h指数|JCR|ORCID|CCC|Research ID|BKCI|
h指数有如下缺点:
年龄大且平庸的学者比杰出的青年学者的h-index大。学科之间h指数的评价标准不同。有时候,审稿人暗示作者引用自己文章。
再此处可找到相关信息:

JCR上可以查询到影响因子,以下是计算公式:
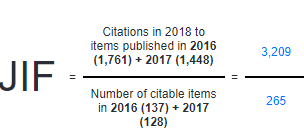
分母是所有出版物的数量,分子是Article review letter三大类文献的引用。
可以在CCC上查找类别,如图:

分区:
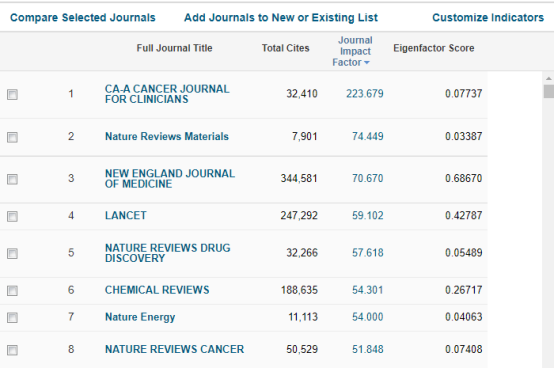
作者的ID是ORCID:

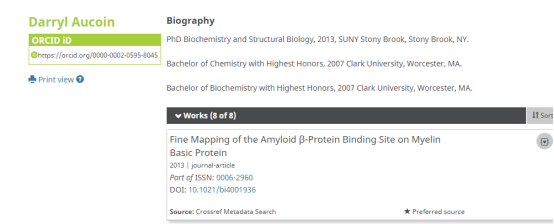
Research ID是自己上传资料的ID,材料不一定真实。
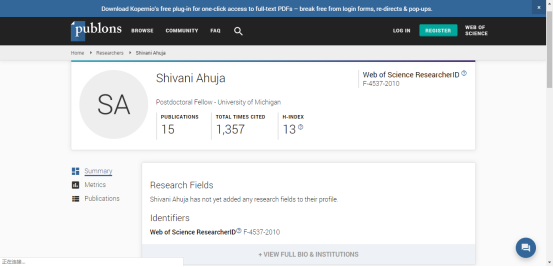
使用次数是download的次数,如图:

人名经常存在错引,有重名且名字格式不一致。
BKCI可以引用图书章节:BKCI:图书引文索引是Web of Science平台的新产品,它的出现弥补了长期以来对图书进行文献计量评价的不足。BKCI具有衡量图书价值、协助揭示馆藏、保持各知识载体相互联系的完整性和协助科研等作用,但同时也存在书语种分布不平衡、回溯年限短和收录图书品种少等不足。
如图:

查期刊分区可以使用该网址:http://mjl.clarivate.com/,下图是其中点开两个期刊的基本内容:


h指数|JCR|ORCID|CCC|Research ID|BKCI|的更多相关文章
- [LeetCode] H-Index 求H指数
Given an array of citations (each citation is a non-negative integer) of a researcher, write a funct ...
- [Swift]LeetCode274.H指数 | H-Index
Given an array of citations (each citation is a non-negative integer) of a researcher, write a funct ...
- [Swift]LeetCode275. H指数 II | H-Index II
Given an array of citations sorted in ascending order (each citation is a non-negative integer) of a ...
- H指数
H指数是用来综合衡量学者发表论文的数量和质量的指标,若某学者共发表N篇论文,H指数是指存在h 篇论文至少每篇有h 引用量,剩下的N-h篇中,每篇都不超过h引用量 计算H指数的方法:1.排序法思路:先将 ...
- Leetcode 274.H指数
H指数 给定一位研究者论文被引用次数的数组(被引用次数是非负整数).编写一个方法,计算出研究者的 h 指数. h 指数的定义: "一位有 h 指数的学者,代表他(她)的 N 篇论文中至多有 ...
- 275 H-Index II H指数 II
这是 H指数 进阶问题:如果citations 是升序的会怎样?你可以优化你的算法吗? 详见:https://leetcode.com/problems/h-index-ii/description/ ...
- 274 H-Index H指数
给定一位研究者的论文被引用次数的数组(被引用次数是非负整数).写一个方法计算出研究者的H指数.H-index定义: “一位科学家有指数 h 是指他(她)的 N 篇论文中至多有 h 篇论文,分别被引用了 ...
- Leetcode之二分法专题-275. H指数 II(H-Index II)
Leetcode之二分法专题-275. H指数 II(H-Index II) 给定一位研究者论文被引用次数的数组(被引用次数是非负整数),数组已经按照升序排列.编写一个方法,计算出研究者的 h 指数. ...
- [LeetCode] 274. H-Index H指数
Given an array of citations (each citation is a non-negative integer) of a researcher, write a funct ...
随机推荐
- rename 修改文件名
Linux的 rename 命令有两个版本,一个是C语言版本的,一个是Perl语言版本的,早期的Linux发行版基本上使用的是C语言版本的,现在已经很难见到C语言版本的了,由于历史原因,在Perl语言 ...
- php速成_day3
一.MySQL关系型数据库 1.什么是数据库 数据库 数据存储的仓库,在网站开发应用当中,需要有一些数据存储起来. 注册的用户信息,使用PHP变量只是一个临时的存储,如果需要永久的存储起来,就把数据存 ...
- UVA 125 统计路径条数 FLOYD
这道题目折腾了我一个下午,本来我的初步打算是用SPFA(),进行搜索,枚举出发点,看看能到达某个点多少次,就是出发点到该点的路径数,如果出现环,则置为-1,关键在于这个判环过程,如果简单只找到某个点是 ...
- rpc框架解释
远程过程调用协议RPC(Remote Procedure Call Protocol) RPC是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方 ...
- 201403-1 相反数 Java
法1:排序后,首尾两个指针 法2:每个数的绝对值如果出现过,flag置为1,如果再次出现,就计数+1 本文采用法1 import java.util.Arrays; import java.util. ...
- Anaconda 安装 TensorFlow ImportError:DLL加载失败,错误代码为-1073741795
错误再现 环境: 使用Anaconda 中 conda 4.6.2, Python 3.7版本 Windows 7 操作系统 CPU: Intel i5 原始安装过程 直接在CMD中,安装链接 中的方 ...
- Codeforces 1294C - Product of Three Numbers
题目大意: 给定一个n,问是否存在3个互不相同的,大于等于2的整数,满足a*b*c=n 解题思路: 可以把abc其中任意两个看作一个整体,例如a*b=d,那么可以发现d*c=n 所以d和c是n的因子 ...
- Linux读取目录文件
1.opendir与readdir函数 (1).opendir打开一个目录后得到一个DIR类型的的指针给readdir使用. (2).readdir函数调用一次后就会返回一个struct dirent ...
- Python 进阶 - 面向对象
Python 面向对象 面向过程 把完成某个需求的所有步骤,从头到尾逐步实现 根据开发需求,将某些功能独立的代码封装成一个又一个函数 最后完成的代码,就是顺序地调用不同的函数 面向过程特点: 注重步骤 ...
- PTC【Creo OR Proe】添加参数的方法
Dim model As IpfcModel Try model = CoCreoAsyncConnection.Session.CurrentModel If model Is Nothing Th ...