平台 ELK(1): ELK-简介 ELK(2): ELK-安装环境和安装包 ELK(3): ELK-安装elasticsearch ELK(4): ELK-安装logstash ...
- 【转】flume+kafka+zookeeper 日志收集平台的搭建
from:https://my.oschina.net/jastme/blog/600573 flume+kafka+zookeeper 日志收集平台的搭建 收藏 jastme 发表于 10个月前 阅 ...
随机推荐
- Android项目中的各个模块框架设计
作为Android开发,现对项目开发中的各个模块搭建,梳理如下: Android UI框架,开发人员需要达到专家级 网络框架 浏览框架 图片加载框架 图片裁剪压缩工具类 客户端并发框架 线程池设计 ( ...
- WebService之CXF注解之五(配置文件)
1.web.xml <?xml version="1.0" encoding="UTF-8"?> <web-app version=" ...
- web开发中对缓存的使用
很久没有发表随笔了,最近工作不是太忙,抽点时间 给大家谈谈缓存吧 ; 在我从事web开发的几年实践中 接触了缓存技术 也是比较多的,在最初的 项目当中 我们用到 hibernate 的 一二级缓存, ...
- BFS POJ2251 Dungeon Master
B - Dungeon Master Time Limit:1000MS Memory Limit:65536KB 64bit IO Format:%I64d & %I64u ...
- 【转载】[ORACLE]详解not in与not exists的区别与用法
在网上搜了下关于oracle中not exists和not in性能的比较,发现没有描述的太全面的,可能是问题太简单了,达人们都不屑于解释吧.于是自己花了点时间,试图把这个问题简单描述清楚,其实归根结 ...
- google浏览器插件推荐
http://www.tuicool.com/articles/eQ32Ur http://blog.jobbole.com/1386/ https://www.oschina.net/news/46 ...
- hdu5988 Coding Contest
首先这是个费用流,用log转乘法为加法,外加模板的修改,需加eps 下面是废话,最好别看 闲来无事(鼓起勇气)写这篇博客 这是个自带影像回访的题目 青岛的炼铜之旅,大学的acm生涯就这样结束了.或许还 ...
- hdu5798 Stabilization
温习一下多校的题目 这题主要抓住一点,亦或值的贡献是固定的 所以按位搜索即可 #include<bits/stdc++.h> using namespace std; typedef lo ...
- 【BZOJ3931】【CQOI2015】网络吞吐量(最短路,网络流)
[BZOJ3931][CQOI2015]网络吞吐量(最短路,网络流) 题面 跑到BZOJ上去看把 题解 网络流模板题??? SPFA跑出最短路,重新建边后 直接Dinic就行了 大火题嗷... #in ...
- 【ZJOI2010】网络扩容
费用流+最大流 先一遍最大流 再所有边扩容,新加节点限制扩容量k # include <bits/stdc++.h> # define IL inline # define RG regi ...