【转】如何确定Kafka的分区数、key和consumer线程数
def partition(key: Any, numPartitions: Int): Int = {
Utils.abs(key.hashCode) % numPartitions
}
这就保证了相同key的消息一定会被路由到相同的分区。如果你没有指定key,那么Kafka是如何确定这条消息去往哪个分区的呢?

if(key == null) { // 如果没有指定key
val id = sendPartitionPerTopicCache.get(topic) // 先看看Kafka有没有缓存的现成的分区Id
id match {
case Some(partitionId) =>
partitionId // 如果有的话直接使用这个分区Id就好了
case None => // 如果没有的话,
val availablePartitions = topicPartitionList.filter(_.leaderBrokerIdOpt.isDefined) //找出所有可用分区的leader所在的broker
if (availablePartitions.isEmpty)
throw new LeaderNotAvailableException("No leader for any partition in topic " + topic)
val index = Utils.abs(Random.nextInt) % availablePartitions.size // 从中随机挑一个
val partitionId = availablePartitions(index).partitionId
sendPartitionPerTopicCache.put(topic, partitionId) // 更新缓存以备下一次直接使用
partitionId
}
}
可以看出,Kafka几乎就是随机找一个分区发送无key的消息,然后把这个分区号加入到缓存中以备后面直接使用——当然了,Kafka本身也会清空该缓存(默认每10分钟或每次请求topic元数据时)
val nPartsPerConsumer = curPartitions.size / curConsumers.size // 每个consumer至少保证消费的分区数
val nConsumersWithExtraPart = curPartitions.size % curConsumers.size // 还剩下多少个分区需要单独分配给开头的线程们
...
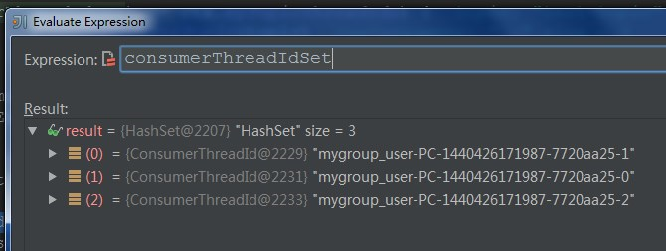
for (consumerThreadId <- consumerThreadIdSet) { // 对于每一个consumer线程
val myConsumerPosition = curConsumers.indexOf(consumerThreadId) //算出该线程在所有线程中的位置,介于[0, n-1]
assert(myConsumerPosition >= 0)
// startPart 就是这个线程要消费的起始分区数
val startPart = nPartsPerConsumer * myConsumerPosition + myConsumerPosition.min(nConsumersWithExtraPart)
// nParts 就是这个线程总共要消费多少个分区
val nParts = nPartsPerConsumer + (if (myConsumerPosition + 1 > nConsumersWithExtraPart) 0 else 1)
...
}
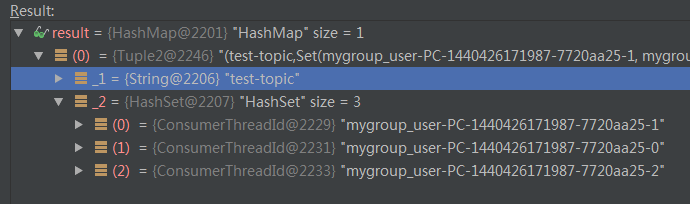
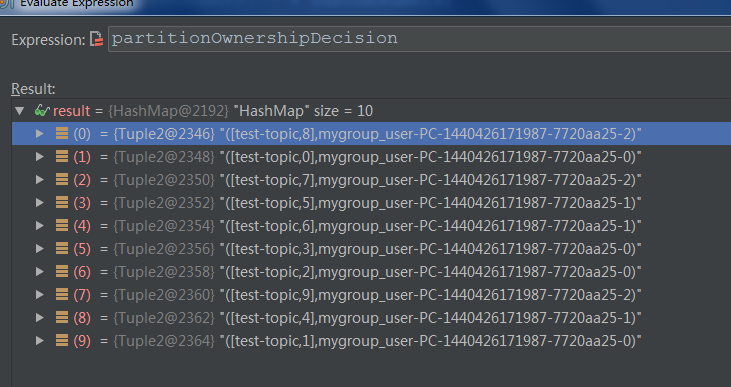
针对于这个例子,nPartsPerConsumer就是10/3=3,nConsumersWithExtraPart为10%3=1,说明每个线程至少保证3个分区,还剩下1个分区需要单独分配给开头的若干个线程。这就是为什么C0消费4个分区,后面的2个线程每个消费3个分区,具体过程详见下面的Debug截图信息:





【转】如何确定Kafka的分区数、key和consumer线程数的更多相关文章
- 如何确定Kafka的分区数、key和consumer线程数
[原创]如何确定Kafka的分区数.key和consumer线程数 在Kafak中国社区的qq群中,这个问题被提及的比例是相当高的,这也是Kafka用户最常碰到的问题之一.本文结合Kafka源码试 ...
- 【原创】如何确定Kafka的分区数、key和consumer线程数
在Kafak中国社区的qq群中,这个问题被提及的比例是相当高的,这也是Kafka用户最常碰到的问题之一.本文结合Kafka源码试图对该问题相关的因素进行探讨.希望对大家有所帮助. 怎么确定分区数? ...
- Apache Samza流处理框架介绍——kafka+LevelDB的Key/Value数据库来存储历史消息+?
转自:http://www.infoq.com/cn/news/2015/02/apache-samza-top-project Apache Samza是一个开源.分布式的流处理框架,它使用开源分布 ...
- kafka如何防止key相同的消息并发消费
最开始,我认为只用把消费者设置为单线程消费,就可以避免并发问题. 因为同一个key,分区一定相同,那么就只会被同一个消费者消费,消费者又是单线程,这样就避免了并发问题 后面发现,上述的方式没有办法处理 ...
- springboot kafka集成(实现producer和consumer)
本文介绍如何在springboot项目中集成kafka收发message. 1.先解决依赖 springboot相关的依赖我们就不提了,和kafka相关的只依赖一个spring-kafka集成包 &l ...
- Apache Kafka - KIP-42: Add Producer and Consumer Interceptors
kafka 0.10.0.0 released Interceptors的概念应该来自flume 参考,http://blog.csdn.net/xiao_jun_0820/article/det ...
- kafka producer自定义partitioner和consumer多线程
为了更好的实现负载均衡和消息的顺序性,Kafka Producer可以通过分发策略发送给指定的Partition.Kafka Java客户端有默认的Partitioner,平均的向目标topic的各个 ...
- Kafka 学习笔记之 Producer/Consumer (Scala)
既然Kafka使用Scala写的,最近也在慢慢学习Scala的语法,虽然还比较生疏,但是还是想尝试下用Scala实现Producer和Consumer,并且用HashPartitioner实现消息根据 ...
- Kafka 0.10.0.1 consumer get earliest partition offset from Kafka broker cluster - scala code
Return: Map[TopicPartition, Long] Code: val props = new Properties() props.put(ConsumerConfig.BOOTST ...
随机推荐
- 【BZOJ-1597】土地购买 DP + 斜率优化
1597: [Usaco2008 Mar]土地购买 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 2931 Solved: 1091[Submit] ...
- css中margin-top/margin-bottom失效
要设置这两个值,我的理解应该在这个div的父容器中设置了固定宽高,或者设置了绝对定位,比如position:absolute(绝对定位) 或者压根不用,直接用padding-top/padding-b ...
- 计算机组成原理 及CPU,硬盘,内存三者的关系
前面提到了,电脑之父——冯·诺伊曼提出了计算机的五大部件:输入设备.输出设备.存储器.运算器和控制器. 我们看一下现在我们电脑的: 键盘鼠标.显示器.机箱.音响等等. 这里显示器为比较老的CRT显示器 ...
- ini_set()函数的使用 以及 post_max_size,upload_max_filesize的修改方法
Apache服务器处理: ini_set('display_errors', 'Off');ini_set('memory_limit', -1); //-1 / 10240Mini_set(&quo ...
- espcms /public/class_connector.php intval truncation Vul Arbitrary User Login
catalog . 漏洞描述 . 漏洞触发条件 . 漏洞影响范围 . 漏洞代码分析 . 防御方法 . 攻防思考 1. 漏洞描述 Relevant Link:2. 漏洞触发条件3. 漏洞影响范围4. 漏 ...
- ecshop /pick_out.php SQL Injection Vul By Local Variable Overriding
catalog . 漏洞描述 . 漏洞触发条件 . 漏洞影响范围 . 漏洞代码分析 . 防御方法 . 攻防思考 1. 漏洞描述 在进行输入变量本地模拟注册的时候,没有进行有效的GPC模拟过滤处理,导出 ...
- Linux使用网盘客户端
1. 百度网盘 - bypy https://github.com/houtianze/bypy 这是一个基于Python的命令行客户端. 安装参考上面链接的说明,或者这篇文章(推荐,有告诉你如何安装 ...
- A.Kaw矩阵代数初步学习笔记 2. Vectors
“矩阵代数初步”(Introduction to MATRIX ALGEBRA)课程由Prof. A.K.Kaw(University of South Florida)设计并讲授. PDF格式学习笔 ...
- 【Alpha版本】 第六天 11.14
一.站立式会议照片: 二.项目燃尽图: 三.项目进展: 成 员 昨天完成任务 今天完成任务 明天要做任务 问题困难 心得体会 胡泽善 完成管理员的三大界面框架.完成管理主界面 完成我要招聘的招聘详情显 ...
- Ubuntu学习总结-02 Ubuntu下的FTP服务的安装和设置
一 安装vsftpd 在安装前vsftpd,先更新apt-get下载的数据源输入如下命令: sudo apt-get update 然后安装vsftpd sudo apt-get install vs ...