写Java也得了解CPU--CPU缓存
CPU,一般认为写C/C++的才需要了解,写高级语言的(Java/C#/pathon...)并不需要了解那么底层的东西。我一开始也是这么想的,但直到碰到LMAX的Disruptor,以及马丁的博文,才发现写Java的,更加不能忽视CPU。经过一段时间的阅读,希望总结一下自己的阅读后的感悟。本文主要谈谈CPU缓存对Java编程的影响,不涉及具体CPU缓存的机制和实现。
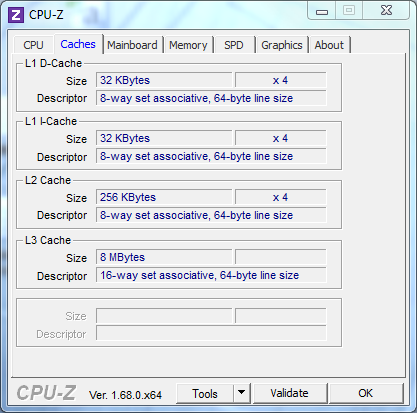
现代CPU的缓存结构一般分三层,L1,L2和L3。如下图所示:

级别越小的缓存,越接近CPU, 意味着速度越快且容量越少。
L1是最接近CPU的,它容量最小,速度最快,每个核上都有一个L1 Cache(准确地说每个核上有两个L1 Cache, 一个存数据 L1d Cache, 一个存指令 L1i Cache);
L2 Cache 更大一些,例如256K,速度要慢一些,一般情况下每个核上都有一个独立的L2 Cache;
L3 Cache是三级缓存中最大的一级,例如12MB,同时也是最慢的一级,在同一个CPU插槽之间的核共享一个L3 Cache。
当CPU运作时,它首先去L1寻找它所需要的数据,然后去L2,然后去L3。如果三级缓存都没找到它需要的数据,则从内存里获取数据。寻找的路径越长,耗时越长。所以如果要非常频繁的获取某些数据,保证这些数据在L1缓存里。这样速度将非常快。下表表示了CPU到各缓存和内存之间的大概速度:
从CPU到 大约需要的CPU周期 大约需要的时间(单位ns)
寄存器 1 cycle
L1 Cache ~3-4 cycles ~0.5-1 ns
L2 Cache ~10-20 cycles ~3-7 ns
L3 Cache ~40-45 cycles ~15 ns
跨槽传输 ~20 ns
内存 ~120-240 cycles ~60-120ns
利用CPU-Z可以查看CPU缓存的信息:
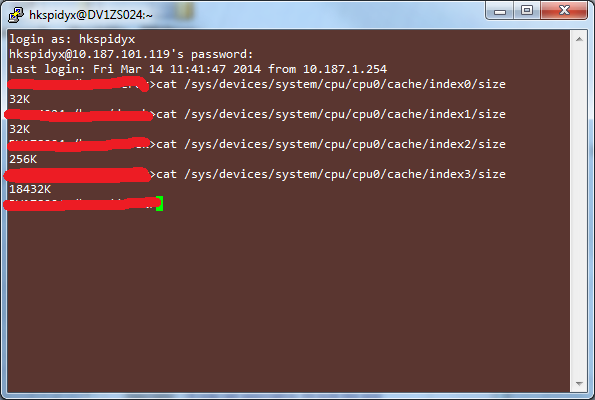
在linux下可以使用下列命令查看:
有了上面对CPU的大概了解,我们来看看缓存行(Cache line)。缓存,是由缓存行组成的。一般一行缓存行有64字节(由上图"64-byte line size"可知)。所以使用缓存时,并不是一个一个字节使用,而是一行缓存行、一行缓存行这样使用;换句话说,CPU存取缓存都是按照一行,为最小单位操作的。
这意味着,如果没有好好利用缓存行的话,程序可能会遇到性能的问题。可看下面的程序:
public class L1CacheMiss {
private static final int RUNS = 10;
private static final int DIMENSION_1 = 1024 * 1024;
private static final int DIMENSION_2 = 6;
private static long[][] longs;
public static void main(String[] args) throws Exception {
Thread.sleep(10000);
longs = new long[DIMENSION_1][];
for (int i = 0; i < DIMENSION_1; i++) {
longs[i] = new long[DIMENSION_2];
for (int j = 0; j < DIMENSION_2; j++) {
longs[i][j] = 0L;
}
}
System.out.println("starting....");
long sum = 0L;
for (int r = 0; r < RUNS; r++) {
final long start = System.nanoTime();
//slow
// for (int j = 0; j < DIMENSION_2; j++) {
// for (int i = 0; i < DIMENSION_1; i++) {
// sum += longs[i][j];
// }
// }
//fast
for (int i = 0; i < DIMENSION_1; i++) {
for (int j = 0; j < DIMENSION_2; j++) {
sum += longs[i][j];
}
}
System.out.println((System.nanoTime() - start));
}
}
}
以我所使用的Xeon E3 CPU和64位操作系统和64位JVM为例,如这里所说,假设编译器采用行主序存储数组。
64位系统,Java数组对象头固定占16字节(未证实),而long类型占8个字节。所以16+8*6=64字节,刚好等于一条缓存行的长度:
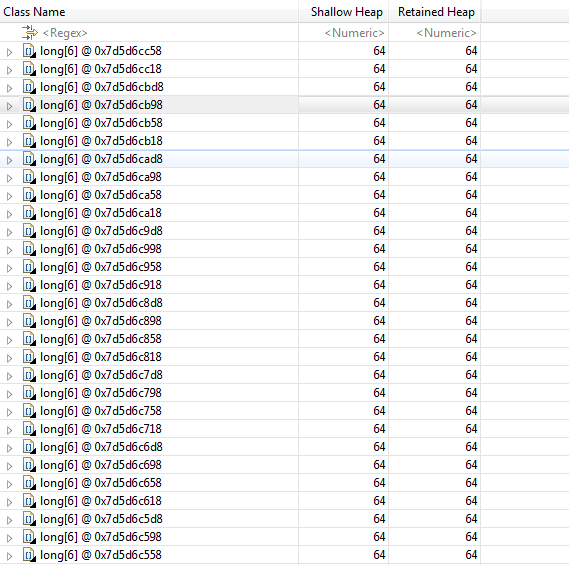
如32-36行代码所示,每次开始内循环时,从内存抓取的数据块实际上覆盖了longs[i][0]到longs[i][5]的全部数据(刚好64字节)。因此,内循环时所有的数据都在L1缓存可以命中,遍历将非常快。
假如,将32-36行代码注释而用25-29行代码代替,那么将会造成大量的缓存失效。因为每次从内存抓取的都是同行不同列的数据块(如longs[i][0]到longs[i][5]的全部数据),但循环下一个的目标,却是同列不同行(如longs[0][0]下一个是longs[1][0],造成了longs[0][1]-longs[0][5]无法重复利用)。运行时间的差距如下图,单位是微秒(us):
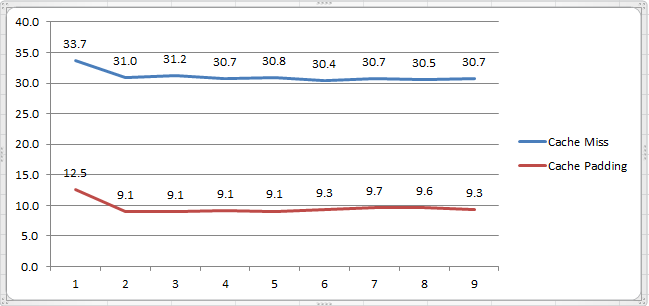
最后,我们都希望需要的数据都在L1缓存里,但事实上经常事与愿违,所以缓存失效 (Cache Miss)是常有的事,也是我们需要避免的事。
一般来说,缓存失效有三种情况:
1. 第一次访问数据, 在cache中根本不存在这条数据, 所以cache miss, 可以通过prefetch解决。
2. cache冲突, 需要通过补齐来解决(伪共享的产生)。
3. cache满, 一般情况下我们需要减少操作的数据大小, 尽量按数据的物理顺序访问数据。
参考:
http://mechanitis.blogspot.hk/2011/07/dissecting-disruptor-why-its-so-fast_22.html
http://coderplay.iteye.com/blog/1485760
http://en.wikipedia.org/wiki/CPU_cache
写Java也得了解CPU--CPU缓存的更多相关文章
- 写Java也得了解CPU–CPU缓存
CPU,一般认为写C/C++的才需要了解,写高级语言的(Java/C#/pathon…)并不需要了解那么底层的东西.我一开始也是这么想的,但直到碰到LMAX的Disruptor,以及马丁的博文,才发现 ...
- 聊聊高并发(三十四)Java内存模型那些事(二)理解CPU快速缓存的工作原理
在上一篇聊聊高并发(三十三)从一致性(Consistency)的角度理解Java内存模型 我们说了Java内存模型是一个语言级别的内存模型抽象.它屏蔽了底层硬件实现内存一致性需求的差异,提供了对上层的 ...
- Java高并发--CPU多级缓存与Java内存模型
Java高并发--CPU多级缓存与Java内存模型 主要是学习慕课网实战视频<Java并发编程入门与高并发面试>的笔记 CPU多级缓存 为什么需要CPU缓存:CPU的频率太快,以至于主存跟 ...
- Java内存模型(二)volatile底层实现(CPU的缓存一致性协议MESI)
CPU的缓存一致性协议MESI 在多核CPU中,内存中的数据会在多个核心中存在数据副本,某一个核心发生修改操作,就产生了数据不一致的问题,而一致性协议正是用于保证多个CPU cache之间缓存共享数据 ...
- 并发编程二、CPU多级缓存架构与MESI协议的诞生
前言: 文章内容:线程与进程.线程生命周期.线程中断.线程常见问题总结 本文章内容来源于笔者学习笔记,内容可能与相关书籍内容重合 偏向于知识核心总结,非零基础学习文章,可用于知识的体系建立,核心内容 ...
- Java Performance - 如何调查解决 CPU 问题
随着硬件的发展,往往服务器会配置足够的 CPUs, Java Server/服务器不太有 CPU 问题:但是偶尔因为 代码海量循环 或者 线程安全性(thread safe), 还是会带来 CPU 问 ...
- 浅谈CPU三级缓存和缓存命中率
CPU: CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多.缓存的出现主要是 为了解决CPU运算速度与内存读写速度不匹配的矛盾 ...
- java 7中新增的CPU和负载的监控
java 7中新增的CPU和负载的监控 import java.lang.management.ManagementFactory; import java.lang.management.Opera ...
- [转帖]CPU 的缓存
缓存这个词想必大家都听过,其实缓存的意义很广泛:电脑整机最大的缓存可以体现为内存条.显卡上的显存就是显卡芯片所需要用到的缓存.硬盘上也有相对应的缓存.CPU有着最快的缓存(L1.L2.L3缓存等),缓 ...
随机推荐
- git diff的用法
在git提交环节,存在三大部分:working tree(工作区), index file(暂存区:stage), commit(分支:master) working tree:就是你所工作在的目录, ...
- Hibernate 缓存介绍
Hibernate中提供了两级缓存,一级缓存是Session级别的缓存,它属于事务范围的缓存,该级缓存由hibernate管理,应用程序无需干预:二级缓存是SessionFactory级别的缓存,该级 ...
- git merge git pull时候遇到冲突解决办法git stash
在使用git pull代码时,经常会碰到有冲突的情况,提示如下信息: error: Your local changes to 'c/environ.c' would be overwritten b ...
- hibernate连接数据库和反向工程
一.JSP界面连接数据库: 导包:将11个包倒进web-inf的lib目录下: 二.建立hibernate.cfg.xml的配置文件:!注意:是放到项目SRC目录下: 三.将视图切换到java下,在左 ...
- JS代码判断字符串中有多少汉字
$("form").submit(function () { var content = editor.getContentTxt(); var sum = 0; re = /[\ ...
- Rollback 语句 在08R2版本
有时候为了数据完整我们会启用到事务.正常的时候一帆风顺,如果rollback 呢? 最简单的一个回滚 IF OBJECT_ID('PROC1') IS NOT NULL DROP PROCED ...
- Redis基本配置
# redis 配置文件示例 # 当你需要为某个配置项指定内存大小的时候,必须要带上单位, # 通常的格式就是 1k 5gb 4m 等酱紫: # # 1k => 1000 bytes # 1kb ...
- x01.os.8: 加载内核
在 x01.os.7 中,借助 freedos,学习了保护模式.但操作系统必须完成引导:boot, 加载内核:loader,kernel,进而管理process,memory,file等. 引导比较简 ...
- linux 添加用户、权限
# useradd –d /usr/sam -m sam 此命令创建了一个用户sam,其中-d和-m选项用来为登录名sam产生一个主目录/usr/sam(/usr为默认的用户主目录所在的父目录). 假 ...
- java对redis的基本操作
一.server端安装 1.下载 https://github.com/MSOpenTech/redis 可看到当前可下载版本:redis2.6