Django 学习之Django Rest Framework_序列化器_Serializer
作用:
1.序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串。
2.反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型。
3.反序列化,完成数据校验功能。
一.定义序列化器
Django REST framework中的Serializer使用类来定义,须继承自rest_framework.serializers.Serializer。
接下来,为了方便演示序列化器的使用,我们先创建一个新的子应用sers
python manage.py startapp sers
我们已有了一个数据库模型类students
verbose_name="姓名" 将字段用在后端xadmin中实现中文显示
from django.db import models # Create your models here.
class Student(models.Model):
# 模型字段
name = models.CharField(max_length=100,verbose_name="姓名",help_text="提示文本:账号不能为空!")
sex = models.BooleanField(default=True,verbose_name="性别")
age = models.IntegerField(verbose_name="年龄")
class_null = models.CharField(max_length=5,verbose_name="班级编号")
description = models.TextField(verbose_name="个性签名") class Meta:
db_table="tb_student"
verbose_name = "学生"
verbose_name_plural = verbose_name
models.py
我们想为这个模型类提供一个序列化器,在sers下新建一个serializers.py可以定义如下:
from rest_framework import serializers # 声明序列化器,所有的序列化器都要直接或者间接继承于 Serializer
# 其中,ModelSerializer是Serializer的子类,ModelSerializer在Serializer的基础上进行了代码简化
class StudentSerializer(serializers.Serializer):
"""学生信息序列化器"""
# 1. 需要进行数据转换的字段
id = serializers.IntegerField()
name = serializers.CharField()
age = serializers.IntegerField()
sex = serializers.BooleanField()
description = serializers.CharField() # 2. 如果序列化器集成的是ModelSerializer,则需要声明调用的模型信息 # 3. 验证代码 # 4. 编写添加和更新模型的代码
serializers.py
还需要注册新建的sers
'sers.apps.SersConfig',
注意:serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。serializer是独立于数据库之外的存在。
将__init__.py 下的pymysql从students应用剪切到项目下的__init__.py文件下。
二.创建Serializer对象
定义好Serializer类后,就可以创建Serializer对象了。
Serializer的构造方法为:
Serializer(instance=None, data=empty, **kwarg)
说明:
1)用于序列化时,将模型类对象传入instance参数
2)用于反序列化时,将要被反序列化的数据传入data参数
3)除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据,如
serializer = AccountSerializer(account, context={'request': request})
通过context参数附加的数据,可以通过Serializer对象的context属性获取。
1. 使用序列化器的时候一定要注意,序列化器声明了以后,不会自动执行,需要我们在视图中进行调用才可以。
2. 序列化器无法直接接收数据,需要我们在视图中创建序列化器对象时把使用的数据传递过来。
3. 序列化器的字段声明类似于我们前面使用过的表单系统。
4. 开发restful api时,序列化器会帮我们把模型数据转换成字典.
5. drf提供的视图会帮我们把字典转换成json,或者把客户端发送过来的数据转换字典.
三.序列化器的使用(主要)
1.序列化
总路由中的urls.py:
from django.contrib import admin
from django.urls import path, include urlpatterns = [
path('admin/', admin.site.urls),
path('drf/', include("students.urls")),
path('ser/', include("ser.urls")),
]
总的urls.py
sers应用下的urls.py文件:
序列化的只包含一条数据的情况下:
sers应用下的urls.py文件:
from django.urls import path, re_path
from . import views urlpatterns = [
re_path(r"^student/(?P<pk>\d+)/$", views.Student1View.as_view()),
]
urls.py
sers应用下的views.py文件:
from django.http import JsonResponse
from django.views import View
from students.models import Student
from .serializers import StudentSerializer class Student1View(View):
"""使用序列化器进行数据的序列化操作"""
"""序列化器转换一条数据[模型转换成字典]"""
def get(self, request, pk):
# 接收客户端传过来的参数,进行过滤查询,先查出学生对象
student = Student.objects.get(pk=pk)
# 转换数据类型
# 1.实例化序列化器类
"""
StudentSerializer(instance=模型对象或者模型列表,客户端提交的数据,额外要传递到序列化器中使用的数据)
"""
serializer = StudentSerializer(instance=student) # 2.查看序列化器的转换结果
print(serializer.data)
return JsonResponse(serializer.data)
views.py
效果图如下:
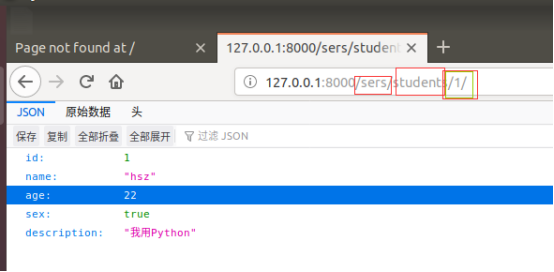
多条数据的查询集QuerySet情况
如果要被序列化的是包含多条数据的查询集QuerySet,可以通过添加many=True参数补充说明。代码如下:
sers应用下的urls.py文件改为:
from django.urls import path, re_path
from . import views urlpatterns = [
path("students/", views.Student2View.as_view()),
re_path(r"^student/(?P<pk>\d+)/$", views.Student1View.as_view()),
]
urls.py
最后sers应用下的views.py
from django.shortcuts import render # Create your views here.
from django.http import JsonResponse
from django.views import View
from students.models import Student
from .serializers import StudentSerializer class Student1View(View):
"""使用序列化器进行数据的序列化操作"""
"""序列化器转换一条数据[模型转换成字典]""" def get(self, request, pk):
# 接收客户端传过来的参数,进行过滤查询,先查出学生对象
student = Student.objects.get(pk=pk)
# 转换数据类型
# 1.实例化序列化器类
"""
StudentSerializer(instance=模型对象或者模型列表,客户端提交的数据,额外要传递到序列化器中使用的数据)
"""
serializer = StudentSerializer(instance=student) # 2.查看序列化器的转换结果
print(serializer.data)
return JsonResponse(serializer.data) class Student2View(View):
"""序列化器转换多条数据[模型转换成字典]""" def get(self, request):
student_list = Student.objects.all()
print(student_list)
# 序列化器转换多个数据
# many=True 表示本次序列化器转换如果有多个模型对象列参数,则必须声明 Many=True
serializer = StudentSerializer(instance=student_list, many=True) print(serializer.data)
return JsonResponse(serializer.data, safe=False)
views.py
最后效果图为:(下图此效果为搜狐浏览器,其他浏览器的数据并没有那么整齐)
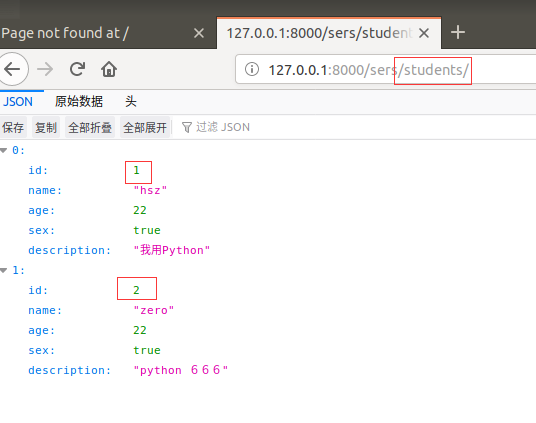
而且依然可以实现一条数据数据的情况。
2.1反序列化-数据校验
使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象。
在获取反序列化的数据前,必须调用is_valid()方法进行验证,验证成功返回True,否则返回False。
验证失败,可以通过序列化器对象的errors属性获取错误信息,返回字典,包含了字段和字段的错误。is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True参数开启。
验证成功,可以通过序列化器对象的validated_data属性获取数据。
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。
sers应用下的urls.py文件:
urlpatterns = [
path("students/", views.Student2View.as_view()),
re_path(r"^student/(?P<pk>\d+)/$", views.Student1View.as_view()),
# 对数据提交时,进行校验
path('student3/', views.Student3View.as_view()),
]
urls.py
sers应用下的serializers.py文件:
"""
在drf中,对于客户端提供的数据,往往需要验证数据的有效性,这部分代码是写在序列化器中的。
在序列化器中,已经提供三个地方给我们针对客户端提交的数据进行验证。
1. 内置选项,字段声明的小圆括号中,以选项存在作为验证提交
2. 自定义方法,在序列化器中作为对象方法来提供验证[ 这部分验证的方法,必须以"validate_<字段>" 或者 "validate" 作为方法名 ]
3. 自定义函数,在序列化器外部,提前声明一个验证代码,然后在字段声明的小圆括号中,通过 "validators=[验证函数1,验证函数2...]"
"""
from rest_framework import serializers
from students.models import Student
# 自定义函数
def check_user(data):
if data == "teacher":
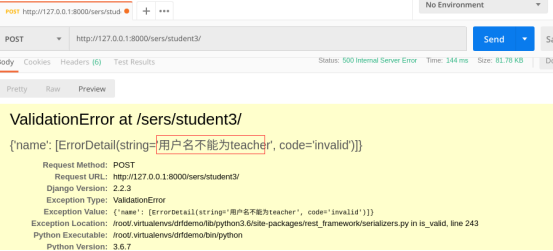
raise serializers.ValidationError("用户名不能为teacher")
return data class Student3Serializer(serializers.Serializer):
# 校验的第一种方式(内置选项) validators=[check_user]
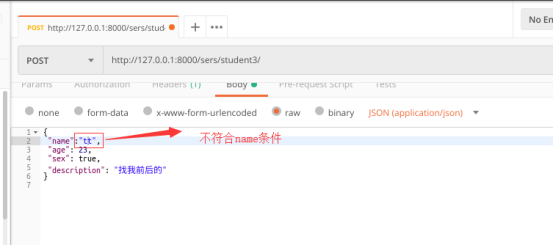
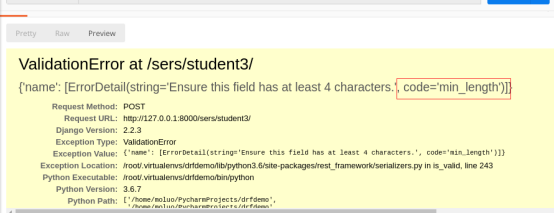
name = serializers.CharField(max_length=10, min_length=4, validators=[check_user])
age = serializers.IntegerField(max_value=150, min_value=1)
sex = serializers.BooleanField(required=True) # 默认为True
description = serializers.CharField() # 3. 可选[ 用于对客户端提交的数据进行验证 ]
# 第三步,进行数据校验
# 校验第二种方式(自定义方法)
# 对单个字段进行校验
def validate_name(self, data):
if data == "root":
raise serializers.ValidationError("用户不能为root")
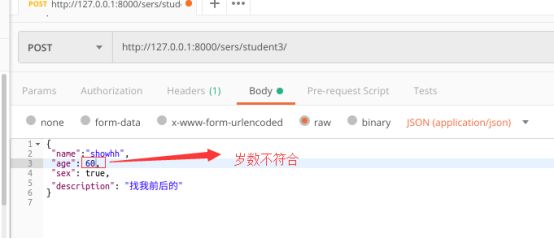
return data def validate_age(self, data):
if data > 50:
raise serializers.ValidationError("此岁数已经打破学生年龄记录")
return data # 对多个字段进行校验
def validate(self, attrs):
name = attrs.get('name')
age = attrs.get('age') if name == 'bili' and age == 45:
raise serializers.ValidationError("这是校长的信息,输错了吧")
return attrs
serializers.py
sers应用下的views.py文件:
from sers.serializers import Student3Serializer
import json class Student3View(View):
# 反序列化之数据校验
def post(self, request):
# 对数据进行解码
data = request.body.decode()
# 对数据(用户提交的数据)进行反序列化
data_dict = json.loads(data)
# 调用序列化器进行实例化
serializer = Student3Serializer(data=data_dict)
# 进行校验
# is_valid在执行的时候,会自动先后调用 字段的内置选项,自定义验证方法,自定义验证函数
# 调用序列化器中写好的验证代码
# 验证结果
# raise_exception=True 抛出验证错误信息,并阻止代码继续往后运行
serializer.is_valid(raise_exception=True) # 获取错误信息
print(serializer.errors) # 获取合法的数据信息
print(serializer.validated_data) return HttpResponse("OK")
# return JsonResponse(serializer.validated_data)
views.py
运行程序并用Post进行测试:
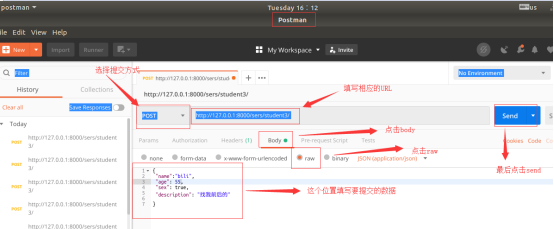
测试一:
正常数据测试:
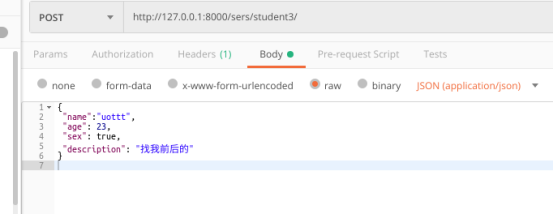
测试二:name不符合4个字符的内置规定
测试三:单个字段不符合

测试四:多个字段效验不符合
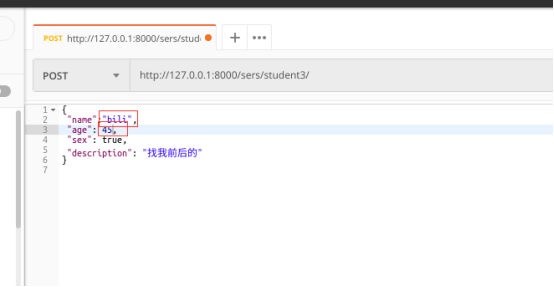
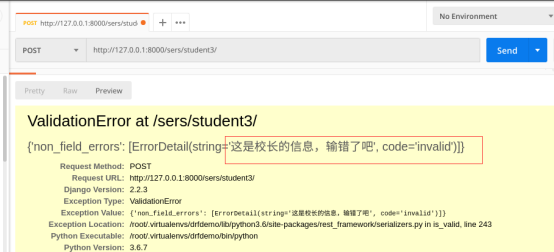
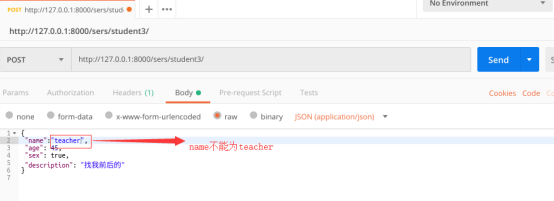
测试五:自定义函数效验不符合
2.2反序列化-保存数据
前面的验证数据成功后,我们可以使用序列化器来完成数据反序列化的过程.这个过程可以把数据转成模型类对象。
可以通过在序列化器中实现create()和update()两个方法来实现。
sers应用下serializers.py文件:
from rest_framework import serializers
from students.models import Student class Student3Serializer(serializers.Serializer):
# 校验的第一种方式(内置选项)
name = serializers.CharField(max_length=10, min_length=4, validators=[check_user])
age = serializers.IntegerField(max_value=150, min_value=1)
sex = serializers.BooleanField(required=True) # 默认为True
description = serializers.CharField() # 3. 可选[ 用于对客户端提交的数据进行验证 ]
# 第三步,进行数据校验
# 校验第二种方式(自定义方法)
# 对单个字段进行校验
def validate_name(self, data):
if data == "root":
raise serializers.ValidationError("用户不能为root")
return data def validate_age(self, data):
if data > 50:
raise serializers.ValidationError("此岁数已经打破学生年龄记录")
return data # 对多个字段进行校验
def validate(self, attrs):
name = attrs.get('name')
age = attrs.get('age') if name == 'bili' and age == 45:
raise serializers.ValidationError("这是校长的信息,输错了吧")
return attrs # 第四步,进行持久化处理(create 和update)
def create(self, validated_data):
# 接受客户端提交的新数据
name = validated_data.get('name')
age = validated_data.get('age')
sex = validated_data.get('sex')
description = validated_data.get('description') instance = Student.objects.create(name=name, age=age, sex=sex, description=description)
# instance = Student.objects.create(**validated_data) print("序列号器的create方法", instance) return instance def update(self, instance, validated_data):
# 用于在反序列化中对于验证完成的数据进行保存更新
name = validated_data.get('name')
age = validated_data.get('age')
sex = validated_data.get('sex')
description = validated_data.get('description') # 更新数据
instance.name = name
instance.age = age
instance.sex = sex
instance.description = description # 同步数据到数据库
instance.save() return instance
serializers.py
实现了上述两个方法后,在反序列化数据的时候,就可以通过save()方法返回一个数据对象实例了
sers应用下views.py文件:
from sers.serializers import Student3Serializer
import json class Student3View(View):
# 反序列化之数据校验
def post(self, request):
# 对数据进行解码
data = request.body.decode()
# 对数据(用户提交的数据)进行反序列化
data_dict = json.loads(data)
# 调用序列化器进行实例化
serializer = Student3Serializer(data=data_dict)
# 进行校验
# is_valid在执行的时候,会自动先后调用 字段的内置选项,自定义验证方法,自定义验证函数
# 调用序列化器中写好的验证代码
# 验证结果
# raise_exception=True 抛出验证错误信息,并阻止代码继续往后运行
serializer.is_valid(raise_exception=True) # 获取错误信息
print(serializer.errors) # 获取合法的数据信息
print(serializer.validated_data) # save 表示让序列化器开始执行反序列化代码。create和update的代码
serializer.save() # return HttpResponse("OK")
return JsonResponse(serializer.validated_data)
views.py
测试:
post一组正常的数据:
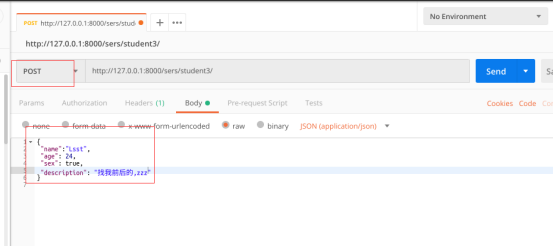
返回新增的数据:
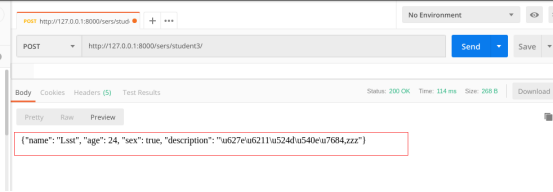
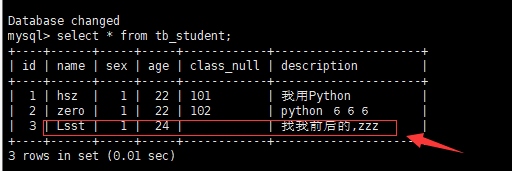
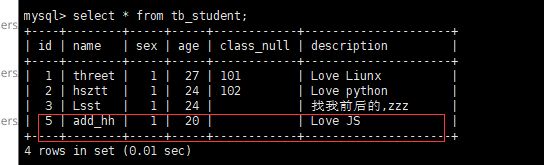
进数据库,发现数据已经持久化:
如果创建序列化器对象的时候,没有传递instance实例,则调用save()方法的时候,create()被调用,相反,如果传递了instance实例,则调用save()方法的时候,update()被调用。
sers应用下views.py文件添加一个类作为更新数据:
class Student4View(View):
def put(self, request, pk):
data = request.body.decode()
import json
data_dict = json.loads(data)
# 通过pk从数据库中得到相应的原数据
student_obj = Student.objects.get(pk=pk)
print(pk)
# 有instance参数,调用save方法,就会调用update方法。
serializer = Student3Serializer(instance=student_obj, data=data_dict)
# print(serializer)
serializer.is_valid(raise_exception=True) serializer.save() # 触发序列器中的update方法 return JsonResponse(serializer.validated_data)
views.py
sers应用下的urls.py文件:
from django.urls import path, re_path
from . import views urlpatterns = [ path("students/", views.Student2View.as_view()),
re_path(r"^students/(?P<pk>\d+)/$", views.Student1View.as_view()), path("student3/", views.Student3View.as_view()),
# 反序列化阶段(update, 执行的请求方式为put)
re_path(r'^student4/(?P<pk>\d+)/$', views.Student4View.as_view()), ]
urls.py
3.序列化与反序列化合并使用
开发中往往一个资源的序列化和反序列化阶段都是写在一个序列化器中的
所以我们可以把上面的两个阶段合并起来,以后我们再次写序列化器,则直接按照以下风格编写即可。
sers应用下的serializers.py文件内容可以直接使用反序列化-保存数据中的Student3Serializer类:
在sers应用下urls.py文件:
from django.urls import path, re_path
from . import views urlpatterns = [ path("students/", views.Student2View.as_view()),
re_path(r"^students/(?P<pk>\d+)/$", views.Student1View.as_view()), path("student3/", views.Student3View.as_view()),
# 反序列化阶段(update, 执行的请求方式为put)
re_path(r'^student4/(?P<pk>\d+)/$', views.Student4View.as_view()),
# 一个序列化器同时实现序列化和反序列化
path('student5/', views.Student5View.as_view()), ]
urls.py
在sers应用下views.py文件:
class Student5View(View):
def get(self, request):
# 获取所有数据
student_list = Student.objects.all()
serializer = Student3Serializer(instance=student_list, many=True) return JsonResponse(serializer.data, safe=False) def post(self, request):
data = request.body.decode()
data_dict = json.loads(data)
# 调用序列化器进行实例化
serializer = Student3Serializer(data=data_dict)
# 进行校验
serializer.is_valid(raise_exception=True)
serializer.save() return JsonResponse(serializer.data)
views.py
4.模型类序列化器
如果我们想要使用序列化器对应的是Django的模型类,DRF为我们提供了ModelSerializer模型类序列化器来帮助我们快速创建一个Serializer类。
在sers应用下serializers.py文件定义模型类序列化器:
from rest_framework import serializers
from students.models import Student """
我们可以使用ModelSerializer来完成模型类序列化器的声明
这种基于ModelSerializer声明序列化器的方式有三个优势:
1. 可以直接通过声明当前序列化器中指定的模型中把字段声明引用过来(就是如果都不在加限制字段条件,默认的会是models.py的内容)
2. ModelSerializer是继承了Serializer的所有功能和方法,同时还编写update和create
3. 模型中同一个字段中关于验证的选项,也会被引用到序列化器中一并作为选项参与验证
""" class StudentModelSerializer(serializers.ModelSerializer):
class Meta:
model = Student
# fields = "__all__" # 表示引用所有字段
fields = ["id", "name", "age", "description", "is_18"] # is_18 为自定制字段,需要在models里自定义方法。
# exclude = ["age"] # 使用exclude可以明确排除掉哪些字段, 注意不能和fields同时使用。
# 传递额外的参数,为ModelSerializer添加或修改原有的选项参数
extra_kwargs = {
"name": {"max_length": 10, "min_length": 4, "validators": [check_user]},
"age": {"max_value": 150, "min_value": 0},
} def validate_name(self, data):
if data == "root":
raise serializers.ValidationError("用户名不能为root!")
return data def validate(self, attrs):
name = attrs.get('name')
age = attrs.get('age') if name == "alex" and age == 22:
raise serializers.ValidationError("alex在22时的故事。。。") return attrs
serializers.py
在sers应用下的urls.py文件:
from django.urls import path, re_path
from . import views urlpatterns = [ path("students/", views.Student2View.as_view()),
re_path(r"^students/(?P<pk>\d+)/$", views.Student1View.as_view()), path("student3/", views.Student3View.as_view()),
# 反序列化阶段(update, 执行的请求方式为put)
re_path(r'^student4/(?P<pk>\d+)/$', views.Student4View.as_view()),
# 一个序列化器同时实现序列化和反序列化
path('student5/', views.Student5View.as_view()),
# 使用模型类序列化器
path('student6/', views.Student6View.as_view()), ]
urls.py
在sers应用下views.py文件:
from sers.serializers import StudentModelSerializer class Student6View(View):
# 如果是get方法请求数据
def get(self, request):
# 获取所有数据
student_list = Student.objects.all() serializer = StudentModelSerializer(instance=student_list, many=True) return JsonResponse(serializer.data, safe=False) # 如果是post方法新增数据
def post(self, request):
data = request.body.decode()
data_dict = json.loads(data) serializer = StudentModelSerializer(data=data_dict) serializer.is_valid(raise_exception=True) serializer.save() return JsonResponse(serializer.data)
views.py
原来model.py的内容改为:(在序列化器不对数据再限制的时候,会触发模型的限制条件)
from django.db import models # Create your models here.
class Student(models.Model):
# 模型字段
name = models.CharField(max_length=100, verbose_name="姓名")
sex = models.BooleanField(default=1, verbose_name="性别")
age = models.IntegerField(verbose_name="年龄")
class_null = models.CharField(max_length=5, verbose_name="班级编号")
description = models.TextField(max_length=1000, verbose_name="个性签名") class Meta:
db_table = "tb_student"
verbose_name = "学生"
verbose_name_plural = verbose_name def is_18(self):
return "big!" if self.age >=18 else "small!"
models.py
测试一:get请求数据
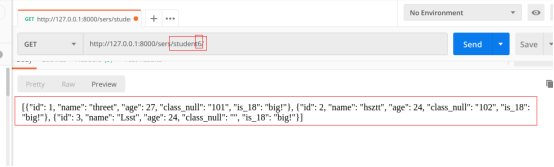
测试二:post提交数据
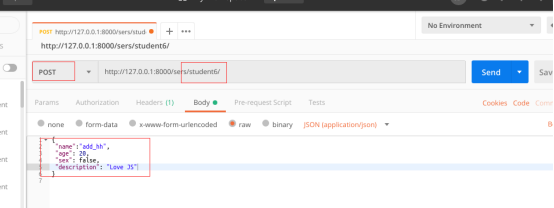
返回
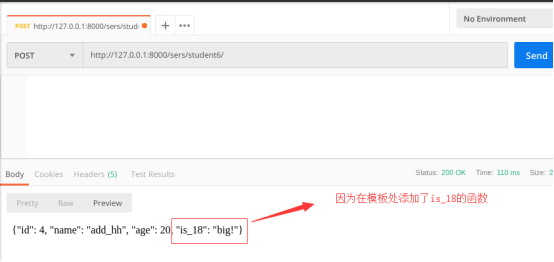
数据库新增了一条数据:
Django 学习之Django Rest Framework_序列化器_Serializer的更多相关文章
- 写写Django中DRF框架概述以及序列化器对象serializer的构造方法以及使用
写写Django中DRF框架概述以及序列化器对象serializer的构造方法以及使用 一.了解什么是DRF DRF: Django REST framework Django REST framew ...
- Django学习之django自带的contentType表 GenericRelation GenericForeignKey
Django学习之django自带的contentType表 通过django的contentType表来搞定一个表里面有多个外键的简单处理: 摘自:https://blog.csdn.net/a ...
- day 94 Django学习之django自带的contentType表
Django学习之django自带的contentType表 通过django的contentType表来搞定一个表里面有多个外键的简单处理: 摘自:https://blog.csdn.net/a ...
- day 93 Django学习之django自带的contentType表
Django学习之django自带的contentType表 通过django的contentType表来搞定一个表里面有多个外键的简单处理: 摘自:https://blog.csdn.net/a ...
- Django学习之django自带的contentType表
Django学习之django自带的contentType表 通过django的contentType表来搞定一个表里面有多个外键的简单处理: 摘自:https://blog.csdn.net/aar ...
- day 91 Django学习之django自带的contentType表
Django学习之django自带的contentType表 通过django的contentType表来搞定一个表里面有多个外键的简单处理: 摘自:https://blog.csdn.net ...
- Django 学习之Django Rest Framework(DRF)
一. WEB应用模式 在开发Web应用中,有两种应用模式 1. 前后端不分离 把html模板文件和django的模板语法结合渲染完成以后才从服务器返回给客户. 2. 前后端分离 二. API接口 AP ...
- django学习-10.django连接mysql数据库和创建数据表
1.django模型 Django对各种数据库提供了很好的支持,包括:PostgreSQL.MySQL.SQLite.Oracle. Django为这些数据库提供了统一的调用API. 我们可以根据自己 ...
- Django学习笔记 Django的工程目录
mysite├── manage.py 管理项目:包括数据库建立.服务器运行.测试……└── mysite ├── __init__.py ├── settings.py 配置文件:应用 ...
随机推荐
- 大端(bigend)与小端(littleend)
大端:是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中: 小端:是指数据的高位保存在内存的高地址中,而数据的高 ...
- 【网摘】检测 iframe 是否加载完成
var iframeSet = document.getElementById("iframeSet"); //需要检测的 iframe if(iframeSet.attachEv ...
- MyBatis-Plus学习笔记(3):分页查询
依赖配置可参考:MyBatis-Plus学习笔记(1):环境搭建以及基本的CRUD操作 分页配置 @Configuration public class PlusConfig { @Bean publ ...
- 【知识学习】Sublime Text 快捷键精华版
Sublime Text 快捷键精华版 Ctrl+Shift+P:打开命令面板 Ctrl+P:搜索项目中的文件 Ctrl+G:跳转到第几行 Ctrl+W:关闭当前打开文件 Ctrl+Shift+W:关 ...
- 三分钟让你秒懂.Net生态系统
提到.Net的时候,大多数人的第一反应可能就是.Net Framework和Visual Studio..Net Framework的第一个版本发布与2002年2月13日,这对于科技发展日新月异的时代 ...
- 创建DataTable与DataGridView进行绑定
private DataTable dt = new DataTable(); BindingSource bs = new BindingSource(); /// <summary> ...
- VS中编码格式的问题(待总结)
今天又遇到这样的事情了,VS中代码明明是正确的,却报某个变量未定义.百思不得解,前面增加了一个换行之后,竟然又神奇般的复原了. 最后确认是编码格式的问题,后来把有问题的那部分代码粘贴到微软的" ...
- 七、SXSSFWorkbook生成大excle,避免内存溢出
1.SXSSFWorkbook理解: SXSSFWorkbook是用来生成海量excel数据文件,主要原理是借助临时存储空间生成excel,SXSSFWorkbook专门处理大数据,对于大型excel ...
- python requirements.txt批量下载安装离线
有些情况下我们需要下载N个第三方包,或者下载的包依赖其它包,一个个下载非常浪费时间.这时我们可以通过如下两种方式的命令批量下载. 方式1 pip download -d /tmp/packagesdi ...
- MySQL8.0 ROW_NUMBER、RANK、DENSE_RANK窗口函数 分组排序排名
MySQL8.0 (ROW_NUMBER)窗口函数 排名 暂时理解函数意义,后面再进行优化,如果有关变量排序,查看这个大哥的 mysql的分组排序和变量赋值顺序 先查看一个例子: # 按照每科课程分数 ...