Spark入门(五)--Spark的reduce和reduceByKey
reduce和reduceByKey的区别
reduce和reduceByKey是spark中使用地非常频繁的,在字数统计中,可以看到reduceByKey的经典使用。那么reduce和reduceBykey的区别在哪呢?reduce处理数据时有着一对一的特性,而reduceByKey则有着多对一的特性。比如reduce中会把数据集合中每一个元素都处理一次,并且每一个元素都对应着一个输出。而reduceByKey则不同,它会把所有key相同的值处理并且进行归并,其中归并的方法可以自己定义。
例子
在单词统计中,我们采用的就是reduceByKey,对于每一个单词我们设置成一个键值对(key,value),我们把单词作为key,即key=word,而value=1,因为遍历过程中,每个单词的出现一次,则标注1。那么reduceByKey则会把key相同的进行归并,然后根据我们定义的归并方法即对value进行累加处理,最后得到每个单词出现的次数。而reduce则没有相同Key归并的操作,而是将所有值统一归并,一并处理。
spark的reduce
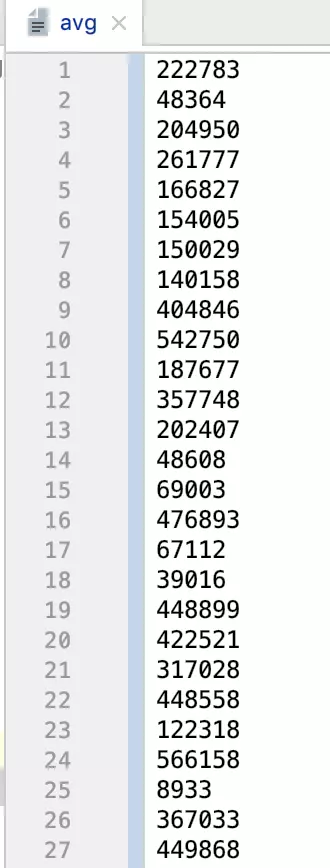
我们采用scala来求得一个数据集中所有数值的平均值。该数据集包含5000个数值,数据集以及下列的代码均可从github下载,数据集名称为"avg"。为求得这个数据集中的平均值,我们先用map对文本数据进行处理,将其转换成long类型。
数据集内容:
reduce求平均值scala实现
import org.apache.spark.{SparkConf, SparkContext}
object SparkReduce {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SparkReduce")
val sc = new SparkContext(conf)
//将String转成Long类型
val numData = sc.textFile("./avg").map(num => num.toLong)
//reduce处理每个值
println(numData.reduce((x,y)=>{
println("x:"+x)
println("y:"+y)
x+y
})/numData.count())
}
}
reduce求平均值Java实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
public class SparkReduceJava {
public static void main(String[] main){
SparkConf conf = new SparkConf().setAppName("SparkReduceJava").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
reduceJava(sc);
reduceJava8(sc);
}
public static void reduceJava(JavaSparkContext sc){
JavaRDD<Long>textData = sc.textFile("./avg").map(new Function<String, Long>() {
@Override
public Long call(String s) throws Exception {
return Long.parseLong(s);
};
});
System.out.println(
textData.reduce(new Function2<Long, Long, Long>() {
@Override
public Long call(Long aLong, Long aLong2) throws Exception {
System.out.println("x:"+aLong);
System.out.println("y:"+aLong2);
return aLong+aLong2;
}
})/textData.count()
);
}
public static void reduceJava8(JavaSparkContext sc){
JavaRDD<Long>textData = sc.textFile("./avg").map(s->Long.parseLong(s));
System.out.println(textData.reduce((x,y)->x+y)/textData.count());
}
}
reduce求平均值python实现
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("SparkReduce")
sc = SparkContext(conf=conf)
numData = sc.textFile("./avg").map(lambda s:int(s))
print(numData.reduce(lambda x,y:x+y)/numData.count())
运行结果
观察运行结果,我们不难发现,x存放的是累加后的值,y是当前值,x初始为0。事实上,x正是存放上次处理的结果,而y则是本次的数值。不断做x+y就并且放回累加后的结果作为下一次x的值。这样就可以得 到数值总和。最后将总和除以总数就能够得到平均值。
scala或java运行结果
平均值只保留了整数
x:222783
y:48364
x:271147
y:204950
x:476097
y:261777
x:737874
y:166827
x:904701
y:154005
x:1058706
y:150029
x:1208735
y:140158
x:1348893
y:404846
x:1753739
y:542750
...
...
平均值是:334521
python运行结果
python默认保留了小数
334521.2714
spark的reduceByKey
spark的reduceByKey对要处理的值进行了差别对待,只有key相同的才能进行reduceByKey,则也就要求了进行reduceByKey时,输入的数据必须满足有键有值。由于上述的avg我们是用随机数生成的,那么我们可以用reduceByKey完成一个其他功能,即统计随机数中末尾是0-9各个数值出现的个数。
scala实现
import org.apache.spark.{SparkConf, SparkContext}
object SparkReduceByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SparkReduce")
val sc = new SparkContext(conf)
//将String转成Long类型
val numData = sc.textFile("./avg").map(num => (num.toLong%10,1))
numData.reduceByKey((x,y)=>x+y).foreach(println(_))
}
}
java实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
public class SparkReduceByKeyJava {
public static void main(String[] main){
SparkConf conf = new SparkConf().setAppName("SparkReduceJava").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
reduceByKeyJava(sc);
reduceByKeyJava8(sc);
}
public static void reduceByKeyJava(JavaSparkContext sc){
JavaPairRDD<Integer,Integer> numData = sc.textFile("./avg").mapToPair(new PairFunction<String, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(String s) throws Exception {
return new Tuple2<Integer, Integer>(Integer.parseInt(s)%10,1);
}
});
System.out.println(numData.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer+integer2;
}
}).collectAsMap());
}
public static void reduceByKeyJava8(JavaSparkContext sc){
JavaPairRDD<Integer,Integer> numData = sc.textFile("./avg").mapToPair(s->new Tuple2<>(Integer.parseInt(s)%10,1));
System.out.println(numData.reduceByKey((x,y)->x+y).collectAsMap());
}
}
python实现
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("SparkReduce")
sc = SparkContext(conf=conf)
print(sc.textFile("./avg").map(lambda s:(int(s)%10,1)).reduceByKey(lambda x,y:x+y).collectAsMap())
运行结果
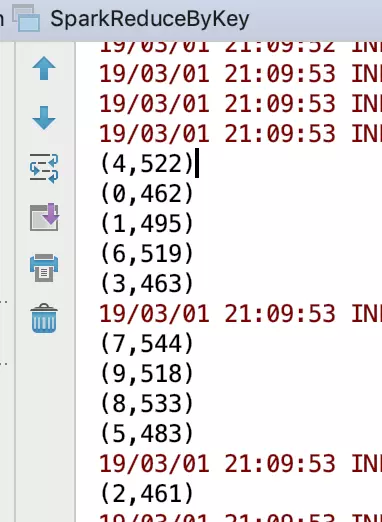
scala运行结果
(4,522)
(0,462)
(1,495)
(6,519)
(3,463)
(7,544)
(9,518)
(8,533)
(5,483)
(2,461)
java运行结果
{8=533, 2=461, 5=483, 4=522, 7=544, 1=495, 9=518, 3=463, 6=519, 0=462}

python运行结果
{3: 463, 4: 522, 0: 462, 7: 544, 5: 483, 9: 518, 8: 533, 6: 519, 2: 461, 1: 495}

我们注意到三个程序输出的顺序不一样,但是本质的结果都是一致的。这里体现了spark的一个优点,由于是在单机本地上,该优点表现出来的是相同输入输出结果顺序不同。但是在集群中,该优点表现出来的是在集群中各自处理,而后返回结果。当数量足够大的时候,这个优点就更加明显。
对结果进行排序
那么为了能够使得输出结果顺序一致,我们可以对数据进行排序后输出,那么这里就涉及到了sortByKey。
scala实现
import org.apache.spark.{SparkConf, SparkContext}
object SparkReduceByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SparkReduce")
val sc = new SparkContext(conf)
//将String转成Long类型
val numData = sc.textFile("./avg").map(num => (num.toLong%10,1))
//根据key排序后输出
numData.reduceByKey((x,y)=>x+y).sortByKey().foreach(println(_))
}
}
java实现
特别注意这里用的是collect,而不是collectMap,因为java中转换成Map会打乱顺序
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
public class SparkReduceByKeyJava {
public static void main(String[] main){
SparkConf conf = new SparkConf().setAppName("SparkReduceJava").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
reduceByKeyJava(sc);
reduceByKeyJava8(sc);
}
public static void reduceByKeyJava(JavaSparkContext sc){
JavaPairRDD<Integer,Integer> numData = sc.textFile("./avg").mapToPair(new PairFunction<String, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(String s) throws Exception {
return new Tuple2<Integer, Integer>(Integer.parseInt(s)%10,1);
}
});
System.out.println(numData.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer+integer2;
}
}).sortByKey().collect());
}
public static void reduceByKeyJava8(JavaSparkContext sc){
JavaPairRDD<Integer,Integer> numData = sc.textFile("./avg").mapToPair(s->new Tuple2<>(Integer.parseInt(s)%10,1));
System.out.println(numData.reduceByKey((x,y)->x+y).sortByKey().collect());
}
}
python实现
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("SparkReduce")
sc = SparkContext(conf=conf)
print(sc.textFile("./avg").map(lambda s:(int(s)%10,1)).reduceByKey(lambda x,y:x+y).sortByKey().collectAsMap())
得到结果,这里只给出scala输出的结果,其他输出的结果一致,只是表现形式不同
(0,462)
(1,495)
(2,461)
(3,463)
(4,522)
(5,483)
(6,519)
(7,544)
(8,533)
(9,518)
数据集以及代码都可以在github上下载。
转自:https://juejin.im/post/5c791d4fe51d453ed866248a
Spark入门(五)--Spark的reduce和reduceByKey的更多相关文章
- 二、spark入门之spark shell:文本中发现5个最常用的word
scala> val textFile = sc.textFile("/Users/admin/spark-1.5.1-bin-hadoop2.4/README.md") s ...
- 一、spark入门之spark shell:wordcount
1.安装完spark,进入spark中bin目录: bin/spark-shell scala> val textFile = sc.textFile("/Users/admin/ ...
- spark实验(五)--Spark SQL 编程初级实践(1)
一.实验目的 (1)通过实验掌握 Spark SQL 的基本编程方法: (2)熟悉 RDD 到 DataFrame 的转化方法: (3)熟悉利用 Spark SQL 管理来自不同数据源的数据. 二.实 ...
- Spark入门:Spark运行架构(Python版)
此文为个人学习笔记如需系统学习请访问http://dblab.xmu.edu.cn/blog/1709-2/ 基本概念 * RDD:是弹性分布式数据集(Resilient Distributed ...
- Spark 入门
Spark 入门 目录 一. 1. 2. 3. 二. 三. 1. 2. 3. (1) (2) (3) 4. 5. 四. 1. 2. 3. 4. 5. 五. Spark Shell使用 ...
- Spark入门(六)--Spark的combineByKey、sortBykey
spark的combineByKey combineByKey的特点 combineByKey的强大之处,在于提供了三个函数操作来操作一个函数.第一个函数,是对元数据处理,从而获得一个键值对.第二个函 ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
随机推荐
- [LC] 48. Rotate Image
You are given an n x n 2D matrix representing an image. Rotate the image by 90 degrees (clockwise). ...
- Java子类和父类的初始化执行顺序
要明白子类和父类的初始化执行顺序,只需要知晓以下三点,就不会再弄错了. 1.创建子类对象时,子类和父类的静态块和构造方法的执行顺序为:父类静态块->子类静态块->父类构造器->子类构 ...
- sqlserver开窗函数改造样例
作一个查询的性能优化. 先清缓存 DBCC DROPCLEANBUFFERS DBCC FREEPROCCACHE 原查询 前人遗留. ) ),) select @total=sum(price*pe ...
- jtemplates使用+同内容列合并
function ImportStatistics(val, pros) { top.$.jBox.tip("导入已完成,正在统计整理导入的数据...", 'loading'); ...
- Java IO: RandomAccessFile
原文链接 作者: Jakob Jenkov 译者: 李璟(jlee381344197@gmail.com) RandomAccessFile允许你来回读写文件,也可以替换文件中的某些部分.FileIn ...
- docker实践-安装wordpress
很多人都有搭建wordpress的经历,可能被某些环境的配置搞得焦头乱耳的,这里使用docker,可以很轻松的进行wordpress的搭建工作. 安装 Docker sudo apt-get inst ...
- SimpleTrigger的使用
SimpleTrigger的作用 在一个指定时间段内执行一次作业任务或是在指定的时间间隔内多次执行作业任务 使用实例1:距离当前时间4s钟后执行,且执行一次 package com.test.quar ...
- Ubuntu18.04安装OpenStack
Ubuntu18.04 安装Queens版本OpenStack 安装环境 系统 系统使用的是Ubuntu18,最少4核8G内存,20G硬盘空间. 工具 devstack DevStack是一系列可扩展 ...
- Android APP性能及专项测试
移动测试. Android测试 .APP测试 Android篇 1. 性能测试 Android性能测试分为两类:1.一类为rom版本(系统)的性能测试2.一类为应用app的性能测试 Android的a ...
- 一个异步访问redis的内存问题
| 分类 redis | 遇到一个redis实例突然内存飙高的案例, 具体症状如下: 客户端使用异步访问模式 单个请求的回包很大,hgetall一个8M的key 由于访问量比较大,已经登录不上red ...