Spark-1.X编译构建及配置安装
前提条件(环境要求)
jdk版本:1.7+
scala版本:1.10.4+
maven版本:3.3.3+
本博客中使用的软件版本
spark版本:spark-1.6.1.tar.gz(源码)
jdk版本:jdk-8u151-linux-x64.tar.gz
maven版本:apache-maven-3.3.9.tar.gz
scala版本:scala-2.10.4.tgz
以上软件都可以到官网下载
本文章约束两个目录
/opt/softwares 安装包
/opt/modules 安装的目录
编译方式:
打包编译make-distribution.sh
一、环境配置
1、将spark、jdk、maven、scala软件包上传到Linux系统指定的目录:/opt/softwares/
2、maven安装与配置
tar -zxvf apache-maven-3.3.9.tar.gz -C /opt/modules
在/etc/profile配置文件中最底部配置以下信息
#MAVEN#
export MAVEN_HOME=/opt/modules/apache-maven-3.3.9
export PATH=$PATH:$MAVEN_HOME/bin
3 、java安装与配置
tar -zxvf jdk-8u151-linux-x64.tar.gz -C /opt/modules
在/etc/profile配置文件中最底部配置以下信息
#JAVA_HOME#
export JAVA_HOME=/opt/modules/jdk1.8.0_151
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
4、scala安装与配置
tar -zxvf scala-2.10.4.tgz -C /opt/modules
在/etc/profile配置文件中最底部配置以下信息
#scala#
export SCALA_HOME=/opt/modules/scala-2.10.4
export PATH=$PATH:$SCALA_HOME/bin
5、maven仓库配置
将repository-1.6.1.zip解压到~/.m2文件夹中
6、解压spark源码包
tar -zxvf spark-1.6.1.tar.gz -C /opt/modules
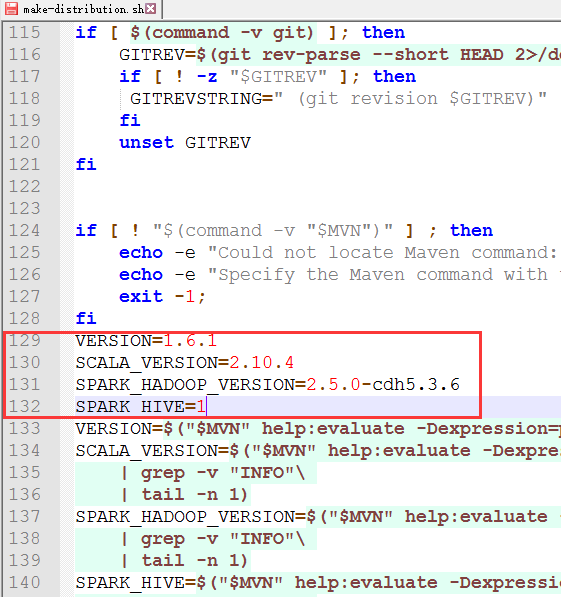
7、修改make-distribution.sh文件内容(在/opt/modules/spark-1.6.1目录中)
在129行添加以下内容
VERSION=1.6.1
SCALA_VERSION=2.10.4
SPARK_HADOOP_VERSION=2.5.0-cdh5.3.6
SPARK_HIVE=1
note:
SCALA_VERSION配置上你的scala的版本, 可能是2.10.x 或者2.11.x
SPARK_HADOOP_VERSION配置上你的hadoop版本
SPARK_HIVE 1表示需要将hive的打包进去, 非1数字表示不打包hive
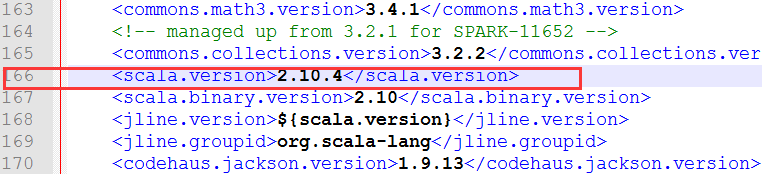
8、修改pom.xml文件 (在/opt/modules/spark-1.6.1目录中)
在166行 scala版本修改成你对应的版本 我这里是修改成 2.10.4
在2522行 scala版本修改成你对应的版本 我这里是修改成 2.10.4

9、添加依赖服务文件
前提:使用的scala版本是2.10.4,pom.xml文件中也进行了修改
复制scala-2.10.4.tgz和zinc-0.3.5.3.tgz到spark根目录的build文件夹中, 并解压
10、编译spark
在spark目录中执行命令
./make-distribution.sh --tgz \
-Phadoop-2.4 \
-Dhadoop.version=2.5.0-cdh5.3.6 \
-Pyarn \
-Phive -Phive-thriftserver
11、最终spark编译成功标志
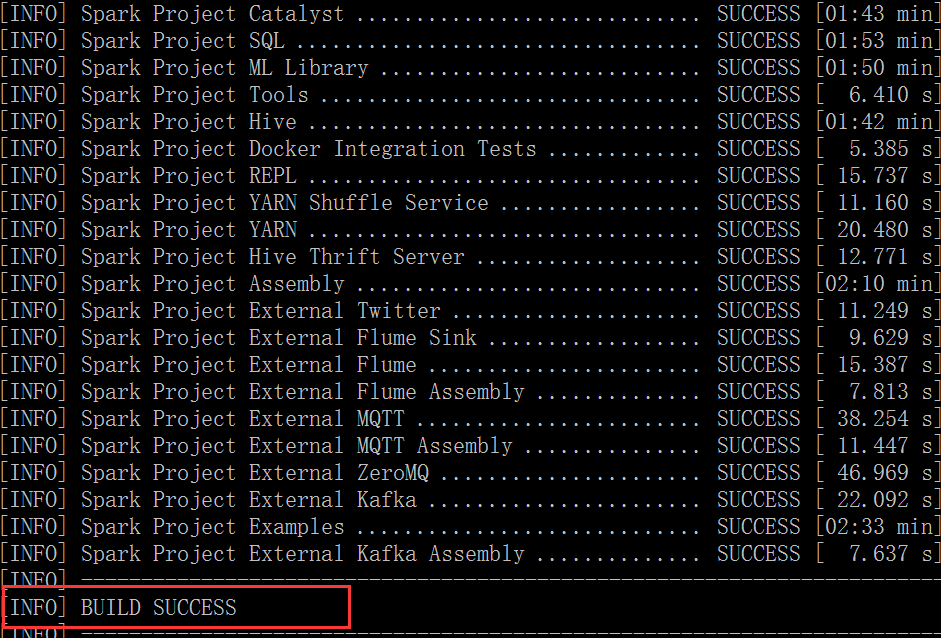
12、需要注意的几点
1)如果maven不是国内的镜像下载会比较慢 ,建议改成国内镜像
配置镜像(修改settings.xml文件)
<mirror>
<id>aliyun</id>
<mirrorOf>central</mirrorOf>
<name>aliyun repository</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</mirror>
<mirror> <!– cdh 版本编译 可选指定-->
<id>cloudera</id>
<mirrorOf>central</mirrorOf>
<name>cloudera repository</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</mirror>
2)配置域名解析服务器
# vi /etc/resolv.conf
内容:
nameserver 8.8.8.8
nameserver 8.8.4.4
3)编译可能出现的问题
在编译的过程中,可能卡死,然后不进行编译的情况出现,如果超过十分钟没有动静的话,可以考虑是否是编译出现问题。问题出现
原因是:网络不好、机器内存不够、其他原因。解决方案:
1. 关闭编译的进程。直接退出当前会话,然后从新进入在编译。
2. 添加虚拟机内存(最好4G+),重启虚拟机再编译
Spark-1.X编译构建及配置安装的更多相关文章
- wxwidgets编译及环境配置
wxwidgets编译及环境配置 安装步骤: 到www.CodeBlocks.org下载并安装CodeBlocks,最好下载MinGW版本的,可以省掉安装和配置GCC的麻烦. 到www.wxWidge ...
- wxWidgets的安装编译、相关配置、问题分析处理
wxWidgets的安装编译.相关配置.问题分析处理 一.介绍部分 (win7 下的 GUI 效果图见 本篇文章的最后部分截图2张) wxWidgets是一个开源的跨平台的C++构架库(framewo ...
- oozie配置安装与原理
概述 当前开源的hadoop任务工作流管理主要有oozie和Azkaban,本文先介绍oozie的配置安装与基本运行原理. 配置安装 (参考https://segmentfault.com/a/11 ...
- pbuilder编译构建工具分析
1. 简介 pbuilder(personal Debian package builder)是ubuntu环境下维护debian包的专业工具,能够为每个deb包创建纯净的编译构建环境,自动解析和安装 ...
- 《Linux操作系统编译构建指南》
在线阅读地址:http://www.doc88.com/p-5126905896771.html Linux编译构建定制qq群: 521902245 文件夹...0 前言...3 第零章 绪论...5 ...
- Linux 的软件管理及配置 - 安装、卸载、升级、依赖
1. 对比:Windows 和 Linux 上软件的安装与卸载 大部分 Linux 使用者都是从 Windows 转过来的,先对这俩做个对比,有助理解. 就像在 Windows 下,很多软件也有安装版 ...
- 如何在Idea中编译构建Spring Framework 5.x
如何在Idea中编译构建Spring Framework 5.x 安装配置Gradle(略) 下载源码:git clone https://github.com/spring-projects/spr ...
- Spark历险记之编译和远程任务提交
Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架.Spark在2013年6月进入Apach ...
- 分布式文件系统 - FastDFS 在 CentOS 下配置安装部署
少啰嗦,直接装 看过上一篇分布式文件系统 - FastDFS 简单了解一下的朋友应该知道,本次安装是使用目前余庆老师开源的最新 V5.05 版本,是余庆老师放在 Github 上的,和目前你能在网络上 ...
随机推荐
- Defraggler磁盘碎片整理工具,让你的电脑读写速度更快
相信大家都听说过磁盘碎片整理吧,所谓磁盘碎片,通俗的来说,就是指计算机中的各种文件最开始在磁盘中存储的时候地址都是连在一起的,但是随着文件 的多次读写,或者说多次的移动复制等操作,这些文件在磁盘中的地 ...
- 软件测试第二周作业 WordCount
本人github地址: https://github.com/wenthehandsome23 psp阶段 预估耗时 (分钟) 实际耗时 (分钟) 计划 30 10 估计这个任务需要多少时间 20 ...
- Cloudera Manager及CDH最新版本安装全程记录
大家都知道,Apache Hadoop的配置很繁琐,而且很零散,为此Cloudera公司提供了Clouder Manager工具,而且还封装了Apache Hadoop,flume,spark,hiv ...
- MySQL聚集索引和非聚集索引
索引分为聚集索引和非聚集索引,mysql中不同的存储引擎对索引的底层实现可能会不同,这里只关注mysql的默认存储引擎InnoDB. 利用下面的命令可以查看默认的存储引擎 show variables ...
- 笔记:Maven 私服 Nexus 权限控制
Nexus 用户 Nexus 预定义了三个用户,这三个用户对应了三个权限级别: admin:该用户拥有对Nexus服务的完全控制,默认密码为 admin123,以下为admin用户的角色树 deplo ...
- return false与return true的区别
<a href="http://www.baidu.com" onclick="alert(11);return true;alert(22)">链 ...
- 解决Hystrix Dashboard 一直是Loading ...的情况
Hystrix是什么 Hystrix 能使你的系统在出现依赖服务失效的时候,通过隔离系统所依赖的服务,防止服务级联失败,同时提供失败回退机制,更优雅地应对失效,并使你的系统能更快地从异常中恢复. Hy ...
- Java基础学习笔记十九 IO
File IO概述 回想之前写过的程序,数据都是在内存中,一旦程序运行结束,这些数据都没有了,等下次再想使用这些数据,可是已经没有了.那怎么办呢?能不能把运算完的数据都保存下来,下次程序启动的时候,再 ...
- swift textview禁止用户使用复制粘贴
//自定义一个TextView class Own_TextView: UITextView { override func caretRect(for position: UITextPositio ...
- C语言第三次博客作业
一.PTA实验作业 1 1.实验代码 int i,N; char sex; float high; scanf("%d",&N); for(i =1;i <=N;i ...