python 堆排序
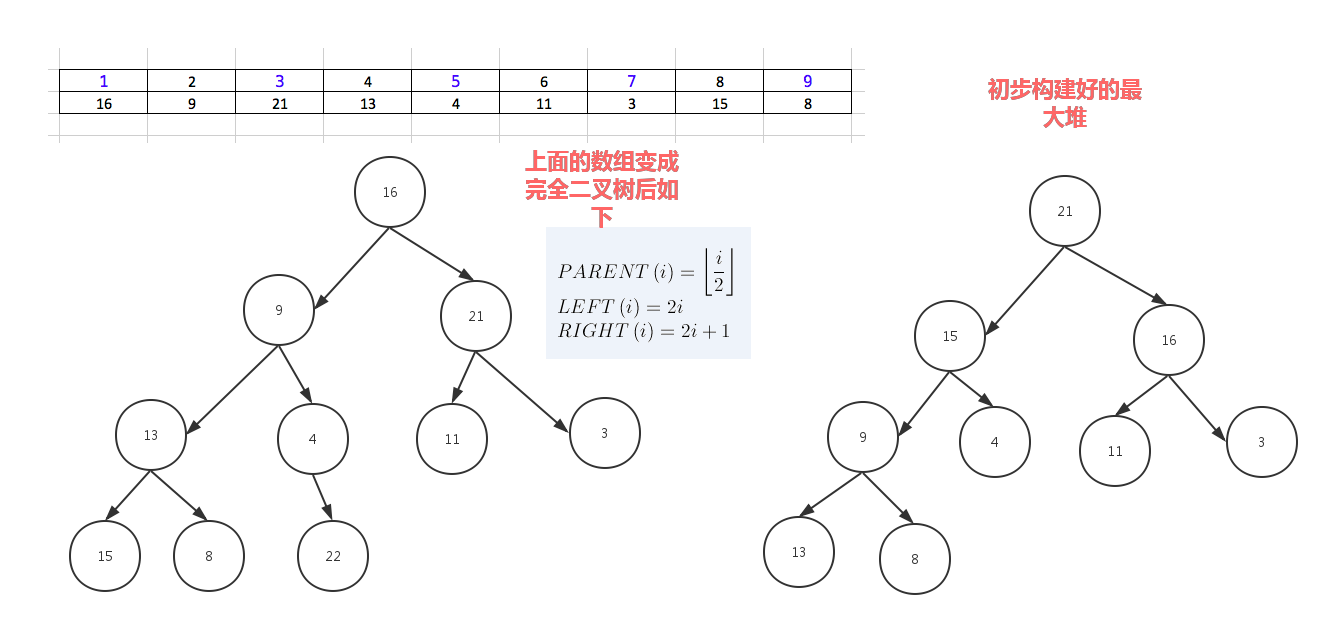
堆排序就是把堆顶的最大数取出,
将剩余的堆继续调整为最大堆,具体过程在第二块有介绍,以递归实现
剩余部分调整为最大堆后,再次将堆顶的最大数取出,再将剩余部分调整为最大堆,这个过程持续到剩余数只有一个时结束
dataset = [16,9,21,3,13,14,23,6,4,11,3,15,99,8,22] for i in range(len(dataset)-1,0,-1):
print("-------",dataset[0:i+1],len(dataset),i)
#for index in range(int(len(dataset)/2),0,-1):
for index in range(int((i+1)/2),0,-1):
print(index)
p_index = index l_child_index = p_index *2 - 1
r_child_index = p_index *2
print("l index",l_child_index,'r index',r_child_index)
p_node = dataset[p_index-1]
left_child = dataset[l_child_index] if p_node < left_child: # switch p_node with left child
dataset[p_index - 1], dataset[l_child_index] = left_child, p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1] if r_child_index < len(dataset[0:i+1]): #avoid right out of list index range
right_child = dataset[r_child_index]
print(p_index,p_node,left_child,right_child)
if p_node < right_child: #swith p_node with right child
dataset[p_index - 1] , dataset[r_child_index] = right_child,p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1] else:
print("p node [%s] has no right child" % p_node) #最后这个列表的第一值就是最大堆的值,把这个最大值放到列表最后一个, 把神剩余的列表再调整为最大堆 print("switch i index", i, dataset[0], dataset[i] )
print("before switch",dataset[0:i+1])
dataset[0],dataset[i] = dataset[i],dataset[0]
print(dataset)
堆排序详解:http://www.cnblogs.com/0zcl/p/6737944.html
python 堆排序的更多相关文章
- python堆排序
堆是完全二叉树 子树是不相交的 度 节点拥有子树的个数 满二叉树: 每个节点上都有子节点(除了叶子节点) 完全二叉树: 叶子结点在倒数第一层和第二层,最下层的叶子结点集中在树的左部 ,在右边的话,左子 ...
- python堆排序实现TOPK问题
# 构建小顶堆跳转def sift(li, low, higt): tmp = li[low] i = low j = 2 * i + 1 while j <= higt: # 情况2:i已经是 ...
- python3数据结构与算法
python内置的数据结构包括:列表(list).集合(set).字典(dictionary),一般情况下我们可以直接使用这些数据结构,但通常我们还需要考虑比如搜索.排序.排列以及赛选等一些常见的问题 ...
- 排序NB三人组
排序NB三人组 快速排序,堆排序,归并排序 1.快速排序 方法其实很简单:分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”.先从右往左找一个小于6的数,再从左往 ...
- Python3 实例
一直以来,总想写些什么,但不知从何处落笔. 今儿个仓促,也不知道怎么写,就把手里练习过的例子,整理了一下. 希望对初学者有用,都是非常基础的例子,很适合初练. 好了,Follow me. 一.Pyth ...
- 数据结构:堆排序 (python版) 小顶堆实现从大到小排序 | 大顶堆实现从小到大排序
#!/usr/bin/env python # -*- coding:utf-8 -*- ''' Author: Minion-Xu 小堆序实现从大到小排序,大堆序实现从小到大排序 重点的地方:小堆序 ...
- 你需要知道的九大排序算法【Python实现】之堆排序
六.堆排序 堆排序是一种树形选择排序,是对直接选择排序的有效改进. 堆的定义下:具有n个元素的序列 (h1,h2,...,hn),当且仅当满足(hi>=h2i,hi>=2i+1)或(h ...
- python下实现二叉堆以及堆排序
python下实现二叉堆以及堆排序 堆是一种特殊的树形结构, 堆中的数据存储满足一定的堆序.堆排序是一种选择排序, 其算法复杂度, 时间复杂度相对于其他的排序算法都有很大的优势. 堆分为大头堆和小头堆 ...
- 高速排序,归并排序,堆排序python实现
高速排序的时间复杂度最好情况下为O(n*logn),最坏情况下为O(n^2),平均情况下为O(n*logn),是不稳定的排序 归并排序的时间复杂度最好情况下为O(n*logn),最坏情况下为O(n*l ...
随机推荐
- cisco linksys ea3500 刷机 openwrt
家中router改造成千兆华为A1,淘汰下来的cisco linksys ea3500 终于可以去刷机 openwrt,尽情折腾啦! 分享步骤: 准备文件 https://archive.openw ...
- 洛谷P3402 【模板】可持久化并查集(可持久化线段树,线段树)
orz TPLY 巨佬,题解讲的挺好的. 这里重点梳理一下思路,做一个小小的补充吧. 写可持久化线段树,叶子节点维护每个位置的fa,利用每次只更新一个节点的特性,每次插入\(logN\)个节点,这一部 ...
- [HNOI2008]水平可见直线
按斜率排序后画个图,用单调栈维护这个半平面交 # include <bits/stdc++.h> # define IL inline # define RG register # def ...
- Mybatis【一对多、多对一、多对多】知识要点
Mybatis[多表连接] 我们在学习Hibernate的时候,如果表涉及到两张的话,那么我们是在映射文件中使用<set>..<many-to-one>等标签将其的映射属性关联 ...
- 进程互斥 Peterson算法
转自http://blog.csdn.net/l294265421/article/details/46674847 假设有两个进程需要互斥的访问某一个临界区. Peterson算法的形式如下: en ...
- Json技术使用代码示例
json格式细节1 JSON(JavaScript Object Notation)一种简单的数据格式,比xml更轻巧.JSON是JavaScript原生格式,这意味着在JavaScript中处理J ...
- Liveness 探测 - 每天5分钟玩转 Docker 容器技术(143)
Liveness 探测让用户可以自定义判断容器是否健康的条件.如果探测失败,Kubernetes 就会重启容器. 还是举例说明,创建如下 Pod: 启动进程首先创建文件 /tmp/healthy,30 ...
- MVC4不支持EF6解决方案 && Nuget控制台操作说明
问题背景:MVC4不支持EF6,所以要把EF6卸载然后安装EF5.只能降低版本EF5+MVC4或者EF6+MVC5; 这时候: Uninstall-Package EntityFramework -F ...
- JavaScript编码规范(1)
参考的是百度公司的JS规范,分为两部分.这是第一部分 [建议] JavaScript 文件使用无 BOM 的 UTF-8 编码. 空格 [强制] 二元运算符两侧必须有一个空格,一元运算符与操作对象之间 ...
- centos6.5的开机自动部署出现unsupported hardware detected
author:headsen chen date : 2017-12-01 14:52:50 . notice:created by headsen chen,if you copy or tr ...