Solr 17 - Solr的时间为什么比本地少8小时 (附修改方法)
1 为什么少8小时
(1) 原因:
Solr服务中默认使用的是UTC时间, 而中国本地时间为东八时区, 即比UTC标准时间多8小时.
(2) 示例:
① 中国内地服务器时间为
2018-10-10 20:00:00, 系统将当前时间添加到Solr索引中时, Solr底层发现此时间的格式为UTC + 8, 它将对该时间减去8小时处理, 然后建立相关索引.
② 在查询上述添加的时间时, Solr直接将索引信息返回, 变为:2018-10-10T12:00:00Z==> 时间少了8小时.
(3) 不同的时间格式:
- UT, Universal Time, 世界时: 是基于天体观察计算出来的时间, 是指英国格林尼治所在地的标准时间. 由于天体运行的一些不确定性(比如地球的自转并不是匀速的, 而且正在缓慢减速), 所以UT时间并不均匀.
- UTC, Universal Time Coordinate: 协调世界时, 是基于原子时钟的时间, 是均匀的时间. 为了与UT时间保持较小的差距, UTC体系中增加了闰秒, 即某些年份的最后1分钟有61秒.
- GMT, Greenwish Mean Time, 格林尼治标准时间: 是人们对UTC的另一种称法. 本初子午线被定义为英国伦敦郊区的皇家格林尼治天文台所在的经线, 此前人们将此地的时间当做标准时间, 但后来发现基于地球的时间并不准确, 在提出UTC概念后, 人们仍然自然地使用GMT来表达时间, 而此时的GMT == UTC.
2 如何查看Solr的时区
通过Solr Admin (Solr Web界面)查看:
(1) 进入Solr Admin, 点击左侧的Java Properties菜单, 进入Java属性设置页面;
(2) 下拉右侧的滚动条至底部, 可以看到时区属性, 如下图所示:
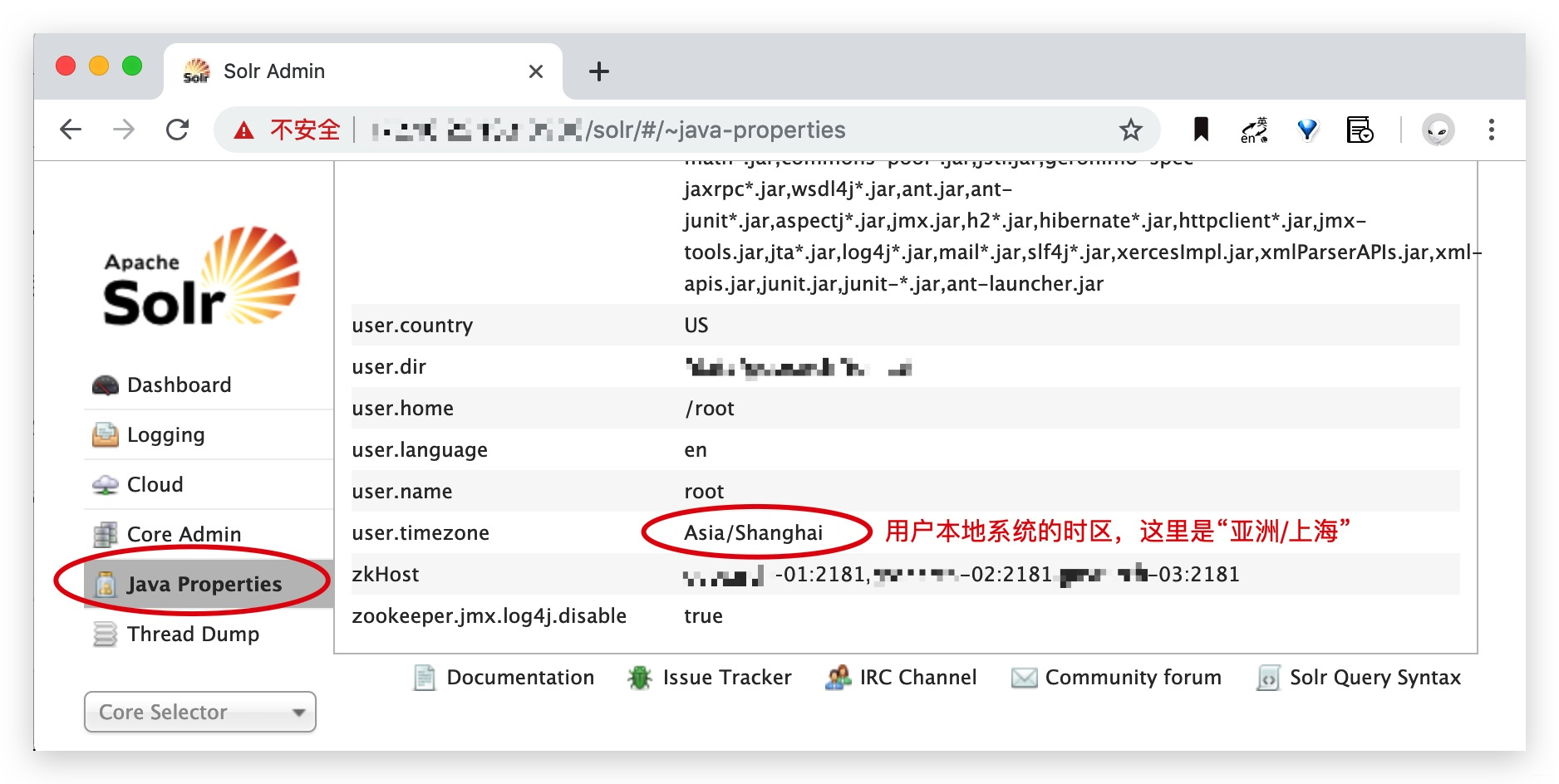
说明: 默认的时区为UTC, 上图是已经修改后的东八区(GMT+8).
3 修改Solr的时区
3.1 Solr从数据库中同步数据的原理
① 我们知道, Solr中的数据源有很多是类似于MySQL的关系型数据库, 也就是Solr通过其DIH(Data Import Handler)处理;
② Solr在更新数据时, 会记录这些数据的最后更新时间戳, 保存在Collection/conf目录下, 与db-data-config.xml文件同级, 文件内容类似于:
#Thu Jan 24 15:03:58 CST 2019
_delta.last_index_time=2019-01-08T05\:48\:21Z
_full.last_index_time=2019-01-24T07\:03\:37Z
last_index_time=2019-01-24T07\:03\:37Z
③ 在向MySQL、MongoDB等数据库中写入数据时, 添加类似于CreateTime的字段, 用于记录数据的入库时间戳;
④ 通过比较Solr和数据库的更新时间戳, 完成对数据是否需要增量同步的判断, 从而实现数据更新. 对比方式类似于:
<!-- MySQL中增量同步数据的配置类似于 -->
<entity name="BookShop_delta"
query="SELECT ID, Name, CreateTime FROM BookShop
WHERE CreateTime >= '${dataimporter.last_index_time}'" pk="ID">
<field column="ID" name="ID" />
<!-- ... -->
</entity> <!-- MongoDB中增量导入数据的配置类似于 -->
<entity name="_delta" processor="MongoEntityProcessor"
query="{'CreateTime': {'$gte': ISODate('${dih.last_index_time}')}}"
collection="BookShop" project="{_id:0, ID:1, Name:1, CreateTime:1}"
datasource="ShopMongo" transformer="MongoMapperTransformer" >
<field column="ID" name="ID" />
<!-- ... -->
</entity>
3.2 为什么要修改时区
由上述分析可知, 修改时区的原因主要是: 方便与数据库中数据的自动同步.
一般情况下, MySQL等数据库服务器的时区都与实际时区一致, 也就是东八区(GMT+8), 而Solr默认的时区是UTC, 与东八区(GMT+8)相差8个小时.
这种差距导致我们无法直接根据Solr的更新时间戳和MySQL等数据库的更新时间戳进行比较, 从而使得数据的导入出现问题.
==> 所以需要修改Solr的时区.
3.3 如何修改时区
Solr的时区属性所在配置文件, 在${SOLR_HOME}/bin下:
solr.in.sh是Linux系统下的启动脚本,solr.in.cmd是Windows系统下的启动脚本.
以Linux系统为例, 编辑solr.in.sh文件:
vim /data/solr-cloud/solr-4.10.4/bin/solr.in.sh
找到SOLR_TIMEZONE的相关配置: SOLR_TIMEZONE="UTC", 可以看出默认的时区是UTC, 而且被注释掉了. 可将其修改为:
SOLR_TIMEZONE="UTC+8"
保存退出后, 重启Solr服务, 然后再次进入Solr Admin管理界面, 查看Java Properties菜单, 即可发现时区已经修改成功.
参考资料
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.
Solr 17 - Solr的时间为什么比本地少8小时 (附修改方法)的更多相关文章
- logstash 默认时间少8小时的修改办法
logstash 的配置文件添加 filter { ruby { code => "event.set('timestamp', event.get('@timestamp').tim ...
- Solr 07 - Solr从MySQL数据库中导入数据 (Solr DIH的使用示例)
目录 1 加入数据导入处理器的jar包 2 加入数据库驱动包 3 配置solrconfig.xml文件 3.1 配置lib标签 - 加入驱动jar包 3.2 配置requestHandler标签 - ...
- Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)
目录 1 配置中文分词器 1.1 准备IK中文分词器 1.2 配置schema.xml文件 1.3 重启Tomcat并测试 2 配置业务域 2.1 准备商品数据 2.2 配置商品业务域 2.3 配置s ...
- Solr 05 - Solr Web管理界面的基本使用
目录 1 Dashboard - 仪表盘 2 Logging - 日志信息 3 CoreAdmin - Solr核心 4 Java Properties - Java参数 5 Thread Dump ...
- Solr 03 - Solr的模式设计与优化 - 最详细的schema.xml模式文件解读
目录 1 关于schema.xml文件 2 解读schema.xml文件 2.1 field - 配置域 2.2 fieldType - 配置域类型 2.3 copyField - 配置复制域 2.4 ...
- Solr记录-solr介绍及配置
Solr是一个开源搜索平台,用于构建搜索应用程序. 它建立在Lucene(全文搜索引擎)之上. Solr是企业级的,快速的和高度可扩展的. 使用Solr构建的应用程序非常复杂,可提供高性能. 为了在C ...
- Solr 11 - Solr集群模式的部署(基于Solr 4.10.4搭建SolrCloud)
目录 1 SolrCloud结构说明 2 环境的安装 2.1 环境说明 2.2 部署并启动ZooKeeper集群 2.3 部署Solr单机服务 2.4 添加Solr的索引库 3 部署Solr集群服务( ...
- Solr记录-solr内核与索引
Solr核心(内核) Solr核心(Core)是Lucene索引的运行实例,包含使用它所需的所有Solr配置文件.我们需要创建一个Solr Core来执行索引和分析等操作. Solr应用程序可以包含一 ...
- Solr记录-solr基础内容
Solr架构(体系结构) 在本章中,我们将讨论Apache Solr的架构. 下图显示了Apache Solr的体系结构的框图. Solr架构 - 构件块以下是Apache Solr的主要构建块(组件 ...
随机推荐
- Linux 系统化学习系列文章总目录(持续更新中)
本页内容都是本人系统化学习Linux 时整理出来的.这些文章中,绝大多数命令类内容都是翻译.整理man或info文档总结出来的,所以相对都比较完整. 本人的写作方式.风格也可能会让朋友一看就恶心到直接 ...
- Java c# 跨语言Json反序列化首字母大小写问题
C#标准是首字母大写,Java规范是首字母小写,在序列化成Json之后,反序列化会出现反序列化失败的问题.. 从C#反序列化成JavaBean的时候通过如下注解可以直接解决该问题 @JsonNamin ...
- Linnux入门之简介
一.Linux简介 Minix(教授实验) -> Linux(大三学生Linus)企鹅作为吉祥物 linux主要分为内核版本和发行版本 linux 内核版本 :官网下载:https://www. ...
- Flask入门之flask-wtf表单处理
参考文章 1. 使用 WTForms 进行表单验证 第11集 #Sample.py # coding:utf-8 from flask import Flask,render_template,re ...
- Spring 的IOC和AOP总结
Spring 的IOC和AOP IOC 1.IOC 许多应用都是通过彼此间的相互合作来实现业务逻辑的,如类A要调用类B的方法,以前我们都是在类A中,通过自身new一个类B,然后在调用类B的方法,现在我 ...
- mysql导入数据中文乱码_ubuntu
1.在ubuntu中mysql的部分编码格式不是utf-8,故在导文件的时候会出现中文乱码,Windows中编码格式为gbk,因此要修改mysql的编码方式为utf-8. 2.查看MySQL编码格式: ...
- SQL Server 2008更改数据库保存路径
本文由荒原之梦原创,原文链接:http://zhaokaifeng.com/?p=641 操作环境: WindowsXP 数据库: Microsoft SQL Server 2008 操作步骤: 选中 ...
- Javascript书籍推荐----(步步为赢)
在此分享一些高清javascript书籍,因为我也没有全部看完,所以在这只是推荐,不同的书适合不同的人,所有的书在网上均有电子书,若找不到,请在博客留言,我有大部分书籍的电子稿.希望有更多的好书分享出 ...
- tesseract-ocr识别英文和中文图片文字以及扫描图片实例讲解
本文来源:http://blog.csdn.net/wanghui2008123/article/details/37694307 本文参考http://blog.sina.com.cn/s/blog ...
- 深入理解SpringCloud之分布式配置
Spring Cloud Config Server能够统一管理配置,我们绝大多数情况都是基于git或者svn作为其配置仓库,其实SpringCloud还可以把数据库作为配置仓库,今天我们就来了解一下 ...