Hadoop基准测试(二)
Hadoop Examples
除了《Hadoop基准测试(一)》提到的测试,Hadoop还自带了一些例子,比如WordCount和TeraSort,这些例子在hadoop-examples-2.6.0-mr1-cdh5.16.1.jar和hadoop-examples.jar中。执行以下命令:
hadoop jar hadoop-examples--mr1-cdh5.16.1.jar
会列出所有的示例程序:
bash--mr1-cdh5.16.1.jar An example program must be given as the first argument. Valid program names are: aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files. aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files. bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi. dbcount: An example job that count the pageview counts from a database. distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi. grep: A map/reduce program that counts the matches of a regex in the input. join: A job that effects a join over sorted, equally partitioned datasets multifilewc: A job that counts words from several files. pentomino: A map/reduce tile laying program to find solutions to pentomino problems. pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method. randomtextwriter: A map/reduce program that writes 10GB of random textual data per node. randomwriter: A map/reduce program that writes 10GB of random data per node. secondarysort: An example defining a secondary sort to the reduce. sort: A map/reduce program that sorts the data written by the random writer. sudoku: A sudoku solver. teragen: Generate data for the terasort terasort: Run the terasort teravalidate: Checking results of terasort wordcount: A map/reduce program that counts the words in the input files. wordmean: A map/reduce program that counts the average length of the words in the input files. wordmedian: A map/reduce program that counts the median length of the words in the input files. wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
单词统计测试
进入角色hdfs创建的文件夹**,执行命令:vim words.txt,输入内容如下:
hello hadoop hbase mytest hadoop-node1 hadoop-master hadoop-node2 this is my test
执行命令:
../bin/hadoop fs -put words.txt /tmp/
将文件上传到HDFS中,如下:
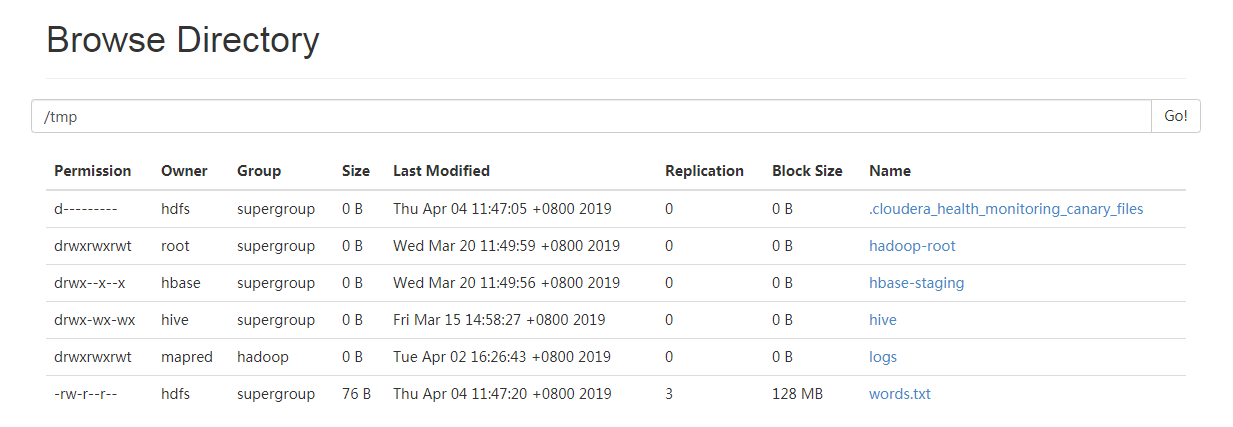
执行以下命令,使用mapreduce统计指定文件单词个数,并将结果输入到指定文件:
hadoop jar ../jars/hadoop-examples--mr1-cdh5.16.1.jar wordcount /tmp/words.txt /tmp/words_result.txt
返回如下信息:
bash--mr1-cdh5.16.1.jar wordcount /tmp/words.txt /tmp/words_result.txt
// :: INFO client.RMProxy: Connecting to ResourceManager at node1/
// :: INFO input.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1552358721447_0060
// :: INFO impl.YarnClientImpl: Submitted application application_1552358721447_0060
// :: INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1552358721447_0060/
// :: INFO mapreduce.Job: Running job: job_1552358721447_0060
// :: INFO mapreduce.Job: Job job_1552358721447_0060 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
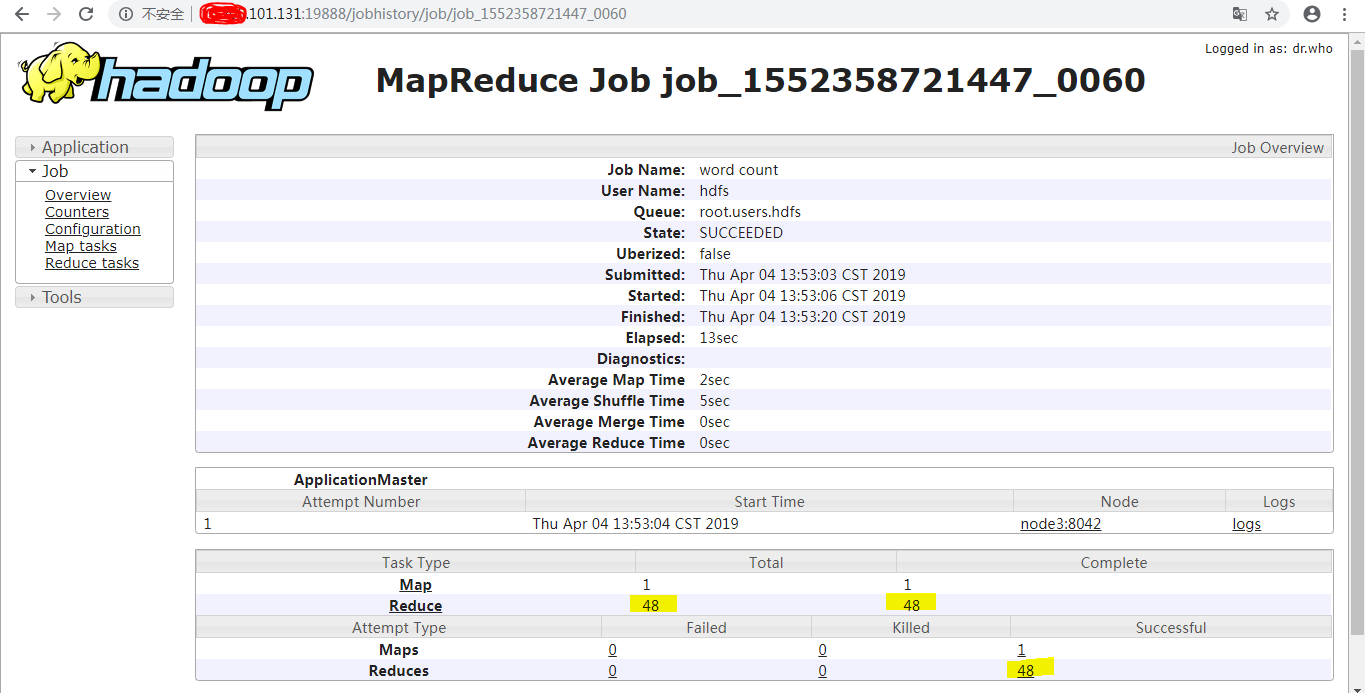
// :: INFO mapreduce.Job: Job job_1552358721447_0060 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total
Total
Total
Total
Total vcore-milliseconds taken by all map tasks=
Total vcore-milliseconds taken by all reduce tasks=
Total megabyte-milliseconds taken by all map tasks=
Total megabyte-milliseconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input
Combine input records=
Combine output records=
Reduce input
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC
CPU
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
在hdfs目录下保存了任务的结果文件:
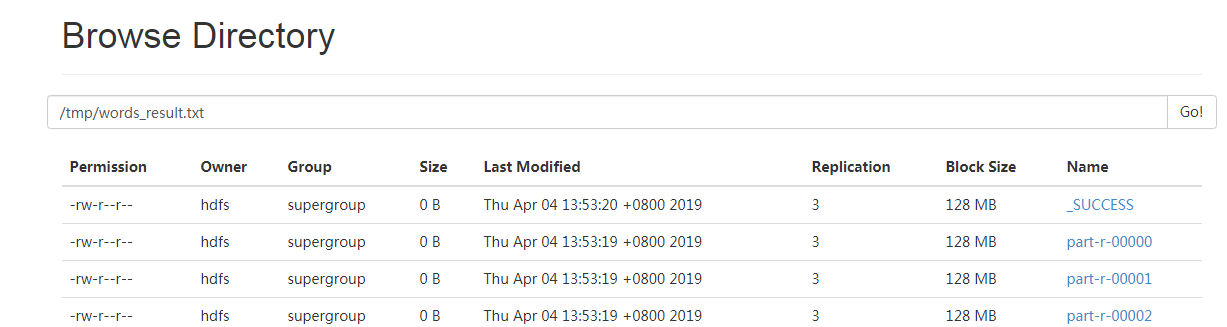
结果记录条目从0计数到47,共计48条:

每一个part对应一个Reduce:
执行命令,查看任务执行后的结果:
bash-4.2$ hadoop fs -cat hdfs:///tmp/words_result.txt/part-r-*****
返回结果如下:
bash-4.2$ hadoop fs -cat hdfs:///tmp/words_result.txt/part-r-00000 bash-4.2$ hadoop fs -cat hdfs:///tmp/words_result.txt/part-r-00011 is bash-4.2$ hadoop fs -cat hdfs:///tmp/words_result.txt/part-r-00015 this bash-4.2$ hadoop fs -cat hdfs:///tmp/words_result.txt/part-r-00022 hadoop bash-4.2$ hadoop fs -cat hdfs:///tmp/words_result.txt/part-r-00024 hbase bash-4.2$ hadoop fs -cat hdfs:///tmp/words_result.txt/part-r-00040 hadoop-node1 bash-4.2$ hadoop fs -cat hdfs:///tmp/words_result.txt/part-r-00041 hadoop-master hadoop-node2 bash-4.2$ hadoop fs -cat hdfs:///tmp/words_result.txt/part-r-00045 my bash-4.2$ hadoop fs -cat hdfs:///tmp/words_result.txt/part-r-00047 mytest
参考: https://jeoygin.org/2012/02/22/running-hadoop-on-centos-single-node-cluster/
Hadoop基准测试(二)的更多相关文章
- MySQL基准测试(二)--方法
MySQL基准测试(二)--方法 目的: 方法不是越高级越好.而应该善于做减法.至简是一种智慧,首先要做的是收集MySQL的各状态数据.收集到了,不管各个时间段出现的问题,至少你手上有第一时间的状态数 ...
- Hadoop(二):MapReduce程序(Java)
Java版本程序开发过程主要包含三个步骤,一是map.reduce程序开发:第二是将程序编译成JAR包:第三使用Hadoop jar命令进行任务提交. 下面拿一个具体的例子进行说明,一个简单的词频统计 ...
- Hadoop 基准测试与example
#pi值示例 hadoop jar /app/cdh23502/share/hadoop/mapreduce2/hadoop-mapreduce-examples--cdh5. #生成数据 第一个参数 ...
- Hadoop系列(二)hadoop2.2.0伪分布式安装
一.环境配置 安装虚拟机vmware,并在该虚拟机机中安装CentOS 6.4: 修改hostname(修改配置文件/etc/sysconfig/network中的HOSTNAME=hadoop),修 ...
- Hadoop MapReduce 二次排序原理及其应用
关于二次排序主要涉及到这么几个东西: 在0.20.0 以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGrou ...
- Hadoop基准测试(转载)
<hadoop the definitive way>(third version)中的Benchmarking a Hadoop Cluster Test Cases的class在新的版 ...
- hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- hadoop(二)搭建伪分布式集群
前言 前面只是大概介绍了一下Hadoop,现在就开始搭建集群了.我们下尝试一下搭建一个最简单的集群.之后为什么要这样搭建会慢慢的分享,先要看一下效果吧! 一.Hadoop的三种运行模式(启动模式) 1 ...
- Hadoop基准测试
其实就是从网络上copy的吧,在这里做一下记录 这个是看一下有哪些测试方式: hadoop jar /opt/cloudera/parcels/CDH-5.3.6-1.cdh5.3.6.p0.11/ ...
随机推荐
- Python:面向对象基础
基本理论 什么是对象 万物皆对象 对象是具体的事物 拥有属性.行为 把许多零散的东西,封装成为一个整体 Python中一切东西都是对象,Python是一门特别彻底的面向对象编程语言(OOP) 其他编程 ...
- Linux 常用命令——查看系统
有的时候别人给你一个登录方式,但是不知道是啥系统,看图就知道了 1.uname -a 查看电脑以及操作系统 2.cat /proc/version 正在运行的内核版本 3.cat /etc/is ...
- 201771010135杨蓉庆《面向对象程序设计(java)》第四周学习总结
学习目标 1.掌握类与对象的基础概念,理解类与对象的关系: 2.掌握对象与对象变量的关系: 3.掌握预定义类的基本使用方法,熟悉Math类.String类.math类.Scanner类.LocalDa ...
- MQTT.js browser node 均支持
npm - mqtt 官网手册 https://www.npmjs.com/package/mqtt#weapp 简书用户 使用笔记 https://www.jianshu.com/p/4fd95ca ...
- 【转】网关协议学习:CGI、FastCGI、WSGI、uWSGI
一直对这四者的概念和区别很模糊,现在就特意梳理一下它们的关系与区别. CGI CGI即通用网关接口(Common Gateway Interface),是外部应用程序(CGI程序)与Web服务器之间的 ...
- i.MX RT600之DSP开发环境调试篇
i.MX RT600的Cadence Xtensa HiFi 4 Audio DSP 是一个高度优化过的音频处理器,主频高达600MHz,专门为音频信号的编码.解码以及预处理和后处理模块而设计,功能十 ...
- 使用win32com操作woord的方法记录
CSDN博客平台中有众多的 win32com 库操作word 的说明,对于通用的内容将一笔带过,主要介绍目前看来独一无二的内容. import win32com from win32com.clien ...
- 在spring boot中使用jasypt对配置文件中的敏感字符串加密
在spring boot的配置文件application.property(application.yml)文件中常常配置一些密码类的字符,如果用明文则很容易被盗用,可以使用jasypt在配置密码的地 ...
- mybatis 多参数传递
参考: 1. MyBatis传入多个参数的问题 http://www.cnblogs.com/mingyue1818/p/3714162.html2. MyBatis报错 Parameter '0' ...
- C++结构体struct与C语⾔结构体和C++引⽤&与传值的区别
写再最前面:摘录于柳神的笔记: (1)定义好结构体 stu 之后,使⽤这个结构体类型的时候,C语⾔需要写关键字 struct ,⽽C++⾥⾯可以省 略不写: (2)这个引⽤符号 & 要和C语⾔ ...