《深入理解 Java 虚拟机》读书笔记:晚期(运行期)优化
正文
在部分商用虚拟机(Sun HotSpot、IBM J9)中,Java 程序最初是通过解释器进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为“热点代码”。为了提高热点代码的执行效率,在运行时,虚拟机会把这些代码编译成本地机器码,并进行各种层次的优化。完成这个任务的编译器称为即时编译器(Just In Time Compiler,简称 JIT 编译器)。
Java 虚拟机规范并没有规定必须要有即时编译器存在,更没有限定或指导即时编译器如何去实现。所以即时编译器的功能完全与虚拟机的具体实现相关。
一、HotSpot 虚拟机内的即时编译器
1、解释器与编译器
许多主流的商用虚拟机(如 HotSpot、J9),都采用解释器与编译器并存的架构。
(1)解释器、编译器
当程序需要迅速启动和执行时,解释器可以首先发挥作用,省去编译的时间,立即执行。在程序运行后,随着时间的推移,编译器把越来越多的代码编译成本地代码后,可以获取更高的执行效率。
当程序运行环境中内存资源限制较大(如部分嵌入式系统),可以使用解释执行节约内存,反之可以使用编译执行提升效率。
解释器可以作为编译器激进优化时的一个“逃生门”,让编译器根据概率选择一些大多数时候都能提升运行速度的激进优化手段,当激进优化不成立时,可以通过逆优化退回到解释状态继续执行。
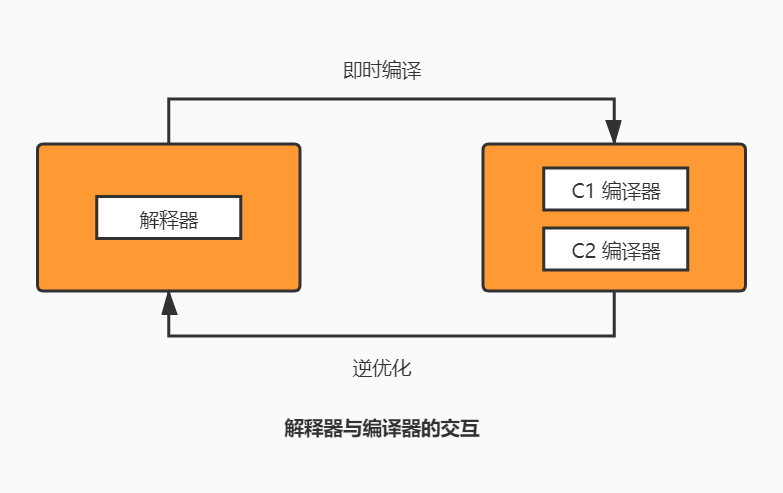
(2)C1、C2 编译器
HopSpot 虚拟机内置了两个即时编译器,分别称为 Client Compiler(C1 编译器)和 Server Compiler(C2 编译器)。默认采用解释器与其中一个编译器配合的方式工作,程序使用哪个编译器,取决于虚拟机是以 Client 模式还是 Server 模式运行。虚拟机会根据自身版本与宿主机器的硬件性能自动选择运行模式,用户也可以使用“-client”或“-server”参数强制指定虚拟机的运行模式。
(3)混合模式、解释模式与编译模式
- 混合模式:解释器与编译器搭配使用的方式。
- 解释模式:全部代码都使用解释方式执行,编译器完全不介入工作。可使用“-Xint”参数强制虚拟机运行于解释模式。
- 编译模式:优先采用编译方式执行,但是解释器仍会在编译无法进行时介入执行过程。可使用“-Xcomp”强制虚拟机运行于编译模式。
(4)分层编译
为了在程序启动响应速度与运行效率之间达到最佳平衡,HotSpot 虚拟机会逐渐启用分层编译的策略。
分层编译根据编译器编译、优化的规模与耗时,划分出不同的编译层次,其中包括:
- 第 0 层:程序解释执行,解释器不开启性能监控功能,可触发第 1 层编译。
- 第 1 层:也称 C1 编译,将字节码编译为本地代码,进行简单、可靠的优化,必要时加入性能监控的逻辑。
- 第 2 层(或 2 层以上):也称 C2 编译,也是将字节码编译为本地代码,但会启用一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。
实施分层编译后,C1、C2 编译器将会同时工作,用 C1 编译器获取更高的编译速度,用 C2 编译器获取更好的编译质量,解释执行时也无须再承担收集性能监控信息的任务。
2、编译对象与触发条件
(1)热点代码及编译对象
热点代码:
- 被多次调用的方法。
- 被多次执行的循环体。
两种热点代码的编译对象都是整个方法。第一种热点代码的编译,由于是由方法调用触发的,理所当然会以整个方法作为编译对象。第二种热点代码的编译,尽管是由循环体触发的,但编译器仍会以整个方法(而不是单独的循环体)作为编译对象。
栈上替换:
被多次执行的循环体成为热点代码时,所触发的编译。因为编译发生在方法执行过程中,因此称之为栈上替换(也称 OSR 编译),即方法栈帧还在栈上,方法就被替换了。
(2)热点探测
判断一段代码是不是热点代码,是不是需要触发即时编译,这样的行为称为热点探测。
热点探测方式:
- 基于采样的热点探测:虚拟机周期性地检查各个线程的栈顶,如果发现某个方法经常出现在栈顶,那这个方法就是“热点代码”。实现简单高效,但很难精确地确认方法的热度。
- 基于计数器的热点探测:虚拟机为每个方法(甚至是代码块)建立计数器,统计方法的执行次数,如果执行次数超过一定阈值就认为它是“热点代码”。实现麻烦,但统计结果更加精确严谨。
HotSpot 虚拟机使用的是基于计数器的热点探测方法,它为每个方法准备了两类计数器:
- 方法调用计数器:统计方法被调用的次数。
- 回边计数器:统计一个方法中循环体代码执行的次数。在字节码中遇到控制流向后跳转的指令称为“回边”。
方法调用计数器触发即时编译:
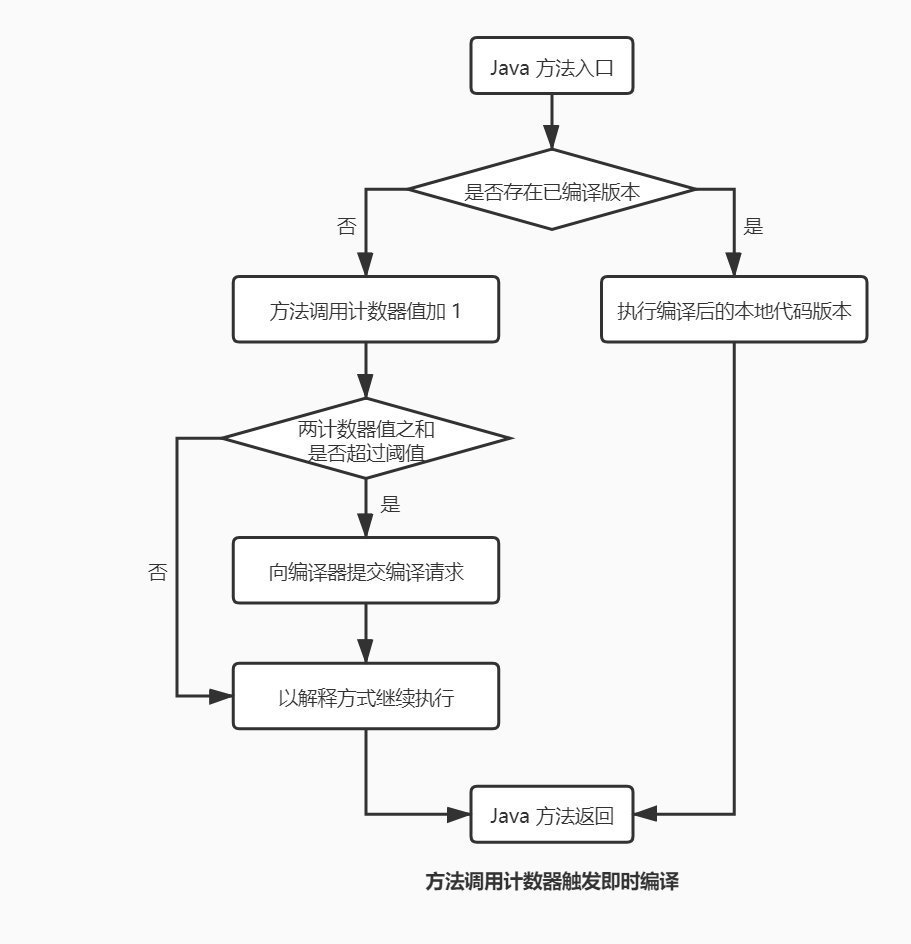
回边计数器触发即时编译:

3、编译过程
默认设置下,无论是方法调用产生的即时编译请求,还是 OSR 编译请求,虚拟机在代码编译还未完成之前,仍会按照解释方式继续执行,而编译动作则在后台的编译线程中进行。
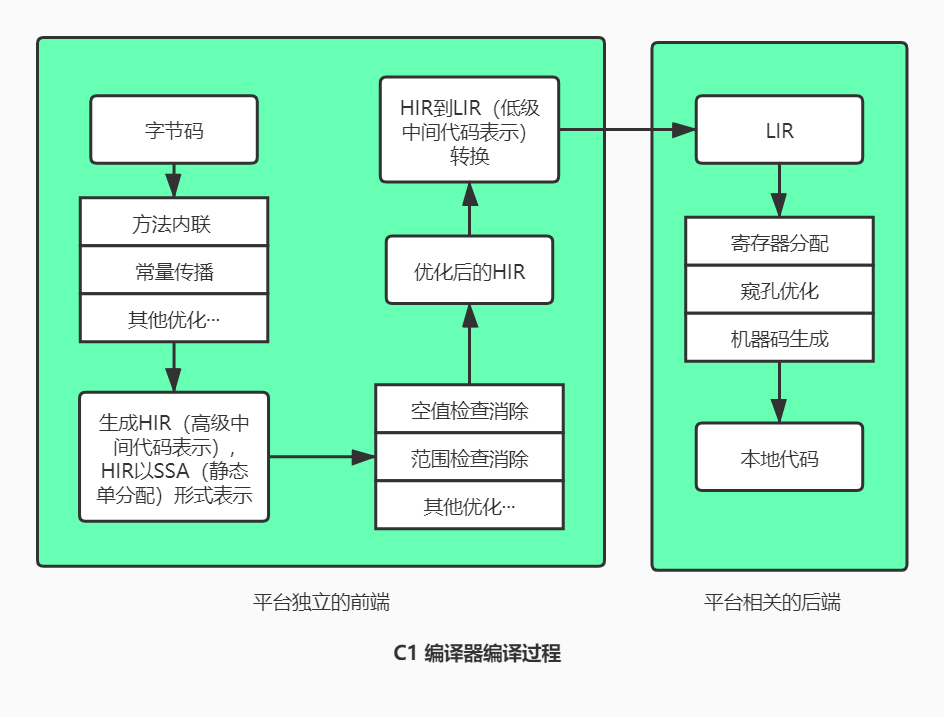
C1 编译器编译过程:
- 第一阶段:一个平台独立的前端将字节码构造成一种高级中间代码表示(HIR),HIR 使用静态单分配(SSA)的形式来代表代码值。在此之前,编译器会在字节码上进行方法内联、常量传播等优化。
- 第二阶段:一个平台相关的后端从 HIR 中产生低级中间代码表示(LIR)。在此之前,编译器会在 HIR 上进行空值检查消除、范围检查消除等优化。
- 第三阶段:平台相关的后端使用线性扫描算法,在 LIR 上分配寄存器、做窥孔优化,然后产生机器代码。
二、编译优化技术
1、公共子表达式消除
如果一个表达式 E 已经计算过了,并且从先前计算到现在 E 中所有变量的值都没有变化,那么 E 的这次出现就成了公共子表达式。对于这种表达式,没有必要再次进行计算,直接用前面计算过的表达式结果代替 E 即可。
2、数组边界检查消除
Java 语言访问数组元素时,虚拟机系统会自动进行上下界的范围检查,一旦访问超出范围,将抛出一个运行时异常:java.lang.ArrayIndexOutOfBoundsException。
数组边界检查使得程序员即便没有专门编写防御代码,也可以避免大部分的溢出攻击。但对于虚拟机的执行子系统来说,每次数组元素的读写都带有一次隐含的条件判定操作,如果程序中拥有大量数组访问代码,无疑大大增加了性能负担。
编译器可以通过数据流分析判定数组下标是否会越界,如果分析后确定不会越界,那么可以把数组的上下界检查消除。
3、方法内联
把目标方法的代码“复制”到发起调用的方法之中,避免发生真实的方法调用。
(1)类型继承关系分析
对于一个虚方法,编译期做内联的时候根本无法确定应该使用哪个方法版本,为了解决这个问题,引入了类型继承关系分析(Class Hierarchy Analysis,CHA)技术。CHA 用于确定在目前已加载的类中,某个接口是否有多于一种的实现,某个类是否存在子类、子类是否为抽象类等信息。
(2)方法内联过程
- 如果是非虚方法,直接进行内联。
- 如果是虚方法,则向 CHA 查询是否有多个目标版本。
- 如果只有一个版本,则进行守护内联。
- 如果有多个版本,则使用内联缓存完成方法内联。
守护内联:
当虚方法只有一个目标版本时,也可以进行内联,但这种内联属于激进优化,需要预留一个“逃生门”,这种内联称为守护内联。进行守护内联时,如果后续执行过程中,加载了导致继承关系发生变化的新类,则需要抛弃已经编译的代码,退回到解释状态执行,或者重新进行编译。
内联缓存:
内联缓存是一个建立在目标方法正常入口之前的缓存。它的工作原理是:在未发生方法调用前,内联缓存状态为空,第一次调用发生后,缓存记录下方法接收者的版本信息,并且每次进行方法调用时都会比较接收者版本。如果接收者版本一致,那么这个内联还可以用下去,如果不一致,说明程序使用了虚方法的多态特性,此时会取消内联,查找虚方法表进行方法分派。
4、逃逸分析
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中定义后,如果它被外部方法所引用或被外部线程访问到,那么就说这个对象发生了逃逸。
- 方法逃逸:对象被外部方法所引用,比如作为调用参数传递到其他方法中。
- 线程逃逸:对象被外部线程访问到。
如果能证明一个对象不会逃逸到方法或线程之外,也就是别的方法或线程无法通过任何途径访问到这个对象,则可能为这个变量进行一些高效的优化。
(1)栈上分配
如果确定一个对象不会逃逸出方法之外,那么可以让这个对象在栈上分配内存。这样对象所占用的内存空间就可以随栈帧出栈而销毁,从而减少了垃圾收集系统的压力。
(2)同步消除
如果确定一个变量不会逃逸出线程,那么这个变量的读写肯定不会有竞争,因此可以消除掉这个变量的线程同步措施。
(3)标量替换
如果确定一个对象不会被外部访问,并且这个对象可以被拆散的话,那么程序真正执行时可能不创建这个对象,而改为创建它的若干个被这个方法使用到的成员变量来代替,这个过程称为标量替换。
将对象拆分后,除了可以让对象的成员变量在栈上分配和读写之外,还可以为后续进一步的优化手段创建条件。
标量与聚合量:
- 标量:如果一个数据无法再分解成更小的数据来表示,则称为标量。比如 int、long 等原始数据类型。
- 聚合量:如果一个数据可以继续分解,则称为聚合量。比如 Java 对象。
《深入理解 Java 虚拟机》读书笔记:晚期(运行期)优化的更多相关文章
- 深入理解Java虚拟机 -- 读书笔记(1):JVM运行时数据区域
深入理解Java虚拟机 -- 读书笔记:JVM运行时数据区域 本文转载:http://blog.csdn.net/jubincn/article/details/8607790 本系列为<深入理 ...
- 【Todo】深入理解Java虚拟机 读书笔记
有一个在线系列地址 <深入理解Java虚拟机:JVM高级特性与最佳实践(第2版)> http://book.2cto.com/201306/25426.html 已经下载了这本书(60多M ...
- 深入理解Java虚拟机读书笔记7----晚期(运行期)优化
七 晚期(运行期)优化 1 即时编译器(JIT编译器) ---当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为“热点代码”,包括被多次调用的方法和被多次执行的循环体. ...
- 深入理解Java虚拟机读书笔记5----虚拟机字节码执行引擎
五 虚拟机字节码执行引擎 1 运行时栈帧结构 ---栈帧是用于支持虚拟机进行方法调用和方法执行的数据结构,是虚拟机运行时数据区中的虚拟机栈的栈元素. ---栈帧中存储了方法的局部变 ...
- 深入理解Java虚拟机读书笔记6----早期(编译期)优化
六 早期(编译期)优化 1 “编译期”的含义 · 可能是指一个前端编译器把*.java文件转变成*.class文件的过程,前端编译器如:Sun的Javac.Eclipse JDT中的增量式 ...
- 深入理解Java虚拟机——读书笔记
首先 强烈推荐周志明老师的这本书,真的可以说是(起码中文出版界)新手了解Java虚拟机必须人手一本的教科书!!! 第二部分自动内存管理机制 由于Java虚拟机的多线程是通过线程轮流切换并分配处理器 ...
- 深入理解Java虚拟机读书笔记8----Java内存模型与线程
八 Java内存模型与线程 1 Java内存模型 ---主要目标:定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节. ---此处的变量和J ...
- 深入理解Java虚拟机读书笔记4----虚拟机类加载机制
四 虚拟机类加载机制 1 类加载机制 ---概念:虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型. -- ...
- 深入理解Java虚拟机读书笔记3----类文件结构
三 类文件结构 1 Java虚拟机的两种中立特性 · 平台无关性 · 语言无关性 实现平台无关性和语言无关性的基础是虚拟机和字节码存储格式(Class文件). 2 Clas ...
- 深入理解Java虚拟机读书笔记1----Java内存区域与HotSpot虚拟机对象
一 Java内存区域与HotSpot虚拟机对象 1 Java技术体系.JDK.JRE? Java技术体系包括: · Java程序设计语言: · 各种硬件平台上的 ...
随机推荐
- 面向对象里is-a和has-a的含义
面向对象的核心思想是:抽象.封装.继承.多态.在实践中用的最多的术语就是 is a(是一个) ,和 has a(有一个).其实他们的意思很简单,对应面向对象设计中的两种形态继承.组合. 一.继承( i ...
- (转)SpringBoot :(has no explicit mapping for /error)
转载自:https://www.cnblogs.com/panchanggui/p/9945261.html 异常:This application has no explicit mapping f ...
- CSS每日学习笔记(2)
7.31.2019 1.CSS定位:允许你定义元素框相对于其正常位置应该出现的位置,或者相对于父元素.另一个元素甚至浏览器窗口本身的位置. CSS 有三种基本的定位机制:普通流.浮动和绝对定位.除非专 ...
- Android UI性能测试——使用 Systrace 查找问题
一 官方文档翻译 官文地址:https://developer.android.com/studio/command-line/systrace systrace命令允许您在系统级别上收集和检查所有运 ...
- swagger 报 i.s.m.parameters.AbstractSerializableParameter - Illegal DefaultValue null for parameter type integer java.lang.NumberFormatException: For input string
解决 方法 添加这两个依赖....别问我有啥子用....我也不知道..能解决问题 <dependency> <groupId>io.swagger</groupId> ...
- windows10删除用户头像
点击开始菜单,然后这里我们点击最上方的用户,弹出的界面,点击这里的更改帐户设置,大家如图进行操作,点击这里即可. 这里我们通过浏览可以修改自己的账户头像,问题是怎么删除这里使用过的账户头像呢?这里 ...
- ASP.NET Core 奇淫技巧之伪属性注入
一.前言 开局先唠嗑一下,许久未曾更新博客,一直在调整自己的状态,去年是我的本命年,或许是应验了本命年的多灾多难,过得十分不顺,不论是生活上还是工作上.还好当我度过了所谓的本命年后,许多事情都在慢慢变 ...
- PyTorch 实战-张量
Numpy 是一个非常好的框架,但是不能用 GPU 来进行数据运算. Numpy is a great framework, but it cannot utilize GPUs to acceler ...
- SpringBoot 集成多数据源
一个项目中怎么划分数据库,可以通过具体业务需求. 项目中数据源怎么如何划分,通过注解的方式@Datasource(ref="") 在方法上指定,会连接指定的数据源,这种方式比较繁琐 ...
- .NET 5 中的正则引擎性能改进(翻译)
前言 System.Text.RegularExpressions 命名空间已经在 .NET 中使用了多年,一直追溯到 .NET Framework 1.1.它在 .NET 实施本身的数百个位置中使用 ...