第1节 IMPALA:1、impala的基本介绍
impala的介绍:
impala是cloudera公司开源提供的一款高效率的sql查询工具
impala可以兼容hive的绝大多数的语法,可以完全的替代表hive
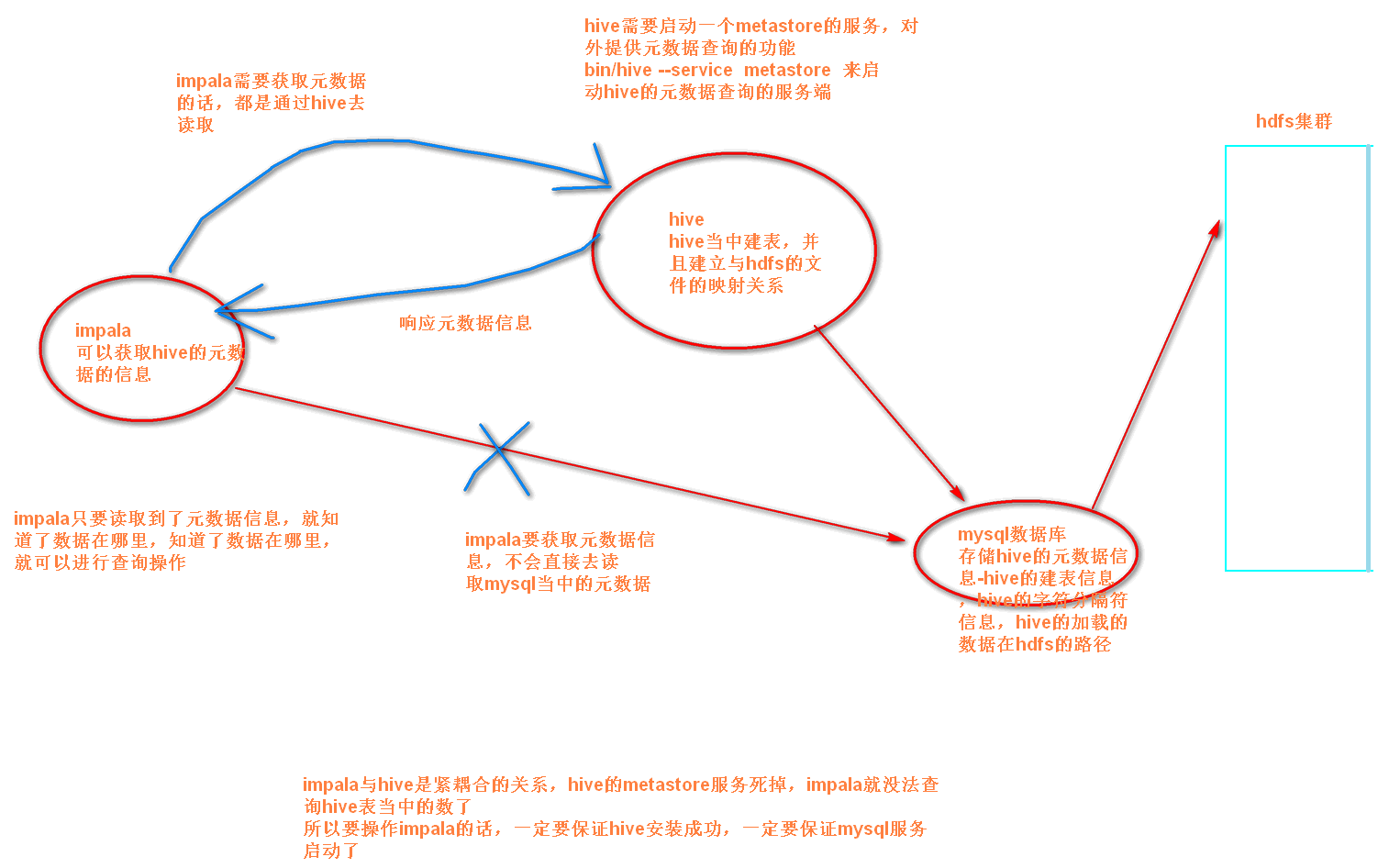
impala与hive的关系:紧耦合的关系
impala的优点与缺点:优点:快 ,以内存空间换区时间速度,所以比较快
缺点:内存消耗比较大,官方推荐每个节点的内存128G起步
底层的实现,是基于C++,维护难度增大
与hive共存亡,紧耦合的关系
稳定性不如hive
===============================================
通过本地yum源进行安装impala
所有cloudera软件下载地址
http://archive.cloudera.com/cdh5/cdh/5/
http://archive.cloudera.com/cdh5/
impala是cloudera提供的一款高效率的sql查询工具,提供实时的查询效果,官方测试性能比hive快3到10倍,其sql查询比sparkSQL还要更加快速,号称是当前大数据领域最快的查询sql工具,
impala是参照谷歌的新三篇论文(Caffeine、Pregel、Dremel
)当中的Dremel实现而来,其中旧三篇论文分别是(BigTable,GFS,MapReduce)分别对应我们即将学的HBase和已经学过的HDFS以及MapReduce
impala是基于hive并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点
impala与hive的关系
impala是基于hive的大数据分析查询引擎,直接使用hive的元数据库metadata,意味着impala元数据都存储在hive的metastore当中,并且impala兼容hive的绝大多数sql语法。所以需要安装impala的话,必须先安装hive,保证hive安装成功,并且还需要启动hive的metastore服务
impala的优点
1、impala比较快,非常快,特别快,因为所有的计算都可以放入内存当中进行完成,只要你内存足够大
2、摈弃了MR的计算,改用C++来实现,有针对性的硬件优化
3、具有数据仓库的特性,对hive的原有数据做数据分析
4、支持ODBC,jdbc远程访问
impala的缺点:
1、基于内存计算,对内存依赖性较大
2、改用C++编写,意味着维护难度增大
3、基于hive,与hive共存亡,紧耦合
4、稳定性不如hive,不存在数据丢失的情况
第1节 IMPALA:1、impala的基本介绍的更多相关文章
- 怎么理解impala(impala工作原理是什么)
下面给大家介绍怎么理解impala,impala工作原理是什么. Impala是hadoop上交互式MPP SQL引擎, 也是目前性能最好的开源SQL-on-hadoop方案. 如下图所示, impa ...
- 第1节 IMPALA:2、架构介绍
impala的架构以及查询计划: impalad :从节点 对应启动一个impala-server的进程 ,主要负责各种查询计划,官方建议与所有的datanode安装在同一台机器上面 impala-s ...
- Impala系列:Impala查询优化
==========================理解 mem_limit 参数==========================set mem_limit=-1b #取消内存限制set mem_ ...
- Impala系列: Impala常用的功能函数
--=======================查看内置的函数--=======================hive 不需要进入什么内置数据库, 即可使用 show functions 命令列出 ...
- impala系列:impala特有的操作符
--=======================Impala 特有的操作符--=======================ILIKE 操作符, 忽略大小写的 like 操作符.REGEXP 操作符 ...
- Impala学习–Impala后端代码分析
Table of Contents 1 代码结构 2 StateStore 3 Scheduler 4 impalad启动流程 5 Coordinator 6 ExecNode 7 PlanFragm ...
- 第15.4节 PyCharm程序代码检测功能介绍
老猿使用PyCharm有将近一个月了,发现PyCharm并不能很好的完成语法检查,有时运行时突然终止,仔细核查却发现是基本的语法错误,不过有次无意中移动鼠标到代码最右边的边框时发现其实PyCharm有 ...
- 第二百七十五节,MySQL数据库安装和介绍
MySQL数据库安装 一.概述 1.什么是数据库 ? 答:数据的仓库,称其为数据库 2.什么是 MySQL.Oracle.SQLite.Access.MS SQL Server等 ? 答:他们均是一种 ...
- 初识 Cloudera Impala
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据.已有的Hive系统尽管也提供了SQL语义,但因为Hive底层 ...
- impala入门
一.概述 Impala 是参照google 的新三篇论文Dremel(大批量数据查询工具)的开源实现,功能类似shark(依赖于hive)和Drill(apache),impala 是clouder ...
随机推荐
- build hadoop, spark, hbase cluster
1,something: 1,arc land 506 git branch 507 git status 508 git reset multicloud/qcloud/cluster_man ...
- ubuntu13.10设置永久静态IP重启不失效
步骤: 1.vi打开/etc/network/interfaces 2.手动添加static ip address 3.:wq保存退出 4.重启网络 service network-manager r ...
- python 基础之文件读操作
创建一个名为‘尘曦’的文件内容如下 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储. ...
- 并发编程之Event事件
Event事件 用来同步线程之间的状态. 举个例子: 你把一个任务丢到了子线程中,这个任务将异步执行.如何获取到这个任务的执行状态 解决方法: 如果是拿到执行结果 我们可以采用异步回调, 在这里我 ...
- jdk 档案库(包含历史版本)
http://java.sun.com/products/archive/ 参考:https://blog.csdn.net/shiluyong8068/article/details/7894747 ...
- 02-09Android学习进度报告九
今天我学习了关于Adapter的基础知识,了解了Android开发的一些思路和架构. 首先我了解了Adapter的概念以及开发过程中常用的Adapter: BaseAdapter:抽象类,实际开发中我 ...
- [NOI 2005]瑰丽华尔兹
Description 题库链接 给你一张 \(n\times m\) 的棋盘,棋盘上有一些障碍.一共 \(t\) 个时刻,被分为 \(k\) 段,在每一段中都有一个向上/下/左/右倾斜的趋势(持续时 ...
- linux 部署java 项目命令
1:服务器部署路径:/home/tomcat/tomcat/webapps (用FTP工具链接服务器把包上传到此目录) 2:进入项目文件夹 cd /home/tomcat/tomcat/webapp ...
- treap(堆树)
# 2018-09-27 17:35:58 我实现的这个treap不能算是堆.有问题 最近对堆这种结构有点感兴趣,然后想用指针的方式实现一个堆而不是利用数组这种结构,于是自己想到了一个用二叉树结构实现 ...
- 「SDOI2013」森林
「SDOI2013」森林 传送门 树上主席树 + 启发式合并 锻炼码力,没什么好说的. 细节见代码. 参考代码: #include <algorithm> #include <cst ...