【转】如何确定Kafka的分区数、key和consumer线程数
def partition(key: Any, numPartitions: Int): Int = {
Utils.abs(key.hashCode) % numPartitions
}
这就保证了相同key的消息一定会被路由到相同的分区。如果你没有指定key,那么Kafka是如何确定这条消息去往哪个分区的呢?

if(key == null) { // 如果没有指定key
val id = sendPartitionPerTopicCache.get(topic) // 先看看Kafka有没有缓存的现成的分区Id
id match {
case Some(partitionId) =>
partitionId // 如果有的话直接使用这个分区Id就好了
case None => // 如果没有的话,
val availablePartitions = topicPartitionList.filter(_.leaderBrokerIdOpt.isDefined) //找出所有可用分区的leader所在的broker
if (availablePartitions.isEmpty)
throw new LeaderNotAvailableException("No leader for any partition in topic " + topic)
val index = Utils.abs(Random.nextInt) % availablePartitions.size // 从中随机挑一个
val partitionId = availablePartitions(index).partitionId
sendPartitionPerTopicCache.put(topic, partitionId) // 更新缓存以备下一次直接使用
partitionId
}
}
可以看出,Kafka几乎就是随机找一个分区发送无key的消息,然后把这个分区号加入到缓存中以备后面直接使用——当然了,Kafka本身也会清空该缓存(默认每10分钟或每次请求topic元数据时)
val nPartsPerConsumer = curPartitions.size / curConsumers.size // 每个consumer至少保证消费的分区数
val nConsumersWithExtraPart = curPartitions.size % curConsumers.size // 还剩下多少个分区需要单独分配给开头的线程们
...
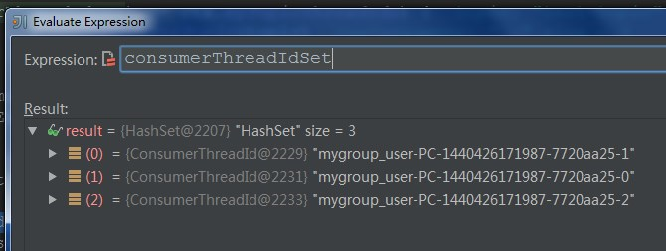
for (consumerThreadId <- consumerThreadIdSet) { // 对于每一个consumer线程
val myConsumerPosition = curConsumers.indexOf(consumerThreadId) //算出该线程在所有线程中的位置,介于[0, n-1]
assert(myConsumerPosition >= 0)
// startPart 就是这个线程要消费的起始分区数
val startPart = nPartsPerConsumer * myConsumerPosition + myConsumerPosition.min(nConsumersWithExtraPart)
// nParts 就是这个线程总共要消费多少个分区
val nParts = nPartsPerConsumer + (if (myConsumerPosition + 1 > nConsumersWithExtraPart) 0 else 1)
...
}
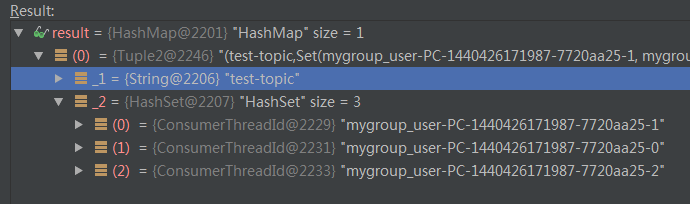
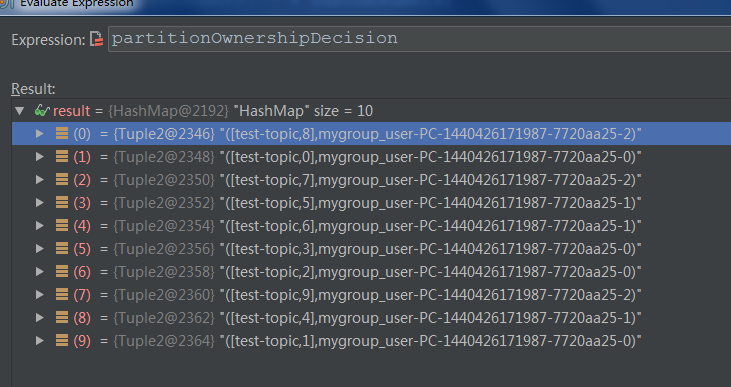
针对于这个例子,nPartsPerConsumer就是10/3=3,nConsumersWithExtraPart为10%3=1,说明每个线程至少保证3个分区,还剩下1个分区需要单独分配给开头的若干个线程。这就是为什么C0消费4个分区,后面的2个线程每个消费3个分区,具体过程详见下面的Debug截图信息:





【转】如何确定Kafka的分区数、key和consumer线程数的更多相关文章
- 如何确定Kafka的分区数、key和consumer线程数
[原创]如何确定Kafka的分区数.key和consumer线程数 在Kafak中国社区的qq群中,这个问题被提及的比例是相当高的,这也是Kafka用户最常碰到的问题之一.本文结合Kafka源码试 ...
- 【原创】如何确定Kafka的分区数、key和consumer线程数
在Kafak中国社区的qq群中,这个问题被提及的比例是相当高的,这也是Kafka用户最常碰到的问题之一.本文结合Kafka源码试图对该问题相关的因素进行探讨.希望对大家有所帮助. 怎么确定分区数? ...
- Apache Samza流处理框架介绍——kafka+LevelDB的Key/Value数据库来存储历史消息+?
转自:http://www.infoq.com/cn/news/2015/02/apache-samza-top-project Apache Samza是一个开源.分布式的流处理框架,它使用开源分布 ...
- kafka如何防止key相同的消息并发消费
最开始,我认为只用把消费者设置为单线程消费,就可以避免并发问题. 因为同一个key,分区一定相同,那么就只会被同一个消费者消费,消费者又是单线程,这样就避免了并发问题 后面发现,上述的方式没有办法处理 ...
- springboot kafka集成(实现producer和consumer)
本文介绍如何在springboot项目中集成kafka收发message. 1.先解决依赖 springboot相关的依赖我们就不提了,和kafka相关的只依赖一个spring-kafka集成包 &l ...
- Apache Kafka - KIP-42: Add Producer and Consumer Interceptors
kafka 0.10.0.0 released Interceptors的概念应该来自flume 参考,http://blog.csdn.net/xiao_jun_0820/article/det ...
- kafka producer自定义partitioner和consumer多线程
为了更好的实现负载均衡和消息的顺序性,Kafka Producer可以通过分发策略发送给指定的Partition.Kafka Java客户端有默认的Partitioner,平均的向目标topic的各个 ...
- Kafka 学习笔记之 Producer/Consumer (Scala)
既然Kafka使用Scala写的,最近也在慢慢学习Scala的语法,虽然还比较生疏,但是还是想尝试下用Scala实现Producer和Consumer,并且用HashPartitioner实现消息根据 ...
- Kafka 0.10.0.1 consumer get earliest partition offset from Kafka broker cluster - scala code
Return: Map[TopicPartition, Long] Code: val props = new Properties() props.put(ConsumerConfig.BOOTST ...
随机推荐
- matplotlib 柱状图、饼图;直方图、盒图
#-*- coding: utf-8 -*- import matplotlib.pyplot as plt import numpy as np import matplotlib as mpl m ...
- 【BZOJ-2721】樱花 线性筛 + 数学
2721: [Violet 5]樱花 Time Limit: 5 Sec Memory Limit: 128 MBSubmit: 499 Solved: 293[Submit][Status][D ...
- NuGet包调试源码的方法
如果按照nuget官网给出的网址:https://docs.nuget.org/create/creating-and-publishing-a-symbol-package 那么你会发觉下载符号包的 ...
- fbv (FrameBuffer Viewer)编译指南
fbv:FrameBuffer image Viewer,可在控制台下查看jpg,png,gif,bmp等格式的图片,可以结合FBTerm在控制台设置背景图片,也可在编译在嵌入式设备上使用.但是ubu ...
- Bzoj2563 阿狸和桃子的游戏
Time Limit: 3 Sec Memory Limit: 128 MBSubmit: 701 Solved: 496 Description 阿狸和桃子正在玩一个游戏,游戏是在一个带权图G= ...
- UVa 101 The Blocks Problem Vector基本操作
UVa 101 The Blocks Problem 一道纯模拟题 The Problem The problem is to parse a series of commands that inst ...
- 编写 unix和 windows的 Scala 脚本
编写 unix和 windows的 Scala 脚本 今天在看<Scala 编程>的时候看到附录了,里面提到了怎么在 unix 和 windows 下面编写 scala 脚本. 之前我也一 ...
- 通往WinDbg的捷径(二)
原文:http://www.debuginfo.com/articles/easywindbg2.html译者:arhat时间:2006年4月14日关键词:CDB WinDbg 保存 dumps 在我 ...
- IOS - 打印COOKIE中的 CRFSToken
NSHTTPCookie 在iOS中使用NSHTTPCookie类封装一条cookie,通过NSHTTPCookie的方法读取到cookie的通用属性. - (NSUInteger)version; ...
- 捉襟见肘之TableView的手势(删除、编辑等)与转场动画手势冲突
在使用PresentModel的方式进行转场动画时,出现UIPercentDrivenInteractiveTransition和 UITableView的自带手势冲突,问题需要总结,今天系统复习和总 ...