hadoop集群搭建(docker)
背景
目前在一家快递公司工作,因项目需要,对大数据平台做个深入的了解。工欲利其器必先利其器,在网上找了许多教程,然后自己搭建一个本地的环境并记录下来,增加一些印象。
环境搭建
1)Ubuntu
docker pull ubuntu:16.04
docker images
docker run -ti ubuntu:16.04
系统运行后,安装一些小工具
# apt update
//weget
# apt-get install wget
//ifconfig
# apt-get install net-tools
//ping
# apt-get install iputils-ping
//vim
# apt-get install vim
# exit
# docker commit -m “wget net-tools iputils-ping vim install” 864c90fe3ebb ubutun:tools
2)Java
apt-get install software-properties-common python-software-properties
add-apt-repository ppa:webupd8team/java
apt-get install oracle-java8-installer
vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
# source ~/.bashrc
# java -version
使用docker commit保存一个副本
3)Hadoop
# cd ~
# mkdir soft
# cd soft
# mkdir apache
# cd apache
# wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.6/hadoop-2.7.6.tar.gz
# tar -zxvf hadoop-2.7.6.tar.gz
配置hadoop环境变量
# vim ~/.bashrc
export HADOOP_HOME=/root/soft/apache/hadoop/hadoop-2.7. export HADOOP_CONFIG_HOME=$HADOOP_HOME/etc/hadoop export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/bin
创建tmp、NameNode、DataNode目录
tmp是hadoop的临时存储目录
NameNode是文件系统的管理节点
DataNode是提供真实文件数据的存储服务
# cd $HADOOP_HOME/
# mkdir tmp
# mkdir namenode
# mkdir datanode
# cd $HADOOP_CONFIG_HOME/
# cp mapred-site.xml.template mapred-site.xml
# vim mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
<description>The host and port that the MapReduce job tracker runs
at. If "local", then jobs are run in-process as a single map
and reduce task.
</description>
</property>
</configuration>
# vim core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/soft/apache/hadoop/hadoop-2.7.6/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<final>true</final>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
</configuration>
# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<final>true</final>
<description>Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/soft/apache/hadoop/hadoop-2.7.6/namenode</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/soft/apache/hadoop/hadoop-2.7.6/datanode</value>
<final>true</final>
</property>
</configuration>
#vim hadoop-en.sh
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
#exit
docker commit -m “hadoop install” xxxxx ubuntu:hadoop
4)ssh配置
# apt-get install ssh
# cd ~/
# ssh-keygen -t rsa -P ‘’ -f ‘~/.ssh/id-rsa’
# cd .ssh
# cat is-rsa.pub >> authorized_keys
# service ssh start
#ssh localhost
#exit
docker commit -m “hadoop install” xxxxx ubuntu:hadoop
5)启动配置
配置好环境,接下来开始启动
master
#docker run -ti -h master -p 50070:50070 -p 8088:8088 ubuntu:hadoop
配置slaves
# cd $HADOOP_CONFIG_HOME/
# vim slaves
slave1
slave2
slave
#docker run -ti -h slave1
#docker run -ti -h slave2
三个节点都启动好了,利用ifconfig查看master、slave1、slave2的ip
#vim/etc/hosts
ip(master) master
ip(slave1) slave1
ip(slave2) slave2
一切都准备好了的时候,就可以切换到hadoop/sbin,开启hadoop集群啦
#cd $HADOOP_HOME/sbin/
#./start-all.sh
稍等片刻之后,可以通过http://localhost:50070/,查看hadoop集群
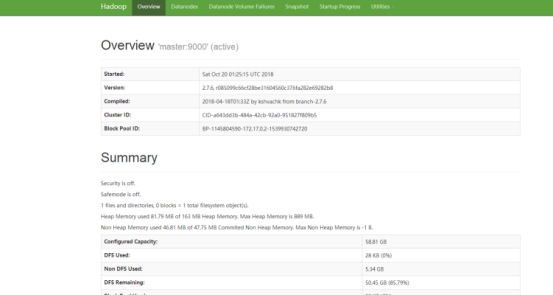
下面是导出的docker系统文件,ubuntu:hadoop,https://pan.baidu.com/s/1GSfZbwJxlTk18YGPqNFwew uhmh
hadoop集群搭建(docker)的更多相关文章
- 大数据初级笔记二:Hadoop入门之Hadoop集群搭建
Hadoop集群搭建 把环境全部准备好,包括编程环境. JDK安装 版本要求: 强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术 ...
- Hadoop 集群搭建
Hadoop 集群搭建 2016-09-24 杜亦舒 目标 在3台服务器上搭建 Hadoop2.7.3 集群,然后测试验证,要能够向 HDFS 上传文件,并成功运行 mapreduce 示例程序 搭建 ...
- Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!) 一.JDK的安装 安装位置都在同一位置(/usr/tools/jdk1.8.0_73) jdk的安装在克隆三台机器的时候可以提前安装 ...
- Hadoop集群搭建安装过程(二)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(二)(配置SSH免密登录)(图文详解---尽情点击!!!) 一.配置ssh无密码访问 ®生成公钥密钥对 1.在每个节点上分别执行: ssh-keygen -t rsa(一 ...
- Hadoop集群搭建安装过程(一)(图文详解---尽情点击!!!)
Hadoop集群搭建(一)(上篇中讲到了Linux虚拟机的安装) 一.安装所需插件(以hadoop2.6.4为例,如果需要可以到官方网站进行下载:http://hadoop.apache.org) h ...
- 大数据 --> Hadoop集群搭建
Hadoop集群搭建 1.修改/etc/hosts文件 在每台linux机器上,sudo vim /etc/hosts 编写hosts文件.将主机名和ip地址的映射填写进去.编辑完后,结果如下: 2. ...
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
- Hadoop(二) HADOOP集群搭建
一.HADOOP集群搭建 1.集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 Na ...
- 1.Hadoop集群搭建之Linux主机环境准备
Hadoop集群搭建之Linux主机环境 创建虚拟机包含1个主节点master,2个从节点slave1,slave2 虚拟机网络连接模式为host-only(非虚拟机环境可跳过) 集群规划如下表: 主 ...
- Hadoop 集群搭建 mark
Hadoop 集群搭建 原创 2016-09-24 杜亦舒 性能与架构 性能与架构 性能与架构 微信号 yogoup 功能介绍 网站性能提升与架构设计 目标 在3台服务器上搭建 Hadoop2.7.3 ...
随机推荐
- Opencv从文件中播放视频
1.VideoCapture()括号中写视频文件的名字,在播放每一帧的时候,使用cv2.waitKey()设置适当的持续时间,太低会播放的很快,太高会很慢,通常情况下25毫秒就行了. 2.获取相机/视 ...
- 常用的tensorflow函数
在mask_rcnn常用的函数 1 tf.cast(): https://blog.csdn.net/dss875914213/article/details/86558407 2 tf.ga ...
- ubuntu 插网线无法上网解决方案
前言 不知道最近是什么情况,ubuntu链接网线总是上不去网,但是wifi还能用,一直也就没有捣鼓,不过今天连wifi都不能用了,只能开始修理了. 修复方案 使用ifconfig命令查看以太网的名称 ...
- 手机H5,用Jquery使图片自动填满两栏式排版
遇上这样的排版,手机的解象度都不同,假如只用CSS3根本就做不出这样的排版:因此要用Jquery. 1. HTML <div class="postImgCenterCrop" ...
- sourceTree 代码回滚(git 和http)
近些时候,有遇到提交后代码有误的情况,所以需要回退到前一个版本.因为不常见,所以每次都不是很熟练,记录于此,以备查阅. 一.[将master重置到这次提交] 在sourceTree中选中错误的提交的下 ...
- UML-如何画操作契约?
1.在编写契约过程中,发现之前的领域模型不对,此时是否需要修改? 需要修改.包括:概念类.属性.关联.这就是不断迭代和进化 2.用例中复杂场景里的状态变化细节,描述过多导致用例臃肿,让人看不下去,因此 ...
- numpy(二)
1.集合操作 包含去重,交,并,差集操作 2.排序.搜索和计数 sort,where,argmin,argmax,count_nonzero,argwhere 3.线性代数 np.linalg库,包含 ...
- android 设置无标题栏主题
<application android:theme="@style/Theme.AppCompat.Light.NoActionBar">
- \_\_module\_\_和\_\_class\_\_
目录 __module__和__class__ 一.__module__ 二.通过字符导入模块 三.__class__ __module__和__class__ # lib/aa.py class C ...
- SMO算法--SVM(3)
SMO算法--SVM(3) 利用SMO算法解决这个问题: SMO算法的基本思路: SMO算法是一种启发式的算法(别管启发式这个术语, 感兴趣可了解), 如果所有变量的解都满足最优化的KKT条件, 那么 ...