06 ORM常用字段 关系字段 数据库优化查询
一、Django ORM 常用字段和参数
1.常用字段
models中所有的字段类型其实本质就那几种,整形varchar什么的,都没有实际的约束作用,虽然在models中没有任何限制作用,但是还是要分门别类,对于校验性组件校验非常有用
就比如说邮箱类型,你在输入邮箱的时候如果不按照邮箱格式输入,瞎鸡儿输入会提示你不合法,虽然输入的是字符串,但是不是规定的邮箱字符串
AutoField() 【int primary key auto_increment)】 int自增列,必须填入参数 primary_key=True。当model中如果没有自增列,则自动会创建一个列名为id的列。
IntegerField() 【int()】一个整数类型,范围在 -2147483648 to 2147483647。(一般不用它来存手机号(位数也不够),直接用字符串存
CharField() 【varchar()】 字符类型,必须提供max_length参数, max_length表示字符长度。
DateField() 【date】日期字段,日期格式 YYYY-MM-DD,相当于Python中的datetime.date()实例。
DateTimeField() 【datetime】日期时间字段,格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ],相当于Python中的datetime.datetime()实例
EmailField() 【varchar(254)】其实就是varchar但是不能直接写成varchar,就比如男人女人都是人,但是必须说清楚,后面会用于校验性组件的校验
BooleanField()
is_delete = BooleanField()
给该字段传值的时候 你只需要传布尔值即可
但是对应到数据库 它存的是0和1
TextField()
- 文本类型用来存大段文本
FileField()
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "path" 用户上传的文件会自动放到等号后面指定的文件路径中
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
自定义char:
Django中的CharField对应的MySQL数据库中的varchar类型,没有设置对应char类型的字段,
但是Django允许我们自定义新的字段,下面我来自定义对应于数据库的char类型
自定义字段在实际项目应用中可能会经常用到
from django.db import models # Create your models here.
#Django中没有对应的char类型字段,但是我们可以自己创建
class FixCharField(models.Field):
'''
自定义的char类型的字段类
'''
def __init__(self,max_length,*args,**kwargs):
self.max_length=max_length
super().__init__(max_length=max_length,*args,**kwargs) def db_type(self, connection):
'''
限定生成的数据库表字段类型char,长度为max_length指定的值
:param connection:
:return:
'''
return 'char(%s)'%self.max_length
#应用上面自定义的char类型
class Class(models.Model):
id=models.AutoField(primary_key=True)
title=models.CharField(max_length=32)
class_name=FixCharField(max_length=16)
gender_choice=((1,'男'),(2,'女'),(3,'保密'))
gender=models.SmallIntegerField(choices=gender_choice,default=3)
自定义char类型

字段合集和对应关系
AutoField(Field)
- int自增列,必须填入参数 primary_key=True BigAutoField(AutoField)
- bigint自增列,必须填入参数 primary_key=True 注:当model中如果没有自增列,则自动会创建一个列名为id的列
from django.db import models class UserInfo(models.Model):
# 自动创建一个列名为id的且为自增的整数列
username = models.CharField(max_length=32) class Group(models.Model):
# 自定义自增列
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32) SmallIntegerField(IntegerField):
- 小整数 -32768 ~ 32767 PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正小整数 0 ~ 32767
IntegerField(Field)
- 整数列(有符号的) -2147483648 ~ 2147483647 PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正整数 0 ~ 2147483647 BigIntegerField(IntegerField):
- 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807 BooleanField(Field)
- 布尔值类型 NullBooleanField(Field):
- 可以为空的布尔值 CharField(Field)
- 字符类型
- 必须提供max_length参数, max_length表示字符长度 TextField(Field)
- 文本类型 EmailField(CharField):
- 字符串类型,Django Admin以及ModelForm中提供验证机制 IPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制 GenericIPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6
- 参数:
protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6"
unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启此功能,需要protocol="both" URLField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证 URL SlugField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号) CommaSeparatedIntegerField(CharField)
- 字符串类型,格式必须为逗号分割的数字 UUIDField(Field)
- 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证 FilePathField(Field)
- 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能
- 参数:
path, 文件夹路径
match=None, 正则匹配
recursive=False, 递归下面的文件夹
allow_files=True, 允许文件
allow_folders=False, 允许文件夹 FileField(Field)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage ImageField(FileField)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
width_field=None, 上传图片的高度保存的数据库字段名(字符串)
height_field=None 上传图片的宽度保存的数据库字段名(字符串) DateTimeField(DateField)
- 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ] DateField(DateTimeCheckMixin, Field)
- 日期格式 YYYY-MM-DD TimeField(DateTimeCheckMixin, Field)
- 时间格式 HH:MM[:ss[.uuuuuu]] DurationField(Field)
- 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型 FloatField(Field)
- 浮点型 DecimalField(Field)
- 10进制小数
- 参数:
max_digits,小数总长度
decimal_places,小数位长度 BinaryField(Field)
- 二进制类型
字段合集
对应关系:
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
orm字段和mysql字段对应关系
2.字段参数
null 用于表示某个字段可以为空。
unique 如果设置为unique=True 则该字段在此表中必须是唯一的 。
db_index 如果db_index=True 则代表着为此字段设置索引。
default 为该字段设置默认值。
DateField和DateTimeField:
uto_now_add 配置auto_now_add=True,创建数据记录的时候会把当前时间添加到数据库。
auto_now 配置上auto_now=True,每次更新数据记录的时候会更新该字段
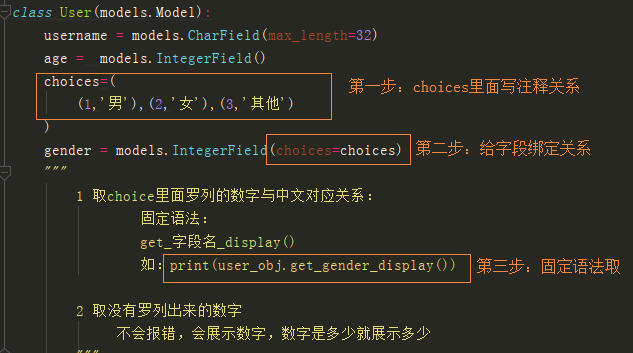
3.choices字段
在很多时候我们往数据库中存数据的时候不会直接存储汉字,会采用数字存取代替汉字,减小内存,
我们使用choices来给数字绑定注释关系,后期取出来的时候用固定语法取出注释,如:1表示男,我们取出来的时候取出男并不是取出数字1
1.绑定关系 choices=((1,'男'),(2,'女'),(3,'其他'))
gender = models.IntegerField(choices=choices)
.取choice里面罗列的数字与中文对应关系:
固定语法:
get_字段名_display()
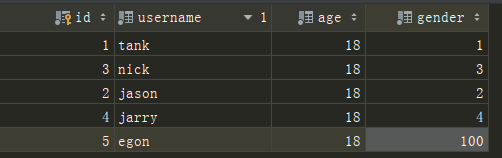
如:print(user_obj.get_gender_display()) 3. 取没有罗列出来的数字
不会报错,会展示数字,数字是多少就展示多少
from django.db import models # Create your models here.
class User(models.Model):
username = models.CharField(max_length=32)
age = models.IntegerField()
choices=(
(1,'男'),(2,'女'),(3,'其他')
)
gender = models.IntegerField(choices=choices)
"""
1 取choice里面罗列的数字与中文对应关系:
固定语法:
get_字段名_display()
如:print(user_obj.get_gender_display()) 2 取没有罗列出来的数字
不会报错,会展示数字,数字是多少就展示多少
"""
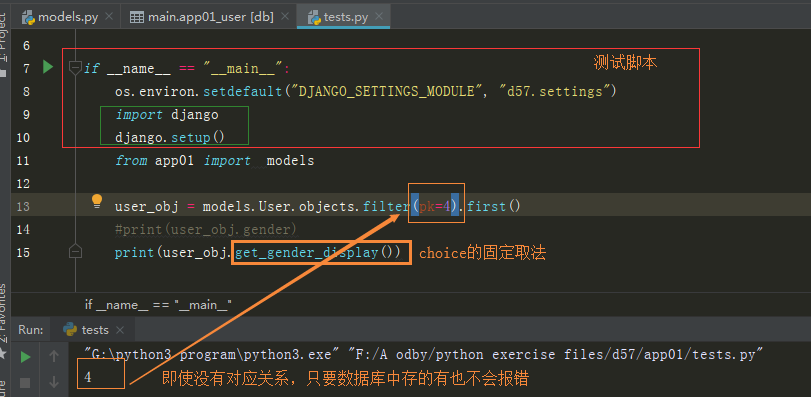
models.py
import os
import sys if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "d57.settings")
import django
django.setup()
from app01 import models user_obj = models.User.objects.filter(pk=5).first()
#print(user_obj.gender)
print(user_obj.get_gender_display())
test.py取
二、关系字段
1.ForeignKey
外键类型在ORM中用来表示外键关联关系,一般把ForeignKey字段设置在 '一对多'中'多'的一方。
ForeignKey可以和其他表做关联关系同时也可以和自身做关联关系。
字段参数:
# to 设置要关联的表
class Classes(models.Model):
name = models.CharField(max_length=32) class Student(models.Model):
name = models.CharField(max_length=32)
theclass = models.ForeignKey(to="Classes")
#to_field 设置要关联的表的字段
#on_delete 当删除关联表中的数据时,当前表与其关联的行的行为
def func():
return 10 class MyModel(models.Model):
user = models.ForeignKey(
to="User",
to_field="id",
on_delete=models.SET(func)
)
# related_name 反向操作时,使用参数指定的字段名,代替原反向查询时的'表名_set'
class Classes(models.Model):
name = models.CharField(max_length=32) class Student(models.Model):
name = models.CharField(max_length=32)
#theclass = models.ForeignKey(to="Classes") #不使用的情况下
theclass = models.ForeignKey(to="Classes", related_name="students") #当我们要查询某个班级关联的所有学生(反向查询)时,我们会这么写:
#models.Classes.objects.first().student_set.all() #本来这样写
models.Classes.objects.first().students.all()
# related_query_name 反向查询操作时,使用的连接前缀,用于替换表名
# models.CASCADE 删除关联数据,与之关联也删除
# db_constraint 是否在数据库中创建外键约束,默认为True。
models.DO_NOTHING
删除关联数据,引发错误IntegrityError models.PROTECT
删除关联数据,引发错误ProtectedError models.SET_NULL
删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空) models.SET_DEFAULT
删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值) models.SET 删除关联数据,
a. 与之关联的值设置为指定值,设置:models.SET(值)
b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)
其他字段参数
2.OneToOneField
一对一字段。
通常一对一字段用来扩展已有字段。(通俗的说就是一个人的所有信息不是放在一张表里面的,简单的信息一张表,隐私的信息另一张表,之间通过一对一外键关联)
字段参数:
# to 设置要关联的表。
# to_field 设置要关联的字段。
# on_delete 当删除关联表中的数据时,当前表与其关联的行的行为。(同外键,参考上面的例子)
class Author(models.Model):
name = models.CharField(max_length=32)
info = models.OneToOneField(to='AuthorInfo') class AuthorInfo(models.Model):
phone = models.CharField(max_length=11)
email = models.EmailField()
3. ManyToManyField
用于表示多对多的关联关系。在数据库中通过第三张表来建立关联关系
#to 设置要关联的表
# related_name 同ForeignKey字段。
# related_query_name 同ForeignKey字段。
# symmetrical 仅用于多对多自关联时,指定内部是否创建反向操作的字段。默认为True。
class Person(models.Model):
name = models.CharField(max_length=16)
friends = models.ManyToManyField("self")
#此时,person对象就没有person_set属性。 class Person(models.Model):
name = models.CharField(max_length=16)
friends = models.ManyToManyField("self", symmetrical=False)
#此时,person对象现在就可以使用person_set属性进行反向查询。
举例
#through
在使用ManyToManyField字段时,Django将自动生成一张表来管理多对多的关联关系。
但我们也可以手动创建第三张表来管理多对多关系,此时就需要通过through来指定第三张表的表名。
# through_fields 设置关联的字段。
# db_table 默认创建第三张表时,数据库中表的名称。
4.多对多关联关系的三种方式
1.全自动(稍微推荐使用*)
完全依赖于ManyToMany让django orm自动创建第三张表
优势:不需要你创建第三张表 自动创建
不足:由于第三张表不是你手动创建的,也就意味着第三张表字段是固定的无法做扩展
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8,decimal_places=2)
authors = models.ManyToManyField(to='Author') class Author(models.Model):
name = models.CharField(max_length=32)
2.纯手动(了解即可,不用)
不依赖于ManyToMany,自己创建第三张表,里面是有ForeignKey自己做两张表的关联
优势:第三张可以新增任意字段 扩展性较高
不足:orm查询时较为繁琐
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8,decimal_places=2) class Author(models.Model):
name = models.CharField(max_length=32) class Book2Author(models.Model):
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
create_time = models.DateField(auto_now_add=True)
3.半自动(大力推荐使用******)
设置ManyTomanyField参数,并指定自行创建的第三张表,依赖于ManyToMany,但是自己创建第三张表
优势:结合了全自动和纯手动的两个优点,可扩展性高
不足:多对多字段方法不支持了(add,set,remove,clear),需要通过第三张表的model来管理多对多关系
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8,decimal_places=2)
authors = models.ManyToManyField(to='Author',through='Book2Author',through_fields=('book','author'))
# through 告诉django orm 书籍表和作者表的多对多关系是通过Book2Author来记录的
# through_fields 告诉django orm记录关系时用过Book2Author表中的book字段和author字段来记录的
class Author(models.Model):
name = models.CharField(max_length=32)
# books = models.ManyToManyField(to='Book', through='Book2Author', through_fields=('author', 'book')) class Book2Author(models.Model):
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
create_time = models.DateField(auto_now_add=True)
5.元信息
ORM对应的类里面包含另一个Meta类,而Meta类封装了一些数据库的信息。主要字段如下:
# db_table ORM在数据库中的表名默认是 app_类名,可以通过db_table可以重写表名。
# index_together 联合索引。
# unique_together 联合唯一索引。
# ordering 指定默认按什么字段排序。
只有设置了该属性,我们查询到的结果才可以被reverse()。
class UserInfo(models.Model):
nid = models.AutoField(primary_key=True)
username = models.CharField(max_length=32) class Meta:
# 数据库中生成的表名称 默认 app名称 + 下划线 + 类名
db_table = "table_name" # 联合索引
index_together = [
("pub_date", "deadline"),
] # 联合唯一索引
unique_together = (("driver", "restaurant"),) ordering = ('name',) # admin中显示的表名称
verbose_name='哈哈' # verbose_name加s
verbose_name_plural=verbose_name
三、数据库优化查询
1.update()与save()的区别
两者都是对数据的修改保存操作,但是save()函数是将数据列的全部数据项全部重新写一遍,效率极低,比如book_obj.save()会将对象所有属性重新保存一次
而update()则是针对修改的项进行针对的更新效率高耗时少,比如,update(price),指哪打哪只会保存价格这一个属性
所以以后对数据的修改保存用update()
2.惰性查询
查询集 是惰性执行的 —— 创建查询集不会带来任何数据库的访问。你可以将过滤器保持一整天,直到查询集 需要求值时,Django 才会真正运行这个查询。
queryResult=models.Article.objects.all() # 只写这一句不会请求数据库 print(queryResult) # 直到你需要结果,此时才会查询数据库 for article in queryResult:
print(article.title) # 这样也会查询
orm内所有的语句操作 都是惰性查询:只会在你真正需要数据的时候才会走数据库,如果你单单只写orm语句时不会走数据库的
这样设计的好处 在于 减轻数据库的压力
3.only和defer 两对头
#only only会将括号内的所有的字段信息 全部查询出来封装对象中
res = models.Book.objects.only('title')
for r in res:
# print(r.title) # 只走一次数据库查询,将查询到的所有信息封装成一个对象,随后查询这些信息不需要再请求数据库,直接可以用点方法从对象中取出
print(r.price)
# 当你点击一个不是only括号内指定的字段的时候 不会报错 而是会帮你去数据库查询,循环几次查几次,频繁的走数据库查询,当你有成千上万条信息时对数据库造成一万点伤害
#defer defer会将不是括号内的所有的字段信息 全部查询出来封装对象中
res1 = models.Book.objects.defer('title') # defer与only是相反的
for r in res1:
# print(r.title)# 查询括号内的字段,会频繁的走数据库查询
print(r.price)#查询括号内没有的,只走一次
4. select_related 与 prefetch_related 两兄弟
res = models.Book.objects.all()
for r in res:
print(r.publish.name) #查询N次,这样是跨表查询,循环一次访问一次数据库,有一千万个书籍就查询一千万次 #常规的all方法,查询自己表里没有的属性,就需要跨表查询,虽然可以获取,但是你去查询一次就会访问一次数据库,查询其他表就不推荐这个了
#查询自己表里面有的属性时可以使用
#select_related 主动关联表
1. 主要针一对一和多对一关系进行优化。
2. 使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能
res = models.Book.objects.all().select_related('publish')
for r in res:
print(r.publish.name) #只查询一次,查询语句贼长包含两张表所有信息
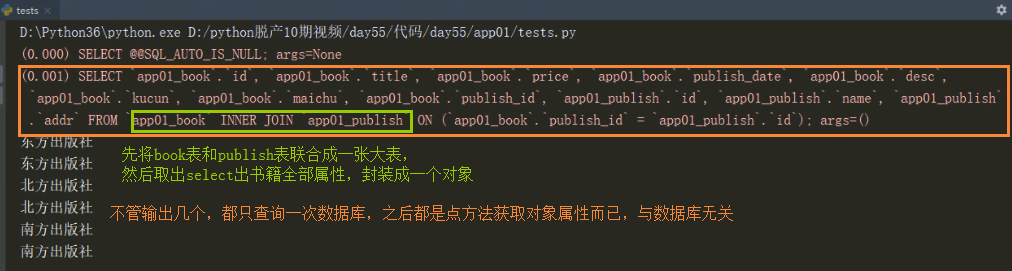
#1.select_related:会将FK表全部信息直接拿过来(可以一次性拿多张表)跟当前表所有信息拼接成一张大表,封装成一个对象
之后获取信息直接点方法获取,不需要再访问数据库从而降低你跨表查询 数据库的压力,但是速度会比较慢,活太多
#2.支持一次性拿多张表,如果当前表有多个外键,括号内用逗号链接
如果FK1表中还有外键还可以再关联下去,用双下划线链接,最后将N张表合并成一个超级表
res = models.Book.objects.all().select_related('外键字段1__外键字段2__外键字段3__外键字段4......')
#注意select_related括号只能放外键字段(一对一和一对多才行),res = models.Book.objects.all().select_related('authors')多对多的关系就会报错
# prefetch_related 不主动关联表
1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。
2. 优化方式是分别查询每个表,然后用Python处理他们之间的关系。
res = models.Book.objects.prefetch_related('publish')
for r in res:
print(r.publish.name) #只会走两次查询
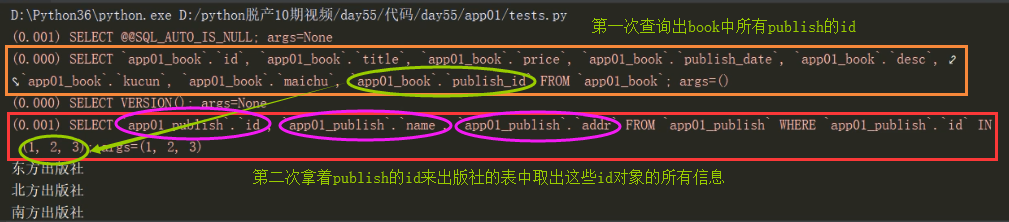
"""
不主动连表操作(但是内部给你的感觉像是连表操作了) 而是先将book表中所有的publish的id全部拿出来,再到Publish表中将id对应的所有的数据的所有信息全部取出
括号内有几个外键字段 就会走几次数据库查询操作
"""
06 ORM常用字段 关系字段 数据库优化查询的更多相关文章
- MS数据库优化查询最常见的几种方法
1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 5.网络速度慢 6.查询出的数据量过大 ...
- SQL Server数据库 优化查询速度
查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 ...
- django如何用orm增加manytomany关系字段(自定义表名)
不自定义表名的,网上有现成的,但如果自定义之后,则要变通一下了. app_insert = App.objects.get(name=app_name) site_insert = Site.obje ...
- Django框架之第六篇(模型层)--单表查询和必知必会13条、单表查询之双下划线、Django ORM常用字段和参数、关系字段
单表查询 补充一个知识点:在models.py建表是 create_time = models.DateField() 关键字参数: 1.auto_now:每次操作数据,都会自动刷新当前操作的时间 2 ...
- python 之 Django框架(ORM常用字段和字段参数、关系字段和和字段参数)
12.324 Django ORM常用字段 .id = models.AutoField(primary_key=True):int自增列,必须填入参数 primary_key=True.当model ...
- Django学习——图书管理系统图书修改、orm常用和非常用字段(了解)、 orm字段参数(了解)、字段关系(了解)、手动创建第三张表、Meta元信息、原生SQL、Django与ajax(入门)
1 图书管理系统图书修改 1.1 views 修改图书获取id的两种方案 1 <input type="hidden" name="id" value=& ...
- Django---ORM的常用字段和自定义字段,DjangoORM字段与数据库类型对应,字段参数和Meta的参数,Django的admin操作,13中orm操作方法,单标的双下方法
Django---ORM的常用字段和自定义字段,DjangoORM字段与数据库类型对应,字段参数和Meta的参数,Django的admin操作,13中orm操作方法,单标的双下方法 一丶ORM常用字段 ...
- ORM常用字段介绍
Django中的ORM Django项目使用MySQL数据库 1. 在Django项目的settings.py文件中,配置数据库连接信息: DATABASES = { "default&qu ...
- Django --ORM常用的字段和参数 多对多创建形式
1 ORM字段 AutoField int自增列,必须填入参数 primary_key=True.当model中如果没有自增列,则自动会创建一个列名为id的列. IntegerField 一个整数类型 ...
随机推荐
- 安卓开发学习日记 DAY3——TextView,EditView,ImageView
今天学习了一些控件的使用方法,包括TextView,EditView,ImageView 1.TextView,输出一个文本呗 主要属性有 android:id 标志 android:layout_w ...
- .net core 对dapper 新增 更新 删除 查询 的扩展
早期的版本一直用的是EF,但是EF一直有个让人很不爽的东西需要mapping 实体对象:如果没有映射的情况下连查询都没办法: 所以后来开始使用dapper 但是dapper都是直接用的是sql,这个对 ...
- 统计分析_集中趋势and离散程度
1.数组的集中趋势-如何定义数组的中心 1.1 常用几下几个指标来描述一个数组的集中趋势 均值-算术平均数 . 中位数-将数组升序或降序排列后,位于中间的数. 众数-数组中出现最多的数. 1.2 指标 ...
- matplotlib TransformNode类
TransformNode 是所有参与变换的类和所有需要无效自己或祖先的类的基类 方法: __init__(shorthand_name=None): 参数 [shorthand_name]: 别名 ...
- 类 文件 右下角呈现 红色小圆圈,里面有一个J 标记
intellj(idea) 项目中类 文件 右下角呈现 红色小圆圈,里面有一个J 标记,表明此为 未设置为源文件,没有编译,本来应该是属于源文件的,结果现在没有被标记为源文件,也就没法编译了.
- 数组的增加与删除(push、pop、unshift、shift)
1. 数组增删和换位置(原数组将被修改) push() //在数组最后面插入项,返回数组的长度 数组1改后的长度 = 数组1.push(元素1); pop() //取出数组中的最后一 ...
- 绕过CDN查找真实 IP 姿势总结
返回域名解析对应多个 IP 地址,网站可能部署CDN业务,我们就需要bypass CDN,去查找真正的服务器ip地址 0x01.域名搜集 由于成本问题,可能某些厂商并不会将所有的子域名都部署 CDN, ...
- matlab计算样本熵
计算14通道得脑电数据吗,将得出的样本熵插入Excel表格 a = zeros(1,14); b = a'; for i =1:14 b(i) = SampEn(d1_1(i,1:3000),2,0. ...
- Java SE —— 专栏总集篇
前言: Java 语言,是相对于其他语言而言,门槛低,而且功能还强大的一门编程语言,本人十分看好这一门语言,但是,它也是有深度的,看过本人的<数据结构与算法>专栏的同学们有福了,因为本人在 ...
- ASP.Net内置对象之网页之间传参(一)
Response对象 主要运用于数据从服务器发送到浏览器,可以输出数据.页面跳转.各个网页之间传参数等操作. 以下讲解几个常用例子: 在页面中输出数据 主要通过Write .WriteFile方法输出 ...