吴裕雄--天生自然HADOOP操作实验学习笔记:ETL案例
实验目的
熟悉hadoop生态系统
初步了解大数据点击流分析业务
学会使用hadoop进行数据分析统计
实验原理
hadoop主要有三部分,hdfs做数据存储、mapreduce做数据计算、yarn做资源调度。在企业生产环境下,对数据做统计需要结合hadoop三个部分综合运用,中间还要使用kafka、storm、hive、hbase、flume、sqoop、mahout等其它工具。架构一般都会很复杂,接下来几个实验我们主要是针对mapreduce的运用,熟悉企业数据处理的一般步骤。
1.数据ETL
数据ETL我们之前讲过,通hive进行处理。同样通过mapreduce进行处理也是常用的思路。一般情况下,我们会记录一个用户访问某个网站的url,数据格式如下:
24162912299|156682|17|353817084376524|913|2017-03-07 15:43:59.355741|2017-03-07 15:44:36.938215|10.216.41.184|58.251.80.100||460011030082524|116.79.217.172|220.206.128.106|0||
29722404056|12379|131|861891035159110|205|2017-03-07 15:43:33.325067|2017-03-07 15:44:36.938252|10.41.188.107|42.236.74.242|Mozilla/5.0 (Linux; U; Android 6.0;zh_cn; Le X620 Build/HEXCNFN5902012151S) AppleWebKit/537.36 (KHTML, like Gecko)Version/4.0 Chrome/49.0.0.0 Mobile Safari/537.36 EUI Browser/5.9.020S|460011391687384|10.103.47.186|10.100.33.227|0||http://web.users.51.la/go.asp?svid=15&id=19022975&tpages=14&ttimes=69&tzone=8&tcolor=32&sSize=412,732&referrer=http%3A//3g.wenxuemm.com/wapbook/58485_16779691.html&vpage=http%3A//mht.1kmb.cn/page_131.html&vvtime=1488872612376
29622649009|45350|22472|8625310314090700|913|2017-03-07 15:44:36.938314|2017-03-07 15:44:36.972407|10.27.50.191|111.206.205.2||460011531516236|116.79.202.60|220.206.128.58|0||
其中第一列是加密后的用户id,第六列是访问时间,最后一列是访问的url,其他列为相关的其他信息。在没有其他条件的辅助下,我们没法直接知道一个用户的访问每个url之间的关系,比较通用的思路是每三十分钟为一个段,如果在访问某个url后三十分钟内访问其他url,认为是一个段。基于这个思路,我们首先对源数据进行初步处理:
对每个用户的访问记录按照时间排序,相邻记录小于三十分钟认为是一个session,sessionId相同,如果大于三十分钟就重新新建一个sessionId。
2.相关业务实现
基于刚刚的分段数据,要进行pv、uv的统计就很简单了,pv就是统计所有的几率和,而uv就是按照一定条件去重再统计。另外如果要计算新增用户、流失用户,需要有累积下来的历史用户数据,业务逻辑都不复杂。进行简单的统计后,更复杂的便是根据用户数据进行挖掘,一方面要挖掘潜在价值、进行千人千面的推荐、发现关联规则等。这就涉及到机器学习的一些算法。今天我们首先进行最简单的pv统计实现。
显然这只是一种比较粗糙的方法,判断的结果有很多不符合实际,实际上我们第一步进行数据过滤,可以基于用户关系模型,也就是类似我们前面使用hive的时候用的基于IP的雪花模型,大家可以自行思考。
实验环境
1.操作系统
服务器:Linux_Centos
操作机:Windows_7
服务器默认用户名:root,密码:123456
操作机默认用户名:hongya,密码:123456
2.实验工具
IntelliJ IDEA

IDEA全称IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、创新的GUI设计等方面的功能可以说是超常的。IDEA是JetBrains公司的产品,这家公司总部位于捷克共和国的首都布拉格,开发人员以严谨著称的东欧程序员为主。
优点:
1)最突出的功能自然是调试(Debug),可以对Java代码,JavaScript,JQuery,Ajax等技术进行调试。其他编辑功能抛开不看,这点远胜Eclipse。
2)首先查看Map类型的对象,如果实现类采用的是哈希映射,则会自动过滤空的Entry实例。不像Eclipse,只能在默认的toString()方法中寻找你所要的key。
3)其次,需要动态Evaluate一个表达式的值,比如我得到了一个类的实例,但是并不知晓它的API,可以通过Code Completion点出它所支持的方法,这点Eclipse无法比拟。
4)最后,在多线程调试的情况下,Log on console的功能可以帮你检查多线程执行的情况。
缺点:
1)插件开发匮乏,比起Eclipse,IDEA只能算是个插件的矮子,目前官方公布的插件不足400个,并且许多插件实质性的东西并没有,可能是IDEA本身就太强大了。
2)在同一页面中只支持单工程,这为开发带来一定的不便,特别是喜欢开发时建一个测试工程来测试部分方法的程序员带来心理上的不认同。
3)匮乏的技术文章,目前网络中能找到的技术支持基本没有,技术文章也少之又少。
4)资源消耗比较大,建个大中型的J2EE项目,启动后基本要200M以上的内存支持,包括安装软件在内,差不多要500M的硬盘空间支持。(由于很多智能功能是实时的,因此包括系统类在内的所有类都被IDEA存放到IDEA的工作路径中)。
特色功能:
智能选择
丰富的导航模式
历史记录功能
JUnit的完美支持
对重构的优越支持
编码辅助
灵活的排版功能
XML的完美支持
动态语法检测
代码检查等等。
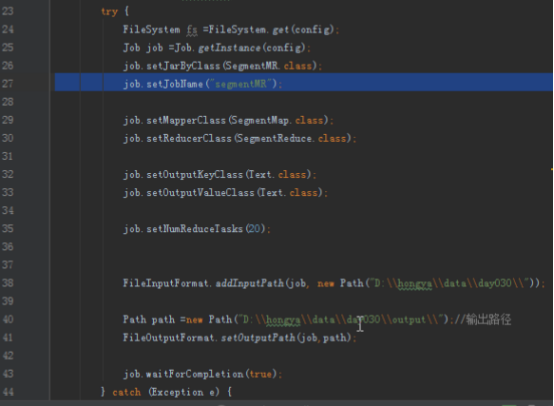
步骤1:编写ETL代码
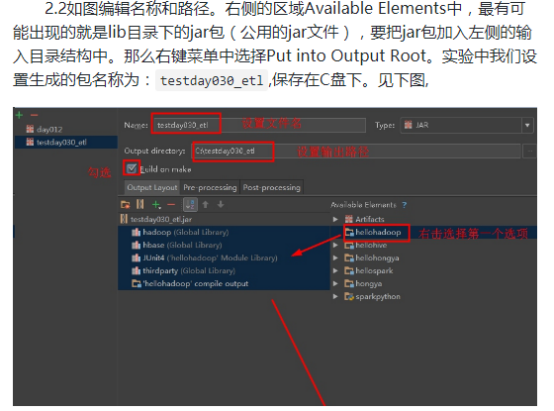
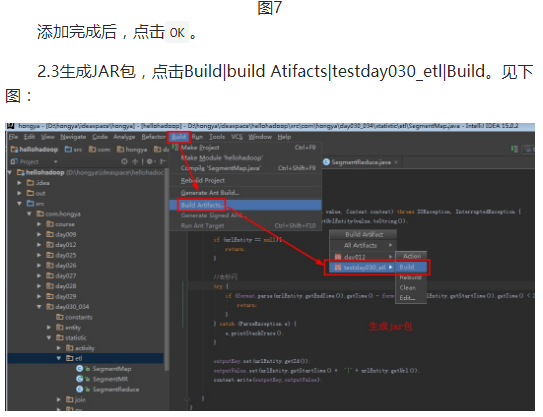
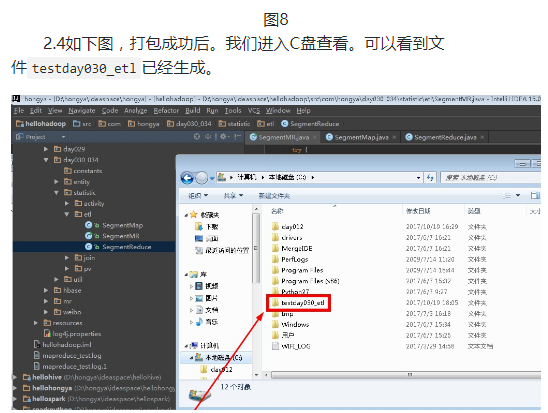
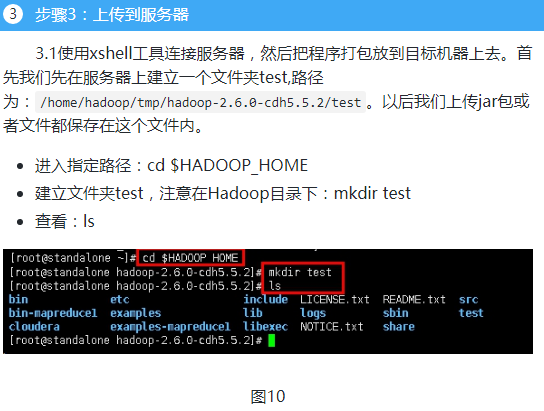
本次实验数据来自于网络,我们会将一定时间内的数据放在hadoop上面,本次实验将不会在本地进行,而是将写好的程序打成jar包,上传到hadoop集群中,通过shell命令提交运行。开发任务还是在本地进行,本次实验的代码放在D:\hongya\ideaspace\hellohadoop\src\com\hongya\day030_034\statistic\etl内,首先打开操作机桌面的IDEA,进入项目hellohadoop|com.hongya|day030_034直接查看代码即可。
1.1刚刚的思路是对每个用户的url数据,按照时间排序,相邻访问记录在30分钟以内认为是一个段,最后我们得到每个用户的段数。所以思路就是map中进行简单的过滤后,以用户为key,时间和访问记录为value写出,在reduce中按照时间排序。
map方法实现:
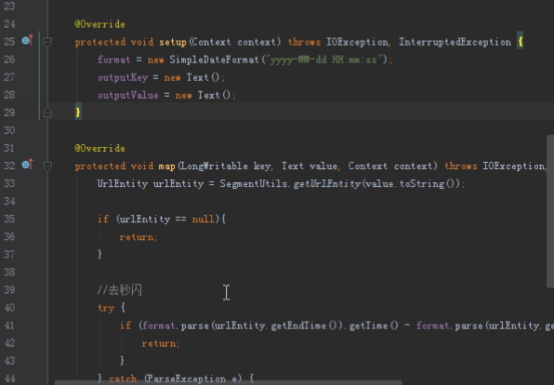
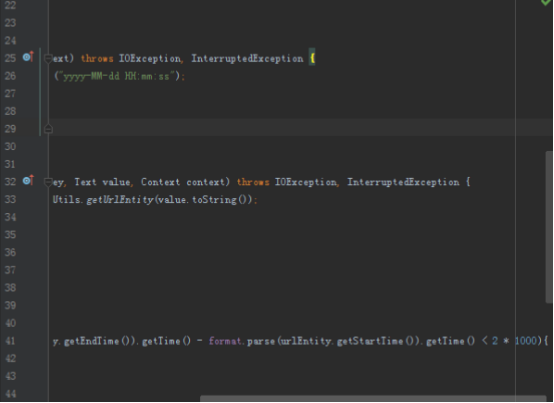
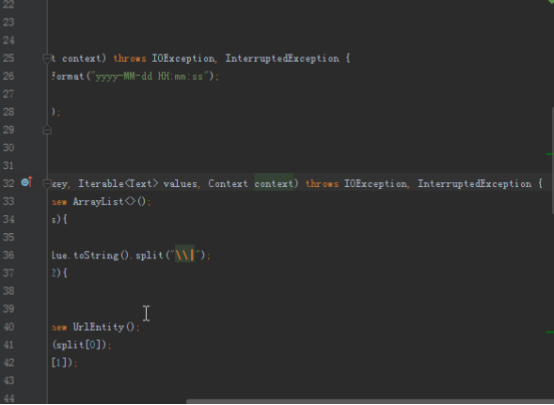
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
UrlEntity urlEntity = SegmentUtils.getUrlEntity(value.toString());
if (urlEntity == null){
return;
}
//去秒闪,开始时间和结束时间在2秒以内
if (format.parse(urlEntity.getEndTime()).getTime() - format.parse(urlEntity.getStartTime()).getTime() < 2 * 1000){
return;
}
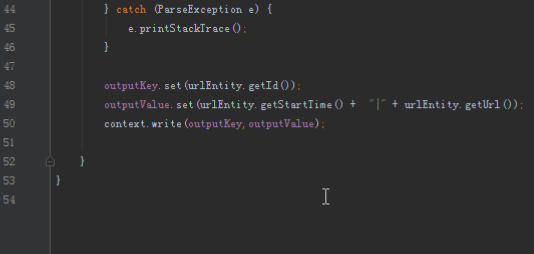
outputKey.set(urlEntity.getId());
outputKey.set(urlEntity.getStartTime() + "|" + urlEntity.getUrl());
context.write(outputKey,outputValue);
}
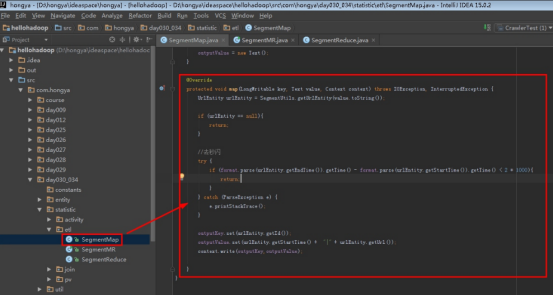
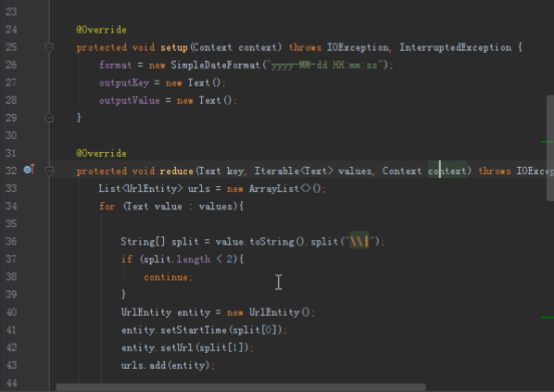
reduce实现:
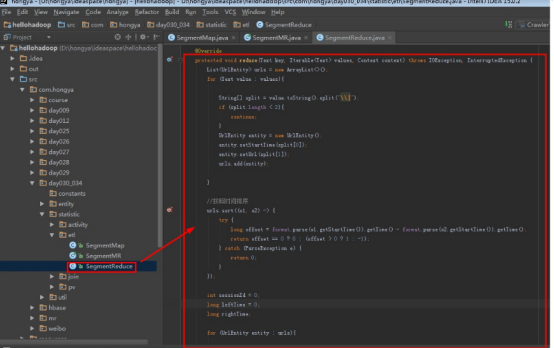
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//全部放进一个list中
List<UrlEntity> urls = new ArrayList<>();
for (Text value : values){
String[] split = value.toString().split("\\|");
if (split.length < 2){
continue;
}
UrlEntity entity = new UrlEntity();
entity.setStartTime(split[0]);
entity.setUrl(split[1]);
urls.add(entity);
}
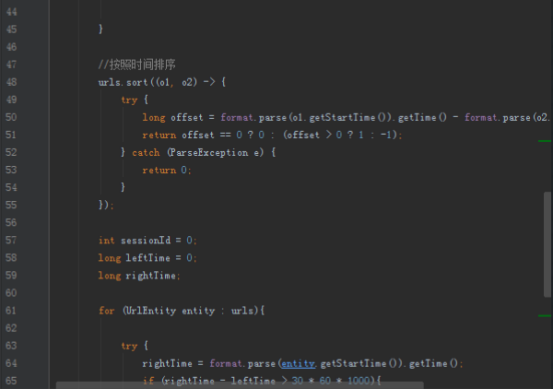
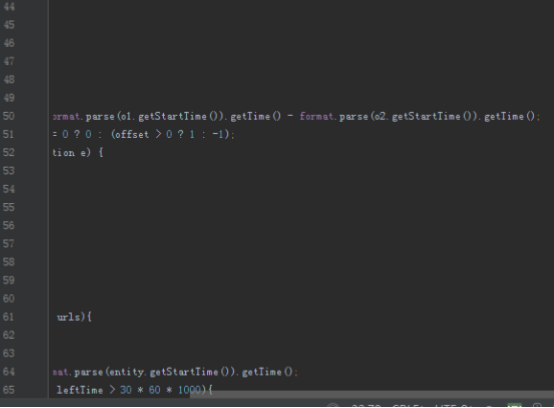
//按照时间排序
urls.sort((o1, o2) -> {
try {
long offset = format.parse(o1.getStartTime()).getTime() - format.parse(o2.getStartTime()).getTime();
return offset == 0 ? 0 : (offset > 0 ? 1 : -1);
} catch (ParseException e) {
return 0;
}
});
int sessionId = 0;
long leftTime = 0;
long rightTime;
for (UrlEntity entity : urls){
try {//判断相邻段的时间间隔
rightTime = format.parse(entity.getStartTime()).getTime();
if (rightTime - leftTime > 30 * 60 * 1000){
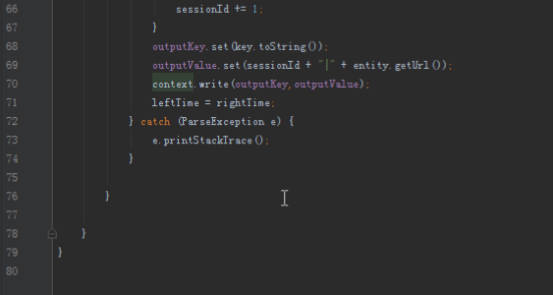
sessionId += 1;
}
outputKey.set(key.toString());
outputValue.set(sessionId + "|" + entity.getUrl());
context.write(outputKey,outputValue);
leftTime = rightTime;
} catch (ParseException e) {
e.printStackTrace();
}
}
}




吴裕雄--天生自然HADOOP操作实验学习笔记:ETL案例的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:使用hive操作hbase
实验目的 熟悉hive和hbase的操作 熟悉hadoop.hbase.hive.zookeeper的关系 熟练大数据环境的搭建 学会分析日志排除问题 实验原理 1.hive整合hbase原理 前面大 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce代码编程
实验目的 深入了解mapreduce的底层 了解IDEA的使用 学会通过本地和集群环境提交程序 实验原理 1.回忆mapreduce模型 前面进行了很多基础工作,本次实验是使用mapreduce的AP ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式及RPC通信简介
实验目的 掌握GOF设计模式的代理模式 了解掌握socket编程.java反射.动态代理 了解NIO.多线程 掌握hadoop的RPC框架使用API 实验原理 1.什么是RPC 在hadoop出现以前 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase学生选课案例
实验目的 复习hbase的shell操作和javaAPI操作 了解javaWeb项目的MVC设计 学会dao(数据库访问对象)和service层的代码编写规范 学会设计hbase表格 实验原理 前面我 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的javaAPI应用
实验目的 进一步了解hbase的操作 熟悉使用IDEA进行java开发 熟悉hbase的javaAPI 实验原理 前面已经了解通过hbase的shell操作hbase,确实比较难以使用,另外通过hiv ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的shell应用v2.0
HRegion 当表的大小超过设置值的时候,HBase会自动地将表划分为不同的区域,每个区域包含所有行的一个子集.对用户来说,每个表是一堆数据的集合,靠主键来区分.从物理上来说,一张表被拆分成了多块, ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hive DDL
实验目的 了解hive DDL的基本格式 了解hive和hdfs的关系 学习hive在hdfs中的保存方式 学习一些典型常用的hiveDDL 实验原理 有关hive的安装和原理我们已经了解,这次实验我 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce和yarn命令
实验目的 了解集群运行的原理 学习mapred和yarn脚本原理 学习使用Hadoop命令提交mapreduce程序 学习对mapred.yarn脚本进行基本操作 实验原理 1.hadoop的shel ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hdfs简单的shell命令
实验目的 了解bin/hadoop脚本的原理 学会使用fs shell脚本进行基本操作 学习使用hadoop shell进行简单的统计计算 实验原理 1.hadoop的shell脚本 当hadoop集 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式资源调度系统yarn的安装
实验目的 复习配置hadoop初始化环境 复习配置hdfs的配置文件 学会配置hadoop的配置文件 了解yarn的原理 实验原理 1.yarn是什么 前面安装好了hdfs文件系统,我们可以根据需求进 ...
随机推荐
- C do...while 循环
不像 for 和 while 循环,它们是在循环头部测试循环条件.在 C 语言中,do...while 循环是在循环的尾部检查它的条件. do...while 循环与 while 循环类似,但是 do ...
- nginx+keepalived+tomcat实现主从高可用负载均衡
设备: 1.准备四台虚拟机,两台tomcat,两台nginx 2.两台tomcat配置相同,测试页不同 两台Tomcat配置完全相同.只有测试页面不同 安装jdk和tomcat [root@local ...
- P1028
一开始没看懂题,看了题解才明白的 = =.思路是,先找规律,会发现有重合部分,利用这些重合部分,写出递推公式. num = 0 时,只有 1 种组合: num = 1 时,只有 1 种组合: num ...
- python练习:使用二分法查找求近似平方根,使用二分法查找求近似立方根。
python练习:使用二分法查找求近似平方根,使用二分法查找求近似立方根. 重难点:原理为一个数的平方根一定在,0到这个数之间,那么就对这之间的数,进行二分遍历.精确度的使用.通过最高值和最低值确定二 ...
- 复变函数知识总结(2)——Cauchy理论
复变函数知识总结(2)——Cauchy理论 版本:2020-01-01 此版本不是最终版本,还有后续的补充和更新. 如有错误请指出,转载时请注明出处! page1 page2 page3 page4 ...
- laravel npm安装yarn
npm install -g yarn yarn install --no-bin-links yarn add cross-env npm run dev Laravel 默认集成了一些 NPM 扩 ...
- 在CDN不能使用的时候加载自己服务器的资源
<script src="http://wlib.sinaapp.com/js/jquery/1.7.2/jquery.min.js"></script> ...
- python数组冒号取值操作
1.冒号的用法 1.1 一个冒号 a[i:j] 这里的i指起始位置,默认为0:j是终止位置,默认为len(a),在取出数组中的值时就会从数组下标i(包括)一直取到下标j(不包括j) 在一个冒号的情况下 ...
- python字符串操作方法详解
字符串 字符串序列用于表示和存储文本,python中字符串是不可变对象.字符串是一个有序的字符的集合,用于存储和表示基本的文本信息,一对单,双或三引号中间包含的内容称之为字符串.其中三引号可以由多 ...
- RDLC 表达式设置精度
=IIf(RTrim(Parameters!u_currency.Value)="VND","F0","F2")