【面试QA-基本模型】LSTM
为什么传统 CNN 适用于 CV 任务,RNN 适用于 NLP 任务
从模型特点上来说:
对于 CNN 每一个卷积核都可以看作是一个滤波器,卷积运算的本质是互相关运算,每个卷积核仅对于具有特定特征具有较大的激活值,而且 CNN 有参数共享和局部连接的特点,能够提取图像上不同位置的同一个特征,即 CNN 具有平移不变性
RNN 的特点在于其是一个时序模型,在对每个神经元不仅可以接收当前时刻的输入信息,还将接收上一个时刻的该神经元的输出信息,具有短期记忆能力。这在用于 NLP 任务时相当于隐含着建立了一个语言模型,这对词序具有很强的区分能力。而 CNN 和 DNN 均类似词袋模型,丢失的词序特征。
从数据特征上来说
- 图像矩阵中的每个元素为图像中的像素值,每个像素与其周围元素都是高度相关的
- 文本矩阵中的数据为词的 embedding 向量,每个元素在词向量内与词向量间的相邻元素的关联性是不同的,因此 CNN 用于 NLP 任务常使用的是一维卷积
RNN 原理
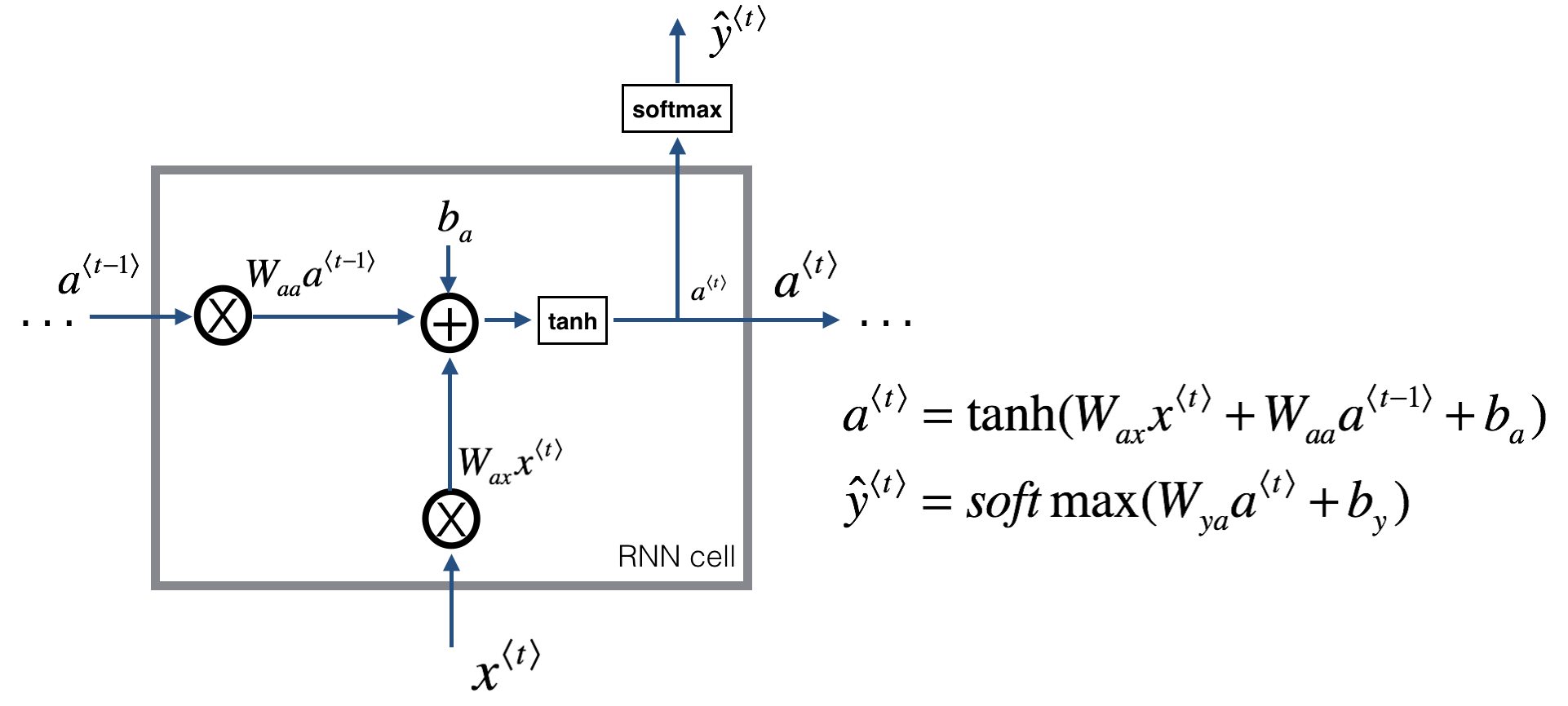
\(\hat y\) 部分的激活函数可以根据下游任务设置
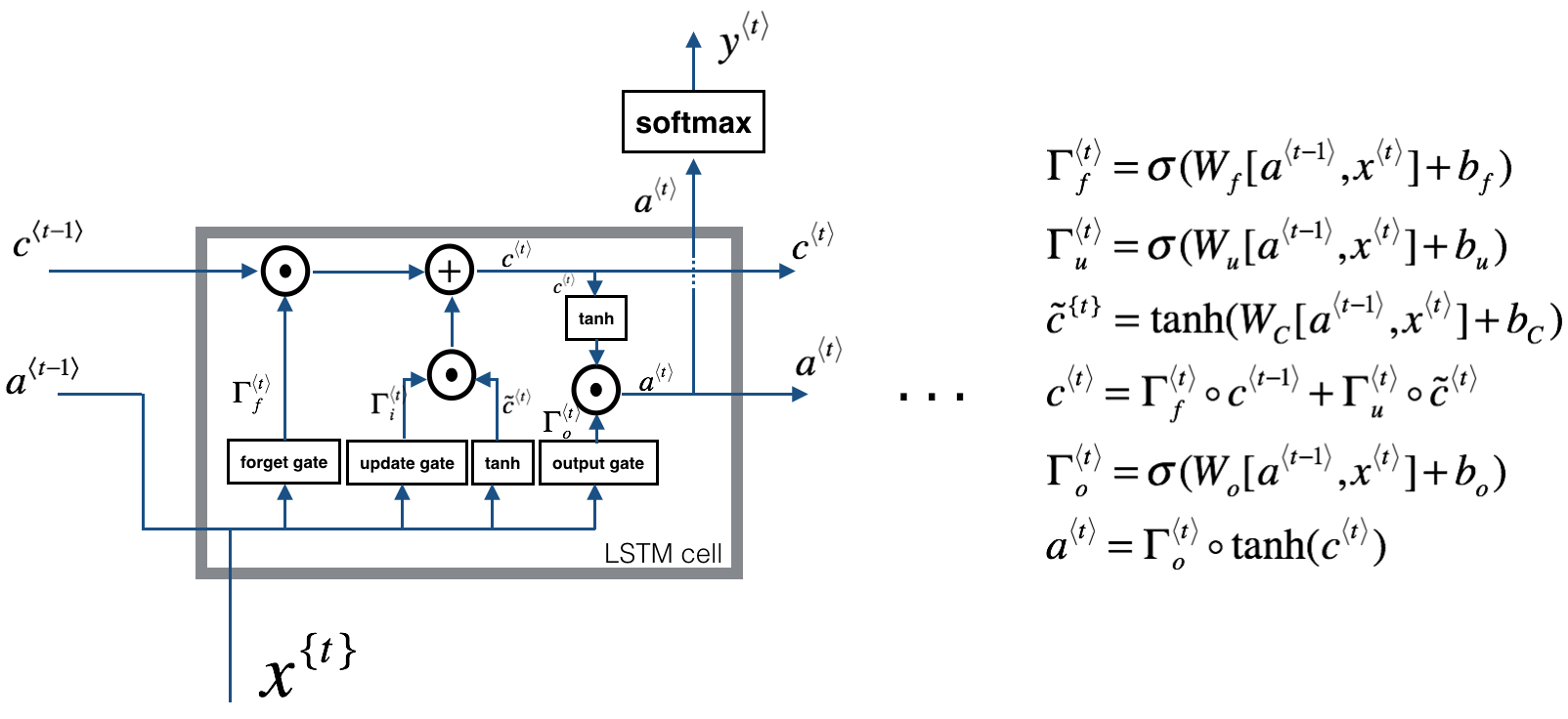
LSTM 原理
- 三个门:[output_dim + input_dim, 1]
- 更新门位置的全连接层:[output_dim + input_dim, output_dim]
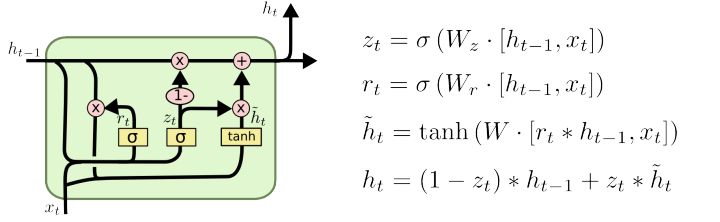
GRU 原理
- 两个门:[output_dim + input_dim, 1]
- 全连接层:[output_dim + input_dim, output_dim]
RNN BPTT
- 假设$t$时刻的损失函数为$L_t$,以 $W_{aa}$,$W_{ax}$,$W_{ya}$ 为例
$$ \begin{aligned}
&\frac{\delta L_t}{\delta W_{ya}} = \frac{\delta L_3}{\delta \hat{y}_t}\frac{\delta \hat{y}_t}{\delta W_{ya}} \\
&\frac{\delta L_t}{\delta W_{aa}} = \frac{\delta L_t}{\delta \hat{y}_t}\frac{\delta \hat{y}_t}{\delta a_{t}}(\frac{\delta a_{t}}{\delta W_{aa}} + \frac{\delta a_{t}}{\delta a_{t-1}}\frac{\delta a_{t-1}}{\delta W_{aa}} + ...)\\
&\frac{\delta L_t}{\delta W_{ax}} = \frac{\delta L_3}{\delta \hat{y}_t}\frac{\delta \hat{y}_t}{\delta a_{t}}(\frac{\delta a_{t}}{\delta W_{ax}} + \frac{\delta a_{t}}{\delta a_{t-1}}\frac{\delta a_{t-1}}{\delta W_{ax}} + ...)
\end{aligned}$$
- 对于任意时刻t对 \(W_x\),\(W_s\) 求偏导的公式为:
&\frac{\delta L_t}{\delta W_{aa}} = \sum_{k=0}^{t}\frac{\delta L_t}{\delta y_t}\frac{\delta y_t}{\delta a_t}( \prod_{j=k+1}^t\frac{\delta a_j}{\delta a_{j-1}} ) \frac{\delta a_k}{\delta W_{aa}}\\
&\frac{\delta L_t}{\delta W_{aa}} = \sum_{k=0}^{t}\frac{\delta L_t}{\delta y_t}\frac{\delta y_t}{\delta a_t}( \prod_{j=k+1}^t\frac{\delta a_j}{\delta a_{j-1}} ) \frac{\delta a_k}{\delta W_{aa}}
\end{aligned}\]
- 其中\(\frac{\delta a_j}{\delta a_{j-1}}\)和\(\frac{\delta a_k}{\delta W_{aa}}\)还存在\(tanh'\)的导数项,而\(tanh'\)的值域为\((0, 1)\)。随着时间步的增长,累乘项会趋于 0,出现梯度消失的问题
LSTM 如何解决 RNN 的梯度消失问题
- RNN 的激活函数为 \(tanh\),而 \(tanh\) 的导数取值范围为 \([0, 1]\),在时间上的反向传播会存在时间上的梯度累乘项,时间步长了会导致梯度累乘而消失
- LSTM 通过引入全局信息流,在时间维度上引入残差结构,残差结构的引入就使得链式求导过程中引入了一个求和项,从反向传播的求导来看,最多只有两个激活函数的导数累乘,因此远距离的梯度通常都可以正常传播,减弱了梯度消失问题
怎样增加 LSTM 的长距离特征提取能力
- Dilated RNN:Dilated CNN 为空洞卷积,Dilated RNN 则是在时间维度上空洞,浅层部分的为传统 RNN,每个时间步都循环,深层的循环周期更长,增大时间维度上的“感受野”
【面试QA-基本模型】LSTM的更多相关文章
- 不止面试02-JVM内存模型面试题详解
第一部分:面试题 本篇文章我们将尝试回答以下问题: 描述一下jvm的内存结构 描述一下jvm的内存模型 谈一下你对常量池的理解 什么情况下会发生栈内存溢出?和内存溢出有什么不同? String str ...
- 如何面试QA(面试官角度)
面试是一对一 或者多对一的沟通,是和候选人 互相交换信息.平等的. 面试的目标是选择和雇佣最适合的人选.是为了完成组织目标.协助人力判断候选人是否合适空缺职位. 面试类型: (1)预判面试(查看简历后 ...
- 【NLP面试QA】激活函数与损失函数
目录 Sigmoid 函数的优缺点是什么 ReLU的优缺点 什么是交叉熵 为什么分类问题的损失函数为交叉熵而不能是 MSE? 多分类问题中,使用 sigmoid 和 softmax 作为最后一层激活函 ...
- 面试 02-CSS盒模型及BFC
02-CSS盒模型及BFC #题目:谈一谈你对CSS盒模型的认识 专业的面试,一定会问 CSS 盒模型.对于这个题目,我们要回答一下几个方面: (1)基本概念:content.padding.marg ...
- Java面试- JVM 内存模型讲解
经常有人会有这么一个疑惑,难道 Java 开发就一定要懂得 JVM 的原理吗?我不懂 JVM ,但我照样可以开发.确实,但如果懂得了 JVM ,可以让你在技术的这条路上走的更远一些. JVM 的重要性 ...
- 【面试QA】Attention
目录 Attention机制的原理 Attention机制的类别 双向注意力 Self-Attention 与 Soft-Attention 的区别 Transformer Multi-Head At ...
- 【NLP面试QA】预训练模型
目录 自回归语言模型与自编码语言 Bert Bert 中的预训练任务 Masked Language Model Next Sentence Prediction Bert 的 Embedding B ...
- 【NLP面试QA】基本策略
目录 防止过拟合的方法 什么是梯度消失和梯度爆炸?如何解决? 在深度学习中,网络层数增多会伴随哪些问题,怎么解决? 关于模型参数 模型参数初始化的方法 模型参数初始化为 0.过大.过小会怎样? 为什么 ...
- java面试-Java内存模型(JMM)
p.p1 { margin: 0; font: 15px Helvetica } 一.并发编程两个关键问题 线程之间如何通信.同步.java并发采用的是共享内存模型 二.JMM内存模型的抽象结构 描述 ...
随机推荐
- 安全测试——利用Burpsuite密码爆破(Intruder入侵)
本文章仅供学习参考,技术大蛙请绕过. 最近一直在想逛了这么多博客.论坛了,总能收获一堆干货,也从没有给博主个好评什么的,想想着实有些不妥.所以最近就一直想,有时间的时候自己也撒两把小米,就当作是和大家 ...
- AndroidImageSlider
最核心的类是SliderLayout,他继承自相对布局,包含了可以左右滑动的SliderView,以及页面指示器PagerIndicator.这两部分都可以自定义. AndroidImageSlide ...
- AndroidStudio实现AIDL
AIDL的使用步骤 aidl远程调用传递的参数和返回值支持Java的基本类型(int long booen char byte等)和String,List,Map等.当然也支持一个自定义对象的传递. ...
- MQ消息丢了怎么破?在线等.....
MQ又丢消息了,老板眉头一紧............ 在我们从事技术的工作中,离不开中间件,mq就是常见的中间件之一,丢消息可能是我们经常遇到的,为啥会丢?丢了怎么破?测试能不能复现,很多同学知道一些 ...
- Windows GDI 窗口与 Direct3D 屏幕截图
前言 Windows 上,屏幕截图一般是调用 win32 api 完成的,如果 C# 想实现截图功能,就需要封装相关 api.在 Windows 上,主要图形接口有 GDI 和 DirectX.GDI ...
- AE脚本:把SubRip/SRT/TXT/VTT字幕导入到AE
脚本介绍 如果您需要在视频中嵌入字幕以进行网络或磁带传送,那么这个脚本则非常有用.可以将SubRip/SRT/TXT/VTT字幕格式文件通过 pt_ImportSubtitles脚本直接加载到AE软件 ...
- 零基础JavaScript编码(二)
任务目的 在上一任务基础上继续JavaScript的体验 学习JavaScript中的if判断语法,for循环语法 学习JavaScript中的数组对象 学习如何读取.处理数据,并动态创建.修改DOM ...
- koa进阶史(一)
1,设置静态文件目录,将__dirname 写成_dirname,乍看没什么毛病,但是一运行之后发现,_dirname is not defined,下次注意哈 app.use(express.sta ...
- 什么是SSH与SSH客户端
1.什么是SSH? SSH 为 Secure Shell 的缩写,由 IETF 的网络工作小组(Network Working Group)所制定:SSH 为建立在应用层和传输层基础上的安全协议.SS ...
- 复制图片链接和标题生成Markdown文本
写Markdown的时候常常会需要复制图片链接和标题以插入图片,不借助其他工具的话,一般需要先在Markdown文件中输入插入图片的格式,然后在浏览器中复制图片链接和标题将其依次粘贴到Markdown ...