高性能MySQL笔记 第5章 创建高性能的索引
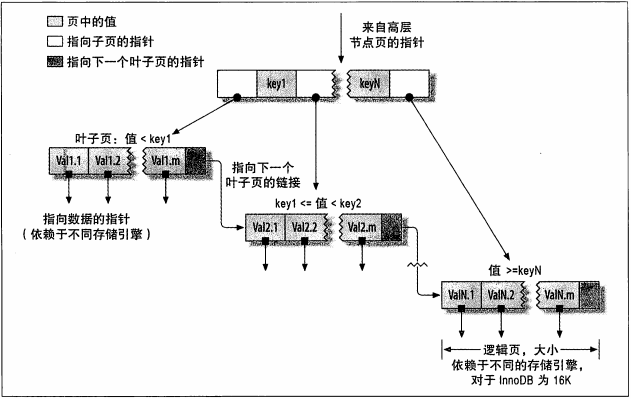
.png) 索引(index),在MySQL中也被叫做键(key),是存储引擎用于快速找到记录的一种数据结构。索引优化是对查询性能优化最有效的手段。
索引(index),在MySQL中也被叫做键(key),是存储引擎用于快速找到记录的一种数据结构。索引优化是对查询性能优化最有效的手段。- 全值匹配:是指和索引中的所有列进行匹配。
- 匹配最左前缀:即只使用索引的第一列。
- 匹配列前缀:即只使用索引第一列的开头部分。
- 匹配范围值:只使用了索引的第一列。
- 精确匹配某个列并范围匹配另外一列:即索引第一列全匹配,第二列范围匹配。
- 只访问索引的查询:又被称为“覆盖索引”,B-tree通常支持“只访问索引的查询”,即查询只需要访问索引,而无须访问数据行。如用户名与密码的匹配,手机号与验证码的匹配。
- 如果不是按照索引的最左列开始查找,则无法使用索引。
- 不能跳过索引中的列。
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引。
- 索引大大减少了服务器需要扫描的数据量;
- 索引可以帮助服务器避免排序和临时表;
- 索引可以将随机I/O变为顺序I/O;
- 索引相关记录放在一起则获得一星;
- 索引中的数据顺序和查找中的排序顺序一致则获得二星;
- 索引中的列包含了查询中需要的全部列则获取三星;
- 当出现服务器对多个索引做相交操作时(通常有多个and条件),通常意味着需要一个包含所有香港列的多列索引,而不是多个独立的单列索引。
- 当服务器需要对多个索引做联合操作时(通常有多个or条件),通常需要消耗大量CPU和内存资源在算法的缓存、排序和合并操作上。特别是当其中有些索引的选择性不高,需要合并扫描返回的大量数据的时候。
- 更重要的是,优化器不会把这些计算到“查询成本”(cost)中,优化器只关心随机页面读取。这会使得查询的成本被“低估”,还可能会影响查询的并发性,但如果是单独运行这样的查询则往往会忽略对并发性的影响。
.png)
- 可以把相关数据保存在一起。
- 数据访问更快。聚簇索引将索引和数据保存在同一个B-Tree中,因此从聚簇索引中获取数据通常比在非聚簇索引中查找要快。
- 使用覆盖索引扫描的查询可以直接使用叶节点的主键值。
- 聚簇数据最大限度地提高了IO密集型应用的性能。但如果数据全部都放在内存中,则访问的顺序就没那么重要了,聚簇索引也就没了优势。
- 插入速度严重依赖插入顺序,按照主键的顺序是加载数据到InnoDB表中速度最快的方式。但如果不是按照主键顺序加载数据,那么在加载完成后最好使用optimize table命令重新组织一下表。
- 更新聚簇索引列的代价很高,因为会强制InnoDB将每个被更新的行移动到新的位置。
- 基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临“页分裂”(page split)的问题。当行的主键值要求必须将这一行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这就是一次页分裂操作。页分裂会导致表占用更多的磁盘空间。
- 聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候。
- 二级索引(非聚簇索引)可能比想象的要更大,因为在二级索引的叶子节点包含了引用行的主键列。
- 二次索引访问需要两次索引查找,而不是一次。这是因为二级索引中保存的“行指针”的实质。二级索引叶子节点保存的不是指向行的物理位置的指针,而是行的主键值。通过二级索引查找行,存储引擎需要找到二级索引的叶子节点获得对应的主键值,然后根据这个值取聚簇索引中查找到对应的行。
- 索引条目通常远小于数据行大小,所以如果只需要读取索引,那MySQL就会极大地减少数据访问量。这对缓存的负载非常重要,因为这种情况下响应时间大部分花费在数据拷贝上。覆盖索引对于IO密集型的应用也有帮助,因为索引比数据更小,更容易全部放入内存中。
- 因为索引是按照列值顺序存储的(至少在单个数据页内是如此)所以对于IO密集型的范围查询会比随机从磁盘读取每一行数据的IO要少得多。
- 由于InnoDB的聚簇索引,覆盖索引对InnoDB表特别有用。InnoDB的二级索引在叶子节点中保存了行的主键值,所以如果二级索引能够覆盖查询,则可以比main对主键索引的二次查询。
| 排序 | 是否使用了索引扫描来做排序 |
| ORDER BY a | yes |
| ORDER BY a, b | yes |
| ORDER BY a, b desc | no |
| WHERE a = 1 ORDER BY b | yes |
| WHERE a > 1 ORDER BY a, b | yes |
| WHERE a =1 ORDER BY b, c | no |
| WHERE a > 1 ORDER BY b | no |
- 单行访问是很慢的。特别是在机械硬盘存储中(SSD固态硬盘的随意IO要快很多,不过这一点仍然适用)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引用以提升效率。
- 按顺序访问范围数据是很快的,这有两个原因。第一,顺序IO不需要多次磁盘寻道,所以比随机IO要快很多。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUP BY 查询也无须再做排序和将行按组进行聚合计算了。
- 索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就不需要再回表查找行。这避免了大量的单行访问。
高性能MySQL笔记 第5章 创建高性能的索引的更多相关文章
- 《高性能MySQL》——第五章创建高性能索引
1.创建索引基本语法格 在MySQL中,在已经存在的表上,可以通过ALTER TABLE语句直接为表上的一个或几个字段创建索引.基本语法格式如下: ALTER TABLE 表名 ADD [UNIQUE ...
- 高性能MySQL笔记 第6章 查询性能优化
6.1 为什么查询速度会慢 查询的生命周期大致可按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端.其中“执行”可以认为是整个生命周期中最重要的阶段. ...
- 高性能MySQL笔记 第4章 Schema与数据类型优化
4.1 选择优化的数据类型 通用原则 更小的通常更好 前提是要确保没有低估需要存储的值范围:因为它占用更少的磁盘.内存.CPU缓存,并且处理时需要的CPU周期也更少. 简单就好 简 ...
- 高性能MySQL笔记-第1章MySQL Architecture and History-001
1.MySQL架构图 2.事务的隔离性 事务的隔离性是specific rules for which changes are and aren’t visible inside and outsid ...
- 高性能MySQL笔记-第5章Indexing for High Performance-004怎样用索引才高效
一.怎样用索引才高效 1.隔离索引列 MySQL generally can’t use indexes on columns unless the columns are isolated in t ...
- 高性能MySQL笔记-第5章Indexing for High Performance-002Hash indexes
一. 1.什么是hash index A hash index is built on a hash table and is useful only for exact lookups that u ...
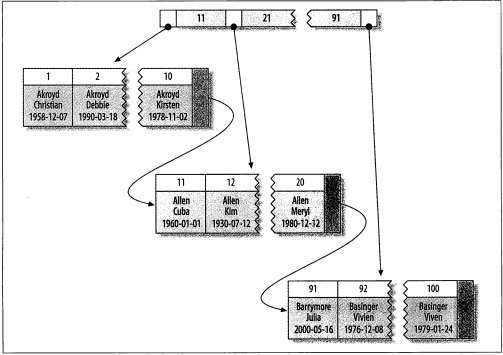
- 高性能MySQL笔记-第5章Indexing for High Performance-001B-Tree indexes(B+Tree)
一. 1.什么是B-Tree indexes? The general idea of a B-Tree is that all the values are stored in order, and ...
- 高性能MySQL笔记-第4章Optimizing Schema and Data Types
1.Good schema design is pretty universal, but of course MySQL has special implementation details to ...
- 高性能MySQL笔记-第5章Indexing for High Performance-005聚集索引
一.聚集索引介绍 1.什么是聚集索引? InnoDB’s clustered indexes actually store a B-Tree index and the rows together i ...
随机推荐
- ahjesus 前端缓存原理 转载
LAMP缓存图 从图中我们可以看到网站缓存主要分为五部分 服务器缓存:主要是基于web反向代理的静态服务器nginx和squid,还有apache2的mod_proxy和mod_cache模 浏览器缓 ...
- 使用loadrunner进行压力测试之----post请求
1. 发送post请求时使用web_submit_data 如: web_submit_data("create",//事务名 "Action=http://bizhi. ...
- Linux学习笔记17--Linux系统启动详解
多数操作系统的启动流程: BIOS启动自检 ->MBR引导->执行引导程序GRUB->加载内核->执行init->runlevel BIOS(Basic Input ...
- ContentTools – 所见即所得(WYSIWYG)编辑器
Content Tools是一个用于构建所见即所得编辑器(WYSIWYG)的 JavaScript 库.ContentTools 所见即所得的编辑器只需要几个简单的步骤就可以加入到任何的 HTML 页 ...
- 20款时尚的 WordPress 简洁主题【免费下载】
在这篇文章中,我们收集了20款时尚的 WordPress 简洁模板.WordPress 是最流行的博客系统,插件众多,易于扩充功能.安装和使用都非常方便,而且有许多第三方开发的免费模板,安装方式简单易 ...
- IOS 局域网发送信息
基于ios 例子WiTap 1.创建本地的服务并设置监听时间检测是否有设备连接. NSNetService * server = [[NSNetService alloc] initWithDomai ...
- javascript中数组的常用方法
数组的基本方法如下 1.concat() 2.join() 3.pop() 4.push() 5.reverse() 6.shift() 7.sort() 8.splice() 9.toString( ...
- Vue.js——60分钟快速入门
Vue.js介绍 Vue.js是当下很火的一个JavaScript MVVM库,它是以数据驱动和组件化的思想构建的.相比于Angular.js,Vue.js提供了更加简洁.更易于理解的API,使得我们 ...
- 汉王云名片识别(SM)组件开发详解
大家好,最近在DeviceOne平台上做了一个汉王云名片识别的功能组件.下面把我开发过程给大家做一个分享,希望可以帮助到大家. 下面我把我的思路给大家讲解一下. 1.找到我要集成的sdk,也就是汉 ...
- JS与一般处理程序之间传值乱码
好久没用到,突然遇到此问题还用了点时间. 在JS里面通过URL向Handler传中文值的时候,在Handler里面取值出来后会发现是乱码的~~.这就需要个编码解码过程.(先记录自己遇到的一个方面的解决 ...