对上一篇Logstash的补充
主要补充内容:
1.同步多表
2.配置的参数个别说明
3.elasticsearch的"_id"如果有相同的,那么会覆盖掉,相同"_id"的数据只会剩下最后一条。所以还是用数据表中主键自增的id比较好,当然如果有需要也可以自己改变成别的UUID之类的。
elasticsearch默认的"_type"的值是"_doc"
先看一个配置
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC"
jdbc_user => "root"
jdbc_password => "root"
jdbc_driver_library => "D:\softwareRepository\logstash-7.0.0\config\test-config\mysql-connector-java-5.1.46.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000" #zyl.sql的语句是 select * from wuwu_user 我没有使用;结尾,听说用;的话会有问题,不过我也没试
statement_filepath => "D:\softwareRepository\logstash-7.0.0\config\test-config\zyl.sql"
schedule => "* * * * *"
}
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC"
jdbc_user => "root"
jdbc_password => "root"
jdbc_driver_library => "D:\softwareRepository\logstash-7.0.0\config\test-config\mysql-connector-java-5.1.46.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
parameters => {"number" => "200"} #zyl1.sql的语句是:SELECT * from wuwu_kill
statement_filepath => "D:\softwareRepository\logstash-7.0.0\config\test-config\zyl1.sql"
schedule => "* * * * *"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
if[name] == "zyl" {
elasticsearch {
hosts => ["localhost:9200"]
index => "wuwu_user"
document_id => "%{name}"
}
}
if[age] == 18 {
elasticsearch {
hosts => ["localhost:9200"]
index => "wuwu_kill"
document_id => "%{age}"
}
}
elasticsearch {
hosts => ["localhost:9200"]
index => "wuwu_other"
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
这里面的if[xx]==xx是个判断语句,符合哪个标准就生成哪个index。如果同一条数据同时符合两个if, 那么这条数据会同时插入两个index中。也就是说上面的if,if和java的if,if结构一样。而没有if, 直接是elasticsearch的这个是:凡是所有符合了if条件的生成的index的所有数据,它也全都要来一份。
除了if似乎还有别的条件判断操作,但是对我目前使用来说已经够了,所以就没有细究。
然后是document_id=>"%{xx}", 这个xx对应的是你的表里的某一个字段。如果这个不写会出现的问题是:每扫描一次数据库的数据,那么会把符合的数据继续增加。意思是:假设数据不改变,第一次有三条数据符合,加入了index中,再一次扫描会生成同样的三条数据加入index。 并且原本elasticsearch的"_id"是按照这个配置来的,如果你没写,那么elasticsearch会自动生成UUID。并且在没有设置document_id=>的情况下,上一条说的没有if的elastcisearch的index会乱加数据,不存在其他if的index的数据它也会加进去。
document_id=>"%{xx}"的xx不一定非要是数据表的主键,也不一定非要数据表的id字段。
实际上,经过我3个小时的测试,在使用logstash的时候,数据表的结构可以是随意的,没有主键,没有id字段什么的都是可以的。然后规范操作就靠你自己了。
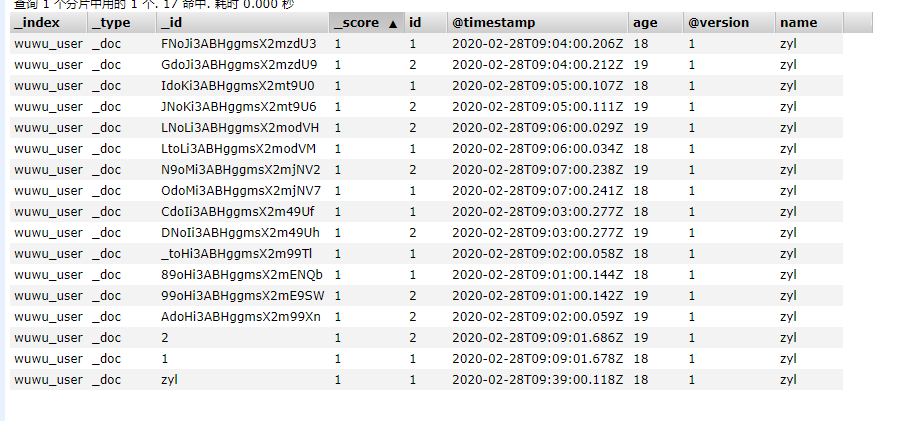
最后附上几张效果图,和我测试时随意写的创表语句
create table wuwu_user
(
id int primary key auto_increment,
name varchar(5),
age int
);
create table wuwu_kill
(
id int primary key auto_increment,
age int,
name char(5)
);
insert into wuwu_user(name,age) value ("zyl",18),("lxf",18),("lw",19);
insert into wuwu_kill(age,name) value (18,"lxf"),(19,"zyl"),(20,"lw");
update wuwu_user set age=18 where name="lw";
update hehe_user set name="zyl" where age=19;
update hehe_kill set age=18 where name="lw";
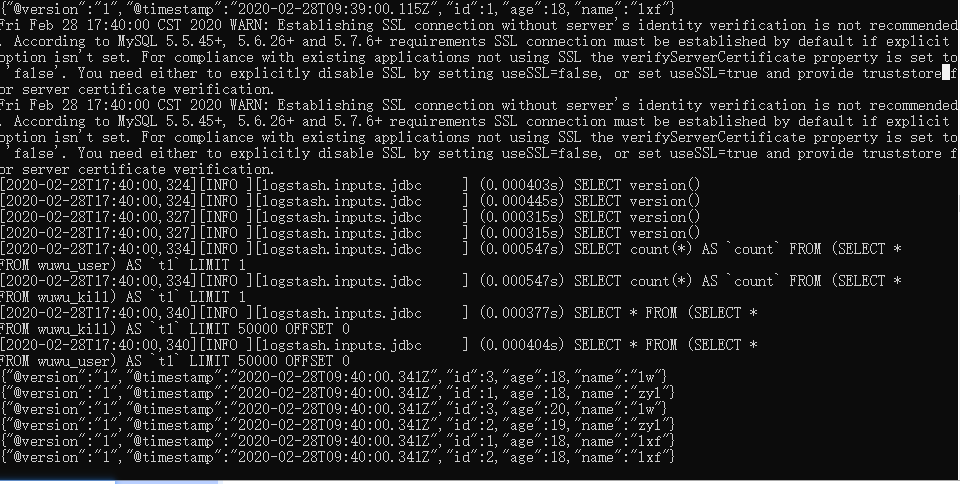
 elasticsearch看起来好像每个select语句都执行了两次,好像是正常现象,我多加了一个if,一共三个if就有被执行的,还是每个语句两遍。
elasticsearch看起来好像每个select语句都执行了两次,好像是正常现象,我多加了一个if,一共三个if就有被执行的,还是每个语句两遍。
对上一篇Logstash的补充的更多相关文章
- Elastic Stack初篇-Logstash
一.Logstash简介 Logstash是一个开源数据收集引擎,具有实时管道功能.Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地. 二.Log ...
- 第五篇、css补充二
一.内容概要 1.图标 2.目录规划 3.a标签中的img标签在浏览器中的适应性 4.后台管理系统设置 5.边缘提示框 6.登录页面图标 7.静态对话框 8.加减框 补充知识: line-height ...
- HTML基础篇之知识点补充和拓展
<tbody>标签 <tbody>如果表格内容非常多的时候,如果加上这个标签它会让这个表格全部下载好才会显示.用在表格标签上面. 如果您使用 thead.tfoot 以及 tb ...
- Python之路【第十四篇】前端补充回顾
布局和事件 1.布局 首先看下下面的图片: 上面的内容都是居中的,怎么实现这个效果呢,第一种方法是通过float的方式,第二种是通过“div居中的方式” 第一种方式不在复述了,直接看第二种方式: 1. ...
- Python学习—数据库篇之SQL补充
一.SQL注入问题 在使用pymysql进行信息查询时,推荐使用传参的方式,禁止使用字符串拼接方式,因为字符串拼接往往会带来sql注入的问题 # -*- coding:utf-8 -*- # auth ...
- Python编程笔记(第三篇)【补充】三元运算、文件处理、检测文件编码、递归、斐波那契数列、名称空间、作用域、生成器
一.三元运算 三元运算又称三目运算,是对简单的条件语句的简写,如: 简单条件处理: if 条件成立: val = 1 else: val = 2 改成三元运算 val = 1 if 条件成立 else ...
- Django框架之第八篇(模型层补充)--数据库的查询与优化:only/defer,select_related与prefetch_related,事务
在设置外键字段时需要注意: 当你使用django2.x的版本时候,在建立外键关系时,需要你手动添加几个关键点参数 models.cascade #设置级联删除 db_constraints 数据库查询 ...
- 基于.NetCore3.1搭建项目系列 —— 使用Swagger导出文档 (补充篇)
前言 在上一篇导出文档番外篇中,我们已经熟悉了怎样根据json数据导出word的文档,生成接口文档,而在这一篇,将对上一篇进行完善补充,增加多种导出方式,实现更加完善的导出功能. 回顾 1. 获取Sw ...
- .Net Discovery 系列之七--深入理解.Net垃圾收集机制(拾贝篇)
关于.Net垃圾收集器(Garbage Collection),Aicken已经在“.Net Discovery 系列”文章中有2篇的涉及,这一篇文章是对上2篇文章的补充,关于“.Net Discov ...
随机推荐
- 3_03_MSSQL课程_Ado.Net_登录复习和ExcuteScalar
SQL注入 ->登陆窗体破解 ->配置文件 ->首先在 app.Config文件中添加 节点,如下: <connectionStrings> <add name=& ...
- Spring开发踩坑记录
#1 @EnableEurekaServer无法正常import原因是spring-cloud-dependencies版本太低,改成高版本的Edgware.SR4即可.参考:https://www. ...
- Redis的安装配置及简单集群部署
最近针对中铁一局项目,跟事业部讨论之后需要我们的KF平台能够接入一些开源的数据库,于是这两天研究了一下Redis的原理. 1. Redis的数据存储原理及简述 1.1Redis简述 Redis是一个基 ...
- redhat 7.6 常用命令
cp 复制命令 diff 对比两个文件内容是否相同 cp -rvf 复制目录 r代表递归 v显示详细步骤 f强制 ls -ah 查看目录 a查看隐藏文件 h显示文件大小单位k less 逐行 ...
- 提高unigui开发效率的两个方法(02)
1.编译时自己退出运行的程序. 在做unigui开发时,每次编译运行时,unigui的应用都会在后台运行,每次重新编译时都必须手工在任务栏里将应用退出才行,非常麻烦,可以在项目编译的参数里加上杀进程的 ...
- 科软-信息安全实验3-Rootkit劫持系统调用
目录 一 前言 二 Talk is cheap, show me the code 三 前期准备 四 效果演示 五 遇到的问题&解决 六 18.04的坑 七 参考资料 八 老师可能的提问 一 ...
- MVC PartialView使用
https://blog.csdn.net/mss359681091/article/details/51181037
- 导航栏协议方法UINavigationControllerDelegate
关于UINavigationControllerDelegate: Delegate中一共有6个方法.其中两个跟控制器ViewController的跳转有关.有两个跟屏幕的旋转有关.有两个跟导航栏动画 ...
- markdown基本语法教程
标题 一级标题 二级标题 三级标题 以此类推,总共六级标题,建议在警号后面加一个空格,这是最标准的markdown语法 列表 在markdown下: 列表的显示只需要在文字前加上-.+或*即可变为无序 ...
- java学习-初级入门-面向对象①-面向对象概述-结构化程序设计
为了学习面向对象程序设计,今天我们先利用面向对象以前的知识,设计一个学生类. 要求进行结构化程序设计. 学生类: Student 要求:存储学生的基本信息(姓名.性别.学历层次和年级),实现学生信息的 ...