如何设计scalable 的系统 (转载)
Design a Scalable System
Design a system that scales to millions of users (AWS based)
Step 1: Outline use cases and constraints
Gather requirements and scope the problem. Ask questions to clarify use cases and constraints. Discuss assumptions.
Use cases
Solving this problem takes an iterative approach of:
1) Benchmark/Load Test
2) Profile for bottlenecks
3) address bottlenecks while evaluating alternatives and trade-offs, and
4) repeat, which is good pattern for evolving basic designs to scalable designs.
Unless you have a background in AWS or are applying for a position that requires AWS knowledge, AWS-specific details are not a requirement. However, much of the principles discussed in this exercise can apply more generally outside of the AWS ecosystem.
We'll scope the problem to handle only the following use cases
- User makes a read or write request
- Service does processing, stores user data, then returns the results
- Service needs to evolve from serving a small amount of users to millions of users
- Discuss general scaling patterns as we evolve an architecture to handle a large number of users and requests
- Service has high availability
Constraints and assumptions
State assumptions
- Traffic is not evenly distributed
- Need for relational data
- Scale from 1 user to tens of millions of users
- Denote increase of users as:
- Users+
- Users++
- Users+++
- ...
- 10 million users
- 1 billion writes per month
- 100 billion reads per month
- 100:1 read to write ratio
- 1 KB content per write
- Denote increase of users as:
Calculate usage
Clarify with your interviewer if you should run back-of-the-envelope usage calculations.
- 1 TB of new content per month
- 1 KB per write * 1 billion writes per month
- 36 TB of new content in 3 years
- Assume most writes are from new content instead of updates to existing ones
- 400 writes per second on average
- 40,000 reads per second on average
Handy conversion guide:
- 2.5 million seconds per month
- 1 request per second = 2.5 million requests per month
- 40 requests per second = 100 million requests per month
- 400 requests per second = 1 billion requests per month
Step 2: Create a high level design
Outline a high level design with all important components.

Step 3: Design core components
Dive into details for each core component.
Use case: User makes a read or write request
Goals
- With only 1-2 users, you only need a basic setup
- Single box for simplicity
- Vertical scaling when needed
- Monitor to determine bottlenecks
Start with a single box
- Web server on EC2
- Storage for user data
- MySQL Database Use Vertical Scaling:
- Simply choose a bigger box
- Keep an eye on metrics to determine how to scale up
- Use basic monitoring to determine bottlenecks: CPU, memory, IO, network, etc
- CloudWatch, top, nagios, statsd, graphite, etc
- Scaling vertically can get very expensive
- No redundancy/failover Trade-offs, alternatives, and additional details:
- The alternative to Vertical Scaling is Horizontal scaling
Start with SQL, consider NoSQL
The constraints assume there is a need for relational data. We can start off using a MySQL Database on the single box.
Trade-offs, alternatives, and additional details:
- See the Relational database management system (RDBMS) section
- Discuss reasons to use SQL or NoSQL
Assign a public static IP
- Elastic IPs provide a public endpoint whose IP doesn't change on reboot
- Helps with failover, just point the domain to a new IP
Use a DNS
Add a DNS such as Route 53 to map the domain to the instance's public IP.
Secure the web server
- Open up only necessary ports
- Allow the web server to respond to incoming requests from:
- 80 for HTTP
- 443 for HTTPS
- 22 for SSH to only whitelisted IPs
- Prevent the web server from initiating outbound connections
- Allow the web server to respond to incoming requests from:
Step 4: Scale the design
Identify and address bottlenecks, given the constraints.
Users+

Assumptions
Our user count is starting to pick up and the load is increasing on our single box. Our Benchmarks/Load Tests and Profiling are pointing to the MySQL Database taking up more and more memory and CPU resources, while the user content is filling up disk space.
We've been able to address these issues with Vertical Scaling so far. Unfortunately, this has become quite expensive and it doesn't allow for independent scaling of the MySQL Database and Web Server.
Goals
- Lighten load on the single box and allow for independent scaling
- Store static content separately in an Object Store
- Move the MySQL Database to a separate box
- Disadvantages
- These changes would increase complexity and would require changes to the Web Server to point to the Object Store and the MySQL Database
- Additional security measures must be taken to secure the new components
- AWS costs could also increase, but should be weighed with the costs of managing similar systems on your own
Store static content separately
- Consider using a managed Object Store like S3 to store static content
- Highly scalable and reliable
- Server side encryption
- Move static content to S3
- User files
- JS
- CSS
- Images
- Videos
Move the MySQL database to a separate box
- Consider using a service like RDS to manage the MySQL Database
- Simple to administer, scale
- Multiple availability zones
- Encryption at rest
Secure the system
- Encrypt data in transit and at rest
- Use a Virtual Private Cloud
- Create a public subnet for the single Web Server so it can send and receive traffic from the internet
- Create a private subnet for everything else, preventing outside access
- Only open ports from whitelisted IPs for each component
- These same patterns should be implemented for new components in the remainder of the exercise
Users++

Assumptions
Our Benchmarks/Load Tests and Profiling **show that our single **Web Server bottlenecks during peak hours, resulting in slow responses and in some cases, downtime. As the service matures, we'd also like to move towards higher availability and redundancy.
Goals
- The following goals attempt to address the scaling issues with the Web Server
- Based on the Benchmarks/Load Tests and *Profiling *, you might only need to implement one or two of these techniques
- Use Horizontal Scaling to handle increasing loads and to address single points of failure
- Add a Load Balancer such as Amazon's ELB or HAProxy
- ELB is highly available
- If you are configuring your own Load Balancer, setting up multiple servers in active-active or active-passive in multiple availability zones will improve availability
- Terminate SSL on the Load Balancer to reduce computational load on backend servers and to simplify certificate administration
- Use multiple ** Web Servers** spread out over multiple availability zones
- Use multiple MySQL instances in Master-Slave Failover mode across multiple availability zones to improve redundancy
- Add a Load Balancer such as Amazon's ELB or HAProxy
- Separate out the Web Servers from the Application Servers
- Scale and configure both layers independently
- Web Servers can run as a Reverse Proxy
- For example, you can add Application Servers handling Read APIs while others handle Write APIs
- Move static (and some dynamic) content to a Content Delivery Network (CDN) such as CloudFront to reduce load and latency
User+++

Note: Internal Load Balancers not shown to reduce clutter
Assumptions
Our Benchmarks/Load Tests and Profiling show that we are read-heavy (100:1 with writes) and our database is suffering from poor performance from the high read requests.
Goals
- The following goals attempt to address the scaling issues with the MySQL Database
- Based on the Benchmarks/Load Tests and Profiling, you might only need to implement one or two of these techniques
- Move the following data to a Memory Cache such as Elasticache to reduce load and latency:
- Frequently accessed content from MySQL
- First, try to configure the MySQL Database cache to see if that is sufficient to relieve the bottleneck before implementing a Memory Cache
- Session data from the Web Servers
- The Web Servers become stateless, allowing for Autoscaling
- Reading 1 MB sequentially from memory takes about 250 microseconds, while reading from SSD takes 4x and from disk takes 80x longer.1 Add MySQL Read Replicas to reduce load on the write master Add more Web Servers and Application Servers to improve responsiveness
- Frequently accessed content from MySQL
Add MySQL read replicas
- In addition to adding and scaling a Memory Cache, MySQL Read Replicas can also help relieve load on the MySQL Write Master
- Add logic to Web Server to separate out writes and reads Add Load Balancers in front of MySQL Read Replicas(not pictured to reduce clutter)
- Most services are read-heavy vs write-heavy
Users++++
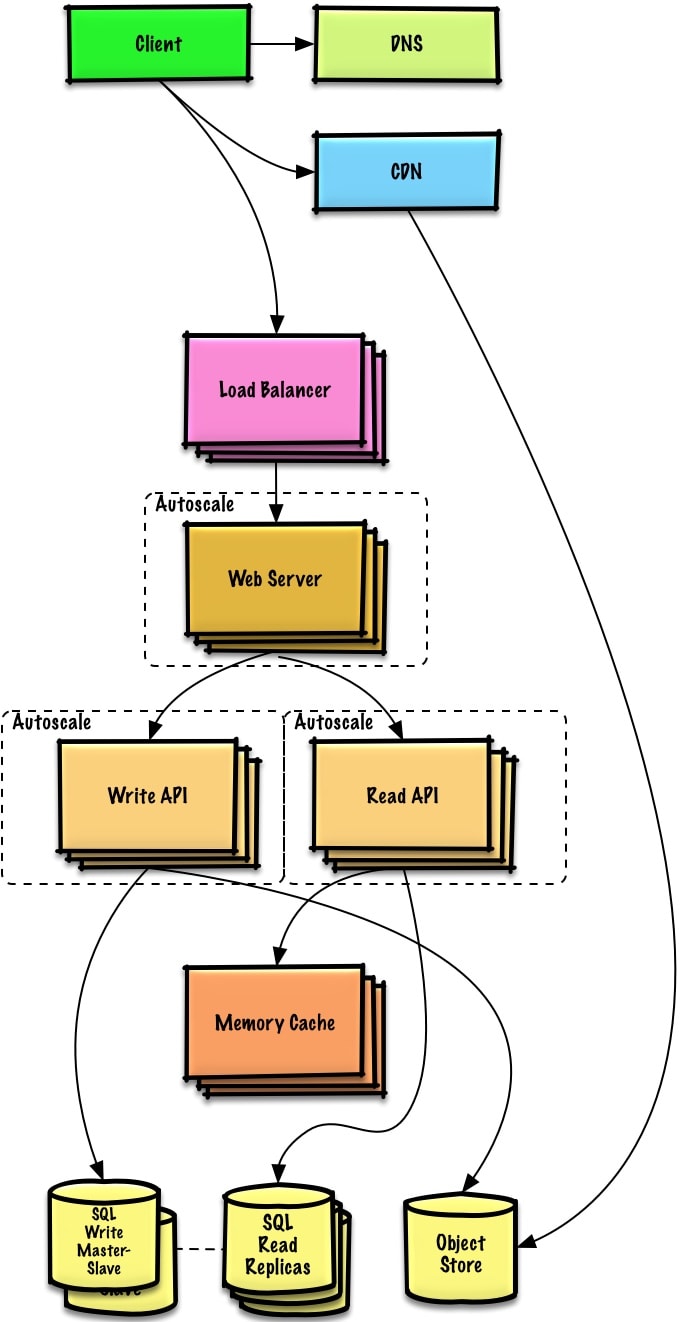
Assumptions
Our Benchmarks/Load Tests and Profiling show that our traffic spikes during regular business hours in the U.S. and drop significantly when users leave the office. We think we can cut costs by automatically spinning up and down servers based on actual load. We're a small shop so we'd like to automate as much of the DevOps as possible for Autoscaling and for the general operations.
Goals
- Add Autoscaling to provision capacity as needed
- Keep up with traffic spikes
- Reduce costs by powering down unused instances
- Automate DevOps
- Chef, Puppet, Ansible, etc
- Continue monitoring metrics to address bottlenecks
- Host level - Review a single EC2 instance
- Aggregate level - Review load balancer stats
- Log analysis - CloudWatch, CloudTrail, Loggly, Splunk, Sumo
- External site performance - Pingdom or New Relic
- Handle notifications and incidents - PagerDuty
- Error Reporting - Sentry
Add autoscaling
- Consider a managed service such as AWS Autoscaling
- Create one group for each Web Server and one for each Application Server type, place each group in multiple availability zones
- Set a min and max number of instances
- Trigger to scale up and down through CloudWatch
- Simple time of day metric for predictable loads or
- Metrics over a time period:
- CPU load
- Latency
- Network traffic
- Custom metric
- Disadvantages
- Autoscaling can introduce complexity
- It could take some time before a system appropriately scales up to meet increased demand, or to scale down when demand drops
Users+++++

Note: Autoscaling groups not shown to reduce clutter
Assumptions
As the service continues to grow towards the figures outlined in the constraints, we iteratively run Benchmarks/Load Tests and Profiling to uncover and address new bottlenecks.
Goals
We'll continue to address scaling issues due to the problem's constraints:
- If our MySQL Database starts to grow too large, we might considering only storing a limited time period of data in the database, while storing the rest in a data warehouse such as Redshift
- A data warehouse such as Redshift can comfortably handle the constraint of 1 TB of new content per month
- With 40,000 average read requests per second, read traffic for popular content can be addressed by scaling the Memory Cache, which is also useful for handling the unevenly distributed traffic and traffic spikes
- The SQL Read Replicas might have trouble handling the cache misses, we'll probably need to employ additional SQL scaling patterns
- 400 average writes per second (with presumably significantly higher peaks) might be tough for a single SQL Write Master-Slave, also pointing to a need for additional scaling techniques
SQL scaling patterns include:
- Federation
- Sharding
- Denormalization
- SQL Tuning
To further address the high read and write requests, we should also consider moving appropriate data to a NoSQL Database such as DynamoDB.
We can further separate out our Application Servers to allow for independent scaling. Batch processes or computations that do not need to be done in real-time can be done Asynchronously with Queues and Workers:
- For example, in a photo service, the photo upload and the thumbnail creation can be separated:
- Client uploads photo
- Application Server puts a job in a Queue such as SQS
- The Worker Service on EC2 or Lambda pulls work off the Queue then:
- Creates a thumbnail
- Updates a Database
- Stores the thumbnail in the Object Store
- For example, in a photo service, the photo upload and the thumbnail creation can be separated:
转载于:https://www.cnblogs.com/jxr041100/p/8415874.html
如何设计scalable 的系统 (转载)的更多相关文章
- Java核心知识点学习----线程中如何创建锁和使用锁 Lock,设计一个缓存系统
理论知识很枯燥,但这些都是基本功,学完可能会忘,但等用的时候,会发觉之前的学习是非常有意义的,学习线程就是这样子的. 1.如何创建锁? Lock lock = new ReentrantLock(); ...
- 八幅漫画理解使用JSON Web Token设计单点登录系统
用jwt这种token的验证方式,是不是必须用https协议保证token不被其他人拦截? 是的.因为其实只是Base64编码而已,所以很容易就被解码了.如果你的JWT被嗅探到,那么别人就可以相应地解 ...
- 游戏服务器设计之NPC系统
游戏服务器设计之NPC系统 简介 NPC系统是游戏中非常重要的系统,设计的好坏很大程度上影响游戏的体验.NPC在游戏中有如下作用: 引导玩家体验游戏内容,一般游戏内有很多主线.支线任务,而任务的介绍. ...
- 八幅漫画理解使用 JSON Web Token 设计单点登录系统
原文出处: John Wu 上次在<JSON Web Token – 在Web应用间安全地传递信息>中我提到了JSON Web Token可以用来设计单点登录系统.我尝试用八幅漫画先让大家 ...
- [转]八幅漫画理解使用JSON Web Token设计单点登录系统
上次在<JSON Web Token - 在Web应用间安全地传递信息>中我提到了JSON Web Token可以用来设计单点登录系统.我尝试用八幅漫画先让大家理解如何设计正常的用户认证系 ...
- Scratch3.0设计的插件系统(上篇)
我们每个人在内心深处都怀有一个梦想: 希望创造出一个鲜活的世界,一个宇宙.处在我们生活的中间.被训练为架构师的那些人,拥有这样的渴望: 在某一天,在某一个地方,因为某种原因,创造出了一个不可思议的.美 ...
- Java核心知识点 --- 线程中如何创建锁和使用锁 Lock , 设计一个缓存系统
理论知识很枯燥,但这些都是基本功,学完可能会忘,但等用的时候,会发觉之前的学习是非常有意义的,学习线程就是这样子的. 1.如何创建锁? Lock lock = new ReentrantLock(); ...
- (转载)数据库表设计-水电费缴费系统(oracle)
水电缴费管理系统数据表设计 SQL建表脚本: 1 --建表 2 --管理人员表 admin 3 create table admin( 4 admin_id varchar2(3) not null, ...
- 如何设计一个RPC系统
版权声明:本文由韩伟原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/162 来源:腾云阁 https://www.qclou ...
随机推荐
- php--MongoDB的使用
添加 $collection = (new MongoDB\Client)->test->users; // 增加一条 $insertOneResult = $collection-> ...
- flask-sqlalchemy的基本使用
flask-sqlalchemy 1 .配置应用和基本使用 和sqlalchemy一样,先定义好数据库配置和db_url.然后在app的config加入SQLALCHEMY_DATABASE_URI等 ...
- vue技术栈进阶(02.路由详解—基础)
路由详解(一)--基础: 1)router-link和router-view组件 2)路由配置 3)JS操作路由
- "一号标题"组件:<h1> —— 快应用组件库H-UI
 <import name="h1" src="../Common/ui/h-ui/text/c_h1"></import> < ...
- tf.nn.softmax_cross_entropy_with_logits 分类
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None) 参数: logits:就是神经网络最后一层的输出,如果有batch ...
- F. 蚂蚁装修
单点时限: 2.0 sec 内存限制: 512 MB 还有一个月就开学了,爱学习的小蚂蚁想庆祝一下!于是它要把它的“家”装修一下.首先要做的就是贴地板.小蚂蚁“家”的地面可以看成一个2∗N 的方格 , ...
- 爬虫实战2_有道翻译sign破解
目标url 有道翻译 打开网站输入要翻译的内容,一一查找network发现数据返回json格式,红框就是我们的翻译结果 查看headers,发现返回结果的请求是post请求,且携带一大堆form_da ...
- redis: Zset有序集合类型(七)
存值:zadd myset 1 one 取值:zrange myset 0 -1 127.0.0.1:6379> zadd myset 1 one #存值 分值为1 (integer) 1 12 ...
- Spring5:面向切面
静态代理 缺点:一个真实角色就会产生一个代理角色,代码量会翻倍! 场景:要在写好的实现方法上加入日志功能(公共功能),不要修改原代码 1:原代码 业务接口: package com.spring; p ...
- java第八周课后作业
1.系统小练习 package homework; import java.util.Random; import java.util.Scanner; public class Menu { pub ...