二次代价函数、交叉熵(cross-entropy)、对数似然代价函数(log-likelihood cost)(04-1)
二次代价函数
$C = \frac{1} {2n} \sum_{x_1,...x_n} \|y(x)-a^L(x) \|^2$
其中,C表示代价函数,x表示样本,y表示实际值,a表示输出值,n表示样本的总数;整个的意思就是把n个y-a的平方累加起来,再除以2求一下均值。
为简单起见,先看下 一个样本 的情况,此时二次代价函数为:$C = \frac{(y-a)^2} {2}$
$a=\sigma(z), z=\sum w_j*x_j +b$ ,其中a就代表激活函数的输出值,这个符号$\sigma$代表sigmoid函数将变量映射到0-1的$S$型光滑的曲线,z是上一层神经元信号的总和
假如我们使用梯度下降发(Gradient descent)来调整权值参数的大小,权值w和权值b的梯度推到如下(求导数):
$\frac {\partial C} {\partial w} = (a-y)\sigma' (z)x$ $\frac {\partial C} {\partial b} = (a-y)\sigma' (z)$
其中,z表示神经元的输入,$\sigma$表示激活函数sigmoid。可以看出,w和b的梯度跟激活函数的梯度成正比,激活函数的梯度越大,w和b的大小调整越快,训练收敛的就越快。
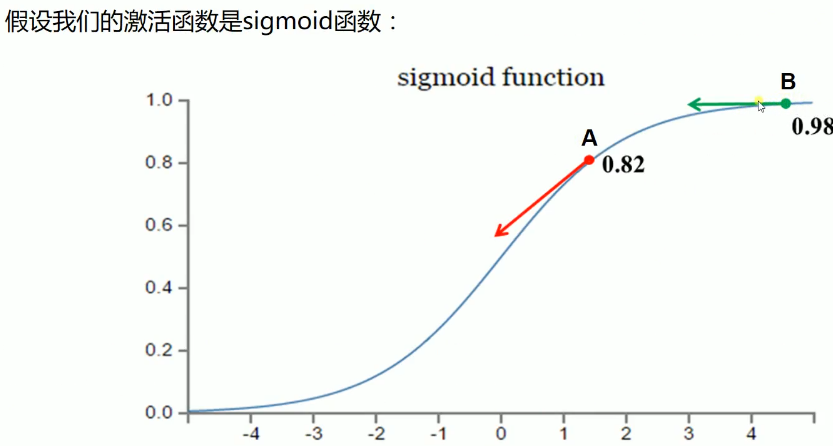
假设我们激活函数输出的值目标是收敛到1,A点离目标较远,梯度较大,权值调整比较大。B点为0.98离目标比较近,梯度比较小,权值调整比较小,调整方案合理。
假设我们激活函数输出的值目标是收敛到0,A点离目标较远,梯度较大,权值调整比较大。B点为0.98离目标比较远,梯度比较小,权值调整比较小,调整方案不合理,B点要经过非常长的时间才会收敛到0,而且B点很可能成为不收敛的点。
交叉墒代价函数(cross-entropy)
由于上边的问题,我们换一种思路,我们不改变激活函数,而是改变代价函数,改用交叉墒代价函数:
$C = -\frac{1}{n} \sum_{x_1,,,x_n}, [y\ln a + (1-y) \ln(1-a)]$
其中,C表示代价函数,x表示样本,y表示实际值,a表示输出值,n表示样本的总数。
$a=\sigma(z), z=\sum w_j*x_j +b $ $ \sigma'(z) = \sigma(z)(1-\sigma (x))$ sigmod函数的导数比较好求,这也是为什么大家用sigmoid做激活函数的原因,接下来我们看一下求导的过程
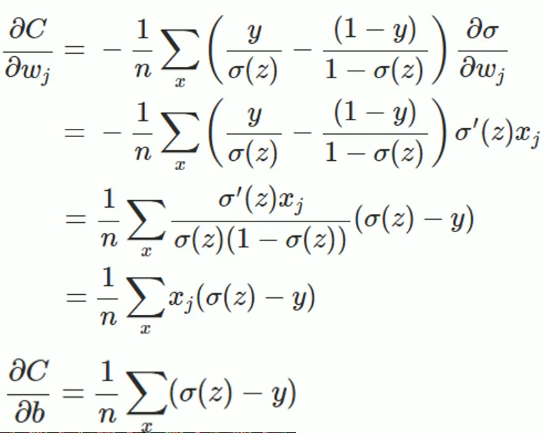
懒得敲了,直接贴个图过来,之后闲了在敲一遍,上边就是求导的推导过程,从最后的式子可以看出:权值w和偏执值b的调整与$\sigma '(z)$无关,另外,梯度公式中的$\sigma (z)-y$表示输出值与实际值放入误差。所以当误差越大时,梯度就越大,参数w和b的调整就越快,训练的速度也就越快。
总结:当输出神经元是线性的,那么二次代价函数就是一种合适的选择。如果输出神经元是S型函数,那么比较适合交叉墒代价函数。
对数似然代价函数(log-likelihood cost)
对数似然函数常用来作为softmax回归的代价函数,如果输出层神经元是sigmoid函数,可以使用交叉墒代价函数。而深度学习中更普遍的做法是将softmax作为最后一层,此时常用的代价函数是对数似然代价函数。
对数似然代价函数与softmax的组合和交叉墒与sigmoid函数的组合非常相似。对数似然代价函数在二分类时可以化简为交叉墒代价函数的形式。
在TensorFlow中用:
tf.nn.sigmoid_cross_entropy_with_logits()来表示跟sigmoid搭配使用的交叉墒。
tf.nn.softmax_cross_entropy_with_logits()来表示跟softmax搭配使用的交叉墒。
二次代价函数、交叉熵(cross-entropy)、对数似然代价函数(log-likelihood cost)(04-1)的更多相关文章
- 最大似然估计 (Maximum Likelihood Estimation), 交叉熵 (Cross Entropy) 与深度神经网络
最近在看深度学习的"花书" (也就是Ian Goodfellow那本了),第五章机器学习基础部分的解释很精华,对比PRML少了很多复杂的推理,比较适合闲暇的时候翻开看看.今天准备写 ...
- 交叉熵cross entropy和相对熵(kl散度)
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量真实分布p与当前训练得到的概率分布q有多么大的差异. 相对熵(relativ ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
- 『TensorFlow』分类问题与两种交叉熵
关于categorical cross entropy 和 binary cross entropy的比较,差异一般体现在不同的分类(二分类.多分类等)任务目标,可以参考文章keras中两种交叉熵损失 ...
- Sklearn中二分类问题的交叉熵计算
二分类问题的交叉熵 在二分类问题中,损失函数(loss function)为交叉熵(cross entropy)损失函数.对于样本点(x,y)来说,y是真实的标签,在二分类问题中,其取值只可能为集 ...
- [ch03-02] 交叉熵损失函数
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI, 点击star加星不要吝啬,星越多笔者越努力. 3.2 交叉熵损失函数 交叉熵(Cross Entrop ...
- TF Boys (TensorFlow Boys ) 养成记(五): CIFAR10 Model 和 TensorFlow 的四种交叉熵介绍
有了数据,有了网络结构,下面我们就来写 cifar10 的代码. 首先处理输入,在 /home/your_name/TensorFlow/cifar10/ 下建立 cifar10_input.py,输 ...
- 【联系】二项分布的对数似然函数与交叉熵(cross entropy)损失函数
1. 二项分布 二项分布也叫 0-1 分布,如随机变量 x 服从二项分布,关于参数 μ(0≤μ≤1),其值取 1 和取 0 的概率如下: {p(x=1|μ)=μp(x=0|μ)=1−μ 则在 x 上的 ...
- 关于交叉熵(cross entropy),你了解哪些
二分~多分~Softmax~理预 一.简介 在二分类问题中,你可以根据神经网络节点的输出,通过一个激活函数如Sigmoid,将其转换为属于某一类的概率,为了给出具体的分类结果,你可以取0.5作为阈值, ...
随机推荐
- Vue-路由跳转的几种方式和路由重定向
一.标签路由 router-link 注意:router-link中链接如果是'/'开始就是从根路由开始,如果开始不带'/',则从当前路由开始. 1.不传参 <router-link :to=& ...
- mybaitis
resultType="java.util.HashMap" SELECT DISTINCT c.COMPANY_LEVEL, ) over ( partition BY COMP ...
- 本机修改虚拟机linux中的代码文件
最近在研究swoole这个框架,好不容易装了一个swoole,为了开发方面,需要早宿主机和虚拟机之间文件共享,一开始使用vmware tool可以实现共享,但是只能在linux中看到win共享的文件, ...
- VS Code的git配置
最近打算使用VS Code作为python的编辑器,这里记录一下VS Code中git的配置方法 因为vscode中git只是使用本地的git,所以本地必须先安装git才行. 1.git的安装 git ...
- 201771010135 杨蓉庆/张燕《面对对象程序设计(java)》第十三周学习总结
1.实验目的与要求 (1) 掌握事件处理的基本原理,理解其用途: (2) 掌握AWT事件模型的工作机制: (3) 掌握事件处理的基本编程模型: (4) 了解GUI界面组件观感设置方法: (5) 掌握W ...
- MyCat of Middleware
第一章 入门概述 1.1 是什么 Mycat 是数据库中间件. 1.数据库中间件 中间件:是一类连接软件组件和应用的计算机软件,以便于软件各部件之间的沟通. 例子:Tomcat,web中间件. 数据库 ...
- C#加载XML方式
//path:xml文件路径 SECSMessage:xml文件的根元素下的第一个子集元素 <SECSLibrary> <SECSMessage> <Descripti ...
- javascript 删除对象的属性 delete
1.当属性存在 configurable:true delete命令会返回true var obj={a:1}; delete obj.a //true console.log(obj);//{} 2 ...
- 获取自增长的id值
单个: <insert id="create" parameterType="com.dto.Cou" useGeneratedKeys="tr ...
- Deeplearning.ai课程笔记-改善深层神经网络
目录 一. 改善过拟合问题 Bias/Variance 正则化Regularization 1. L2 regularization 2. Dropout正则化 其他方法 1. 数据变形 2. Ear ...