通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制
本期内容:
1. Spark Streaming架构
2. Spark Streaming运行机制
Spark大数据分析框架的核心部件: spark Core、spark Streaming流计算、GraphX图计算、MLlib机器学习、Spark SQL、Tachyon文件系统、SparkR计算引擎等主要部件.

Spark Streaming 其实是构建在spark core之上的一个应用程序,要构建一个强大的Spark应用程序 ,spark Streaming是一个值得借鉴的参考,spark Streaming涉及多个job交叉配合,基本涉及到了spark的所有的核心组件,精通掌握spark streaming是至关重要的。
Spark Streaming基础概念理解:
1. 离散流:(Discretized Stream ,DStream):这是spark streaming对内部的持续的实时数据流的抽象描述,也即我们处理的一个实时数据流,在spark streaming中对应一个DStream ;
2. 批数据:将实时流时间以时间为单位进行分批,将数据处理转化为时间片数据的批处理;
3. 时间片或者批处理时间间隔:逻辑级别的对数据进行定量的标准,以时间片作为拆分流数据的依据;
4. 窗口长度:一个窗口覆盖的流数据的时间长度。比如说要每隔5分钟统计过去30分钟的数据,窗口长度为6,因为30分钟是batch interval 的6倍;
5. 滑动时间间隔:比如说要每隔5分钟统计过去30分钟的数据,窗口时间间隔为5分钟;
6. input DStream :一个inputDStream是一个特殊的DStream 将spark streaming连接到一个外部数据源来读取数据。
7. Receiver :长时间(可能7*24小时)运行在Excutor之上,每个Receiver负责一个inuptDStream (比如读取一个kafka消息的输入流)。每个Receiver,加上inputDStream 会占用一个core/slot ;
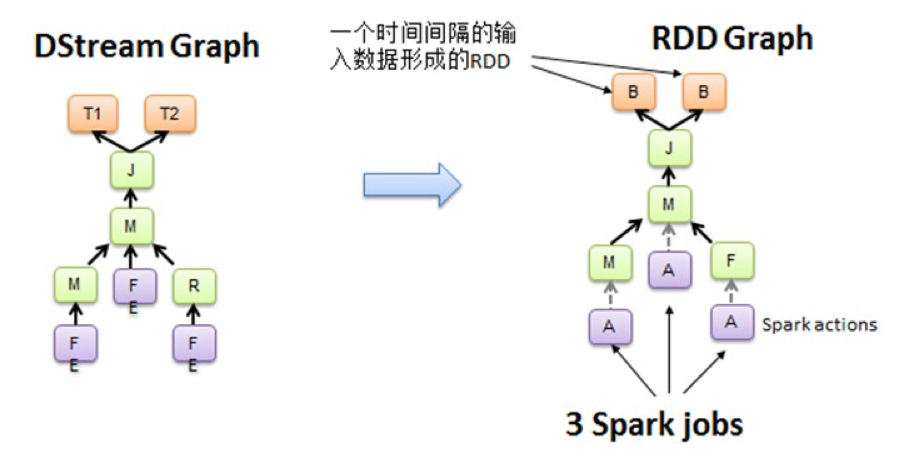
Spark Core处理的每一步都是基于RDD的,RDD之间有依赖关系。下图中的RDD的DAG显示的是有3个Action,会触发3个job,RDD自下向上依赖,RDD产生job就会具体的执行。从DSteam Graph中可以看到,DStream的逻辑与RDD基本一致,它就是在RDD的基础上加上了时间的依赖。RDD的DAG又可以叫空间维度,也就是说整个Spark Streaming多了一个时间维度,也可以成为时空维度。
从这个角度来讲,可以将Spark Streaming放在坐标系中。其中Y轴就是对RDD的操作,RDD的依赖关系构成了整个job的逻辑,而X轴就是时间。随着时间的流逝,固定的时间间隔(Batch Interval)就会生成一个job实例,进而在集群中运行。

对于Spark Streaming来说,当不同的数据来源的数据流进来的时候,基于固定的时间间隔,会形成一系列固定不变的数据集或event集合(例如来自flume和kafka)。而这正好与RDD基于固定的数据集不谋而合,事实上,由DStream基于固定的时间间隔行程的RDD Graph正是基于某一个batch的数据集的。
从上图中可以看出,在每一个Batch上,空间维度的RDD依赖关系都是一样的,不同的是这个五个Batch流入的数据规模和内容不一样,所以说生成的是不同的RDD依赖关系的实例,所以说RDD的Graph脱胎于DStream的Graph,也就是说DStream就是RDD的模板,不同的时间间隔,生成不同的RDD Graph实例。
从源码解读DStream :

从这里可以看出,DStream就是Spark Streaming的核心,就想Spark Core的核心是RDD,它也有dependency和compute。更为关键的是下面的代码:

这是一个HashMap,以时间为key,以RDD为Value,这也正应证了随着时间流逝,不断的生成RDD,产生依赖关系的job,并通过JbScheduler在集群上运行。再次验证了DStream就是RDD的模版。
DStream可以说是逻辑级别的,RDD就是物理级别的,DStream所表达的最终都是通过RDD的转化实现的。前者是更高级别的抽象,后者是底层的实现。DStream实际上就是在时间维度上对RDD集合的封装,DStream与RDD的关系就是随着时间流逝不断的产生RDD,对DStream的操作就是在固定时间上操作RDD。
总结:
在空间维度上的业务逻辑作用于DStream,随着时间的流逝,每个Batch Interval形成了具体的数据集,产生了RDD,对RDD进行Transform操作,进而形成了RDD的依赖关系RDD DAG,形成Job。然后JobScheduler根据时间调度,基于RDD的依赖关系,把作业发布到Spark Cluster上去运行,不断的产生Spark作业。
通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制的更多相关文章
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 通过案例对SparkStreaming透彻理解三板斧之二
本节课主要从以下二个方面来解密SparkStreaming: 一.解密SparkStreaming运行机制 二.解密SparkStreaming架构 SparkStreaming运行时更像SparkC ...
- 通过案例对SparkStreaming透彻理解三板斧之一
本节课通过二个部分阐述SparkStreaming的理解: 一.解密SparkStreaming另类在线实验 二.瞬间理解SparkStreaming本质 Spark源码定制班主要是自己做发行版.自己 ...
- 通过案例对SparkStreaming透彻理解三板斧之三
本课将从二方面阐述: 一.解密SparkStreaming Job架构和运行机制 二.解密SparkStreaming容错架构和运行机制 一切不能进行实时流处理的数据都将是无效的数据.在流处理时代,S ...
- spark 源码分析之十二 -- Spark内置RPC机制剖析之八Spark RPC总结
在spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv中,剖析了NettyRpcEnv的创建过程. Dispatcher.NettyStreamManager.T ...
- Spark大数据处理 之 从WordCount看Spark大数据处理的核心机制(1)
大数据处理肯定是分布式的了,那就面临着几个核心问题:可扩展性,负载均衡,容错处理.Spark是如何处理这些问题的呢?接着上一篇的"动手写WordCount",今天要做的就是透过这个 ...
- spark 源码分析之十八 -- Spark存储体系剖析
本篇文章主要剖析BlockManager相关的类以及总结Spark底层存储体系. 总述 先看 BlockManager相关类之间的关系如下: 我们从NettyRpcEnv 开始,做一下简单说明. Ne ...
- JavaWeb三大组件——过滤器的运行机制理解
过滤器Filter 文章前言:本文侧重实用和理解. 一.过滤器的概念. lFilter也称之为过滤器,它是Servlet技术中最实用的技术,WEB开发人员通过Filter技术,对web服务器管理的所有 ...
随机推荐
- matplotlib画图保存
import numpy as np import matplotlib.pyplot as plt xData = np.arange(0, 10, 1) yData1 = xData.__pow_ ...
- C++ Daily《2》----vector容器的resize 与 reserve的区别
C++ STL 库中 vector 容器的 resize 和 reserve 区别是什么? 1. resize 改变 size 大小,而 reserve 改变 capacity, 不改变size. 2 ...
- Poisson Distribution——泊松分布
老师留个小作业,用EXCEL做不同lambda(np)的泊松分布图,这里分别用EXCEL,Python,MATLAB和R简单画一下. 1. EXCEL 运用EXCEL统计学公式,POISSON,算出各 ...
- C++学习笔记24:makefile文件
makefile make命令:负责c/c++程序编译与链接 make根据指定命令进行建构 建构规则文件:GNUmakefile , makefile,Makefile makefile 文件格式 m ...
- SAP HR宏 rp-provide-from-last
运行se11 Database table: 输入 TRMAC 点击display 查看其内容:第14个按钮(ctrl + shift +F10) 再Name 输入:rp-provide-from-l ...
- windows 下的定时任务
linux 下的定时任务是crontab 以前都是linux的定时任务,这次在windows做了定时任务,简单记录一下 windows 2008下的定时任务配置: 控制面板->管理工具-> ...
- http和htpps
http(超文本传输协议)是一个基于请求与响应模式的.无状态的.应用层的协议. HTTPS 基于安全套接字层的超文本传输协议 或者是 HTTP over SSL **HTTP 和 HTTPS相同 ...
- mm/swap
/* * linux/mm/swap.c * * Copyright (C) 1991, 1992 Linus Torvalds */ /* * This file should contain ...
- rabin 素性检验 随机化算法
#include <cstdio> #include <cstdlib> #include <ctime> typedef long long int LL; in ...
- jQuery-2.1.4.min.js:4 Uncaught TypeError: Illegal invocation
jQuery-2.1.4.min.js:4 Uncaught TypeError: Illegal invocation 此错误与crsf有关