Oracle性能优化之SQL语句
1.SQL语句执行过程
1.1 SQL语句的执行步骤
1)语法分析,分析语句的语法是否符合规范,衡量语句中各表达式的意义。
2)语义分析,检查语句中涉及的所有数据库对象是否存在,且用户有相应的权限。
3)视图转换,将涉及视图的查询语句转换为相应的对基表查询语句。
4)表达式转换, 将复杂的 SQL 表达式转换为较简单的等效连接表达式。
5)选择优化器,不同的优化器一般产生不同的“执行计划”
6)选择连接方式, ORACLE 主要有三种连接方式,对多表连接ORACLE会选择适当的连接方式。
7)选择连接顺序, 对多表连接 ORACLE 选择哪一对表先连接,选择这两表中哪张表做为基础数据表。
8)选择数据的搜索路径,根据以上条件选择合适的数据搜索路径,比如,是选用全表搜索还是利用索引或是其他的方式。
9)运行“执行计划”
我们可以通过如下语句来查询缓存中的执行计划:
- SELECT t1.*,
- 't2-->',
- t2.*
- FROM v$sql_plan t1
- JOIN v$sql t2
- ON t1.address = t2.address
- AND t1.hash_value = t2.hash_value
- AND t1.child_number = t2.child_number;--缓存中的执行计划。

SELECT t1.*,
't2-->',
t2.*
FROM v$sql_plan t1
JOIN v$sql t2
ON t1.address = t2.address
AND t1.hash_value = t2.hash_value
AND t1.child_number = t2.child_number;--缓存中的执行计划。
1.2 典型SELECT语句完整的执行顺序
1)from子句组装来自不同数据源的数据;
2)where子句基于指定的条件对记录行进行筛选;
3)group by子句将数据划分为多个分组;
4)使用聚集函数进行计算;
5)使用having子句筛选分组;
6)计算所有的表达式;
7)计算select的字段;
8)使用order by对结果集进行排序。
1.3 SQL语句执行过程
如下图所示:
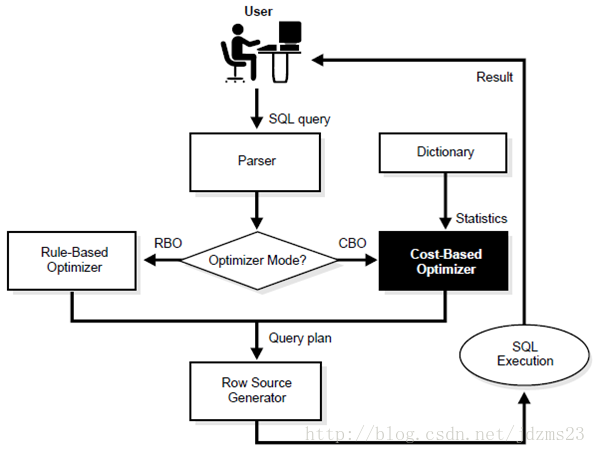
说明:
*这是一张SQL语句执行过程图
*执行计划是SQL语句执行过程中必然用到的
*执行计划是优化器(Optimizer)的产物
*两种不同的方式:CBO和RBO
查看优化器设置:
方法一:
- SELECT VALUE FROM v$parameter t WHERE t.name = 'optimizer_mode';

SELECT VALUE FROM v$parameter t WHERE t.name = 'optimizer_mode';
方法二(SQLPLUS下执行):
- showparameter optimizer_mode
showparameter optimizer_mode
*CBO用到了字典中的Statistics,而RBO没有
分析统计信息相关SQL:
- analyze table tablename compute statistics;
analyze table tablename compute statistics;
- analyze table tablename compute statistics for all indexes
analyze table tablename compute statistics for all indexes
- analyze table tablename delete statistics
analyze table tablename delete statistics
2.优化器及执行计划
2.1 SQL优化方法论
*查看执行计划有好多方式,比如使用PL/SQL Developer工具,选中select语句,按F5键就可以显示其执行计划,不过显示的不完全

*最好使用在Oracle官方的sqlplus工具,性能最好,方便直观,下面介绍两种查看执行计划方式(也是最简单的两种方式)
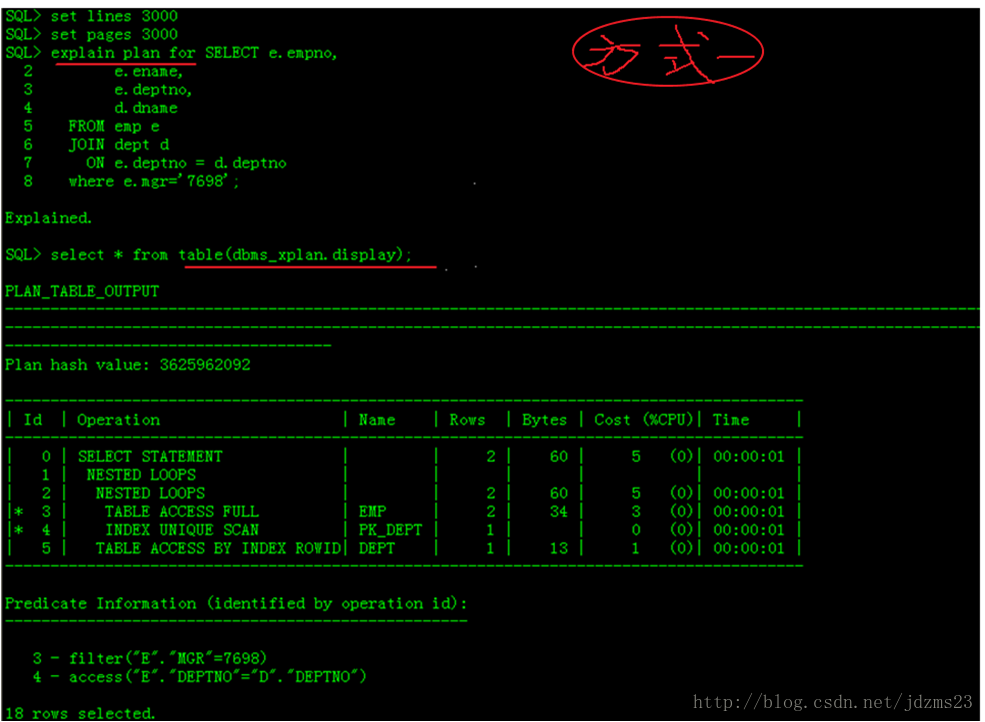
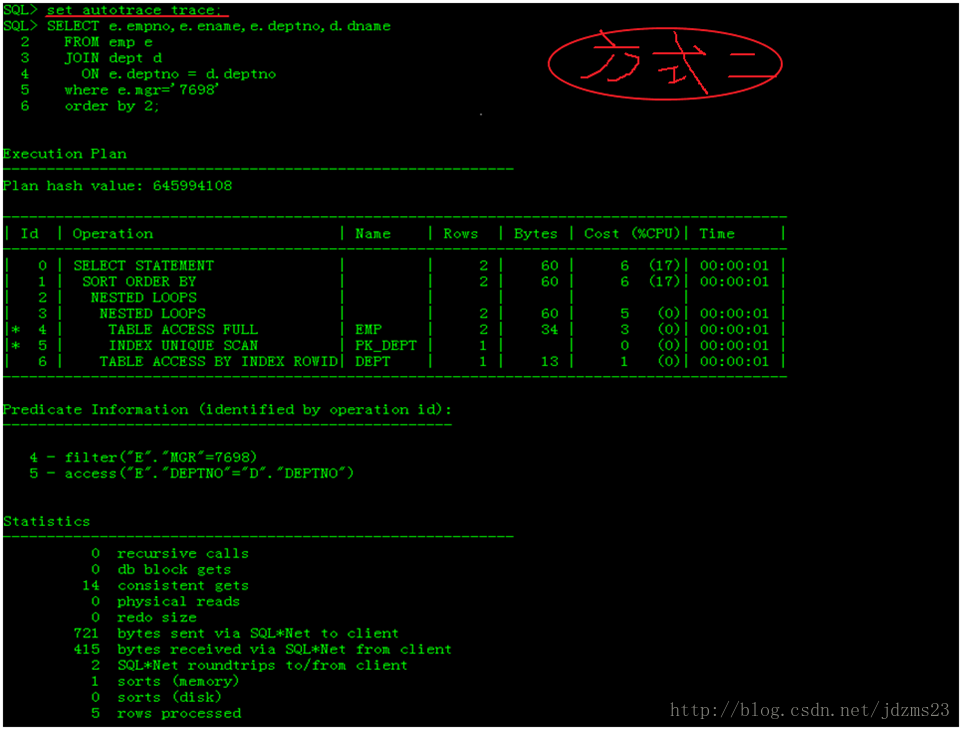
关于执行计划的一些知识:
可以查看参数:
- show parameter STATISTICS_LEVEL
show parameter STATISTICS_LEVEL
第一步:重新收集统计信息!
第二部:第一部解决不了的情况下,使用Hints
3.合理应用Hints
3.1Hints
慎用hint,可能会产生严重的后果,比如append会产生锁块,导致并发资源等待等
Hints的分类:
以下为使用Hints的例子
- create table t_1(owner varchar2(30),table_name varchar2(30));
- create table t_2(owner varchar2(30),table_name varchar2(30));
- insert into t_1 SELECT owner,table_name FROM dba_tables;
- insert into t_2 SELECT owner,view_name FROM dba_views t;
- create index idx_t_1 on t_1(table_name);
- create index idx_t_2 on t_2(table_name);
- analyze table t_1 compute statistics;
- analyze table t_2 compute statistics;
- SELECT *
- FROM (SELECT * FROM t_1
- UNION ALL
- SELECT * FROM t_2) aa
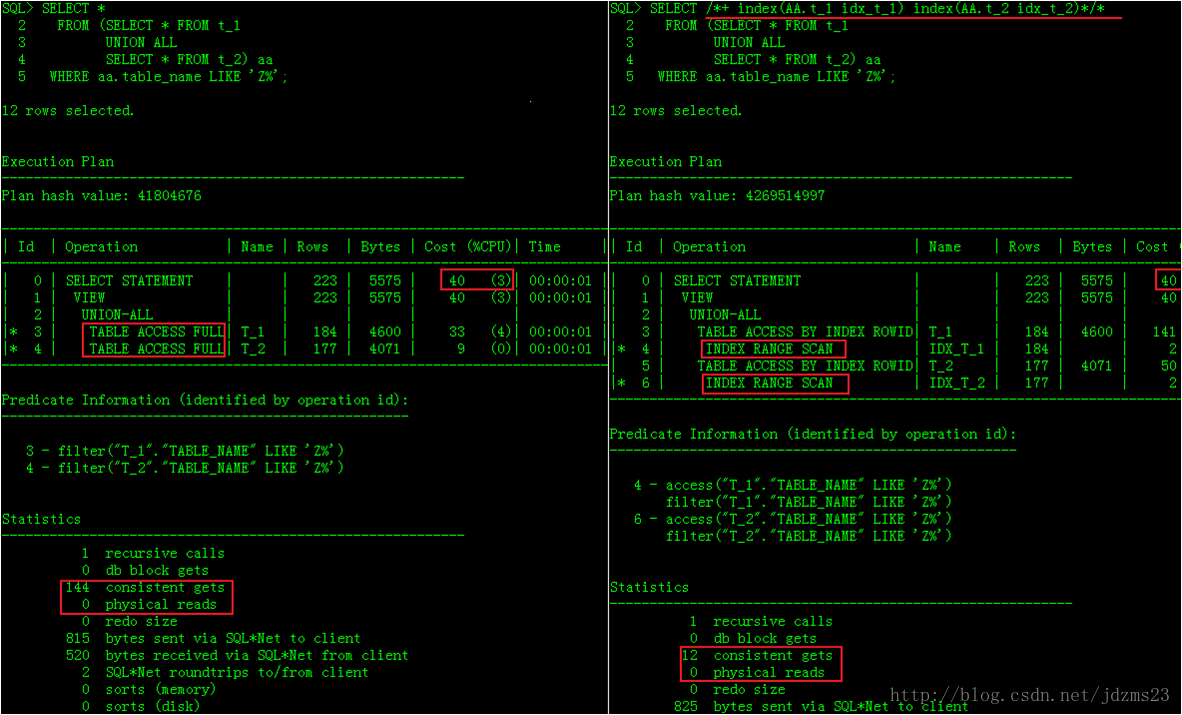
- WHERE aa.table_name LIKE 'Z%'; ---- Full Table Scans
- SELECT /*+ index(AA.t_1 idx_t_1) index(AA.t_2 idx_t_2)*/ *
- FROM (SELECT * FROM t_1
- UNION ALL
- SELECT * FROM t_2) AA
- WHERE AA.table_name LIKE 'Z%'; ---- Index Scans
create table t_1(owner varchar2(30),table_name varchar2(30));
create table t_2(owner varchar2(30),table_name varchar2(30));
insert into t_1 SELECT owner,table_name FROM dba_tables;
insert into t_2 SELECT owner,view_name FROM dba_views t;
create index idx_t_1 on t_1(table_name);
create index idx_t_2 on t_2(table_name);
analyze table t_1 compute statistics;
analyze table t_2 compute statistics; SELECT *
FROM (SELECT * FROM t_1
UNION ALL
SELECT * FROM t_2) aa
WHERE aa.table_name LIKE 'Z%'; ---- Full Table Scans SELECT /*+ index(AA.t_1 idx_t_1) index(AA.t_2 idx_t_2)*/ *
FROM (SELECT * FROM t_1
UNION ALL
SELECT * FROM t_2) AA
WHERE AA.table_name LIKE 'Z%'; ---- Index Scans
贴上执行图:
4.索引及应用实例
4.1什么是索引
所有叶节点上的两个指针形成一个双向链表,在这个双向链表上的所有索引值,从小到大排列,而对于倒序desc索引,则是从大到小排列
B*TREE索引图: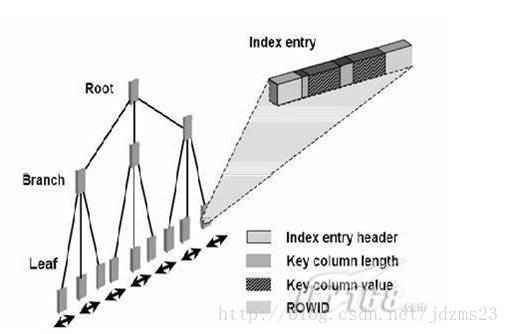
4.2索引分类
逻辑上:
Single column 单列索引
Concatenated 多列索引
Unique 唯一索引
Non-Unique 非唯一索引
Function-based函数索引
Domain 域索引
物理上:
Partitioned 分区索引
Non-Partitioned 非分区索引
B*tree:
Normal 正常型B树
ReverseKey 反转型B树
Bitmap 位图索引
4.3什么时候使用索引
不适合用包含OR操作符的查询;一般不适用NULL判断;
适合高基数的列(重复值少)
做UPDATE代价比较高;会锁块;
非常适合OR操作符的查询;
适合低基数的列(比如,只有Y和N两种值) ;
索引是’双刃剑’,在查询与DML之间寻求平衡
4.4改写SQL使用索引
*普通索引列 a is not null 按逻辑改为a>0或a>''
*like操作改写
*能用union all绝不用union,除非要去重
4.5索引应用
例1.用合适的索引来避免不必要的全表扫
如果要在索引列查询is not null条件,建议列加上is not null约束,默认值约束,
然而确实由于某种原因索引列设计为null,还想通过is null条件走索引,该如何是好呢?请看
- drop table t_tab1;
- create table t_tab1 as
- SELECT t.owner,
- t.object_name,
- t.object_type,
- t.created,
- t.last_ddl_time
- FROM dba_objects t;
- analyze table t_tab1 compute statistics;
- create index idx01_t_tab1 on t_tab1(last_ddl_time);--普通索引
- set autotrace trace;
- SELECT * FROM t_tab1 t where t.last_ddl_time is null;
drop table t_tab1;
create table t_tab1 as
SELECT t.owner,
t.object_name,
t.object_type,
t.created,
t.last_ddl_time
FROM dba_objects t;
analyze table t_tab1 compute statistics;
create index idx01_t_tab1 on t_tab1(last_ddl_time);--普通索引
set autotrace trace;
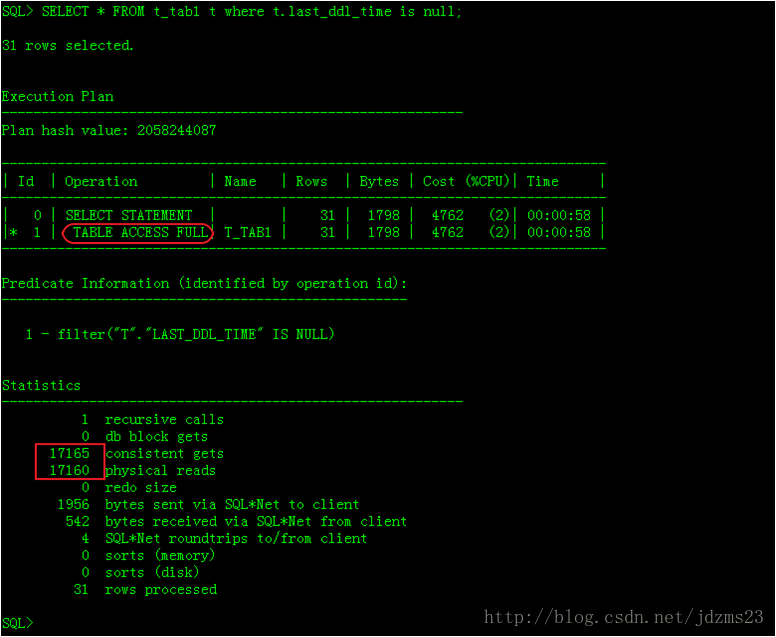
SELECT * FROM t_tab1 t where t.last_ddl_time is null;
执行计划如下图:
如上情况调整为复合索引
- drop index idx01_t_tab1;
- create index idx01_t_tab1 on t_tab1(last_ddl_time,1);--加了个常量
- set autotrace trace;
- SELECT * FROM t_tab1 t where t.last_ddl_time is null;
drop index idx01_t_tab1;
create index idx01_t_tab1 on t_tab1(last_ddl_time,1);--加了个常量
set autotrace trace;
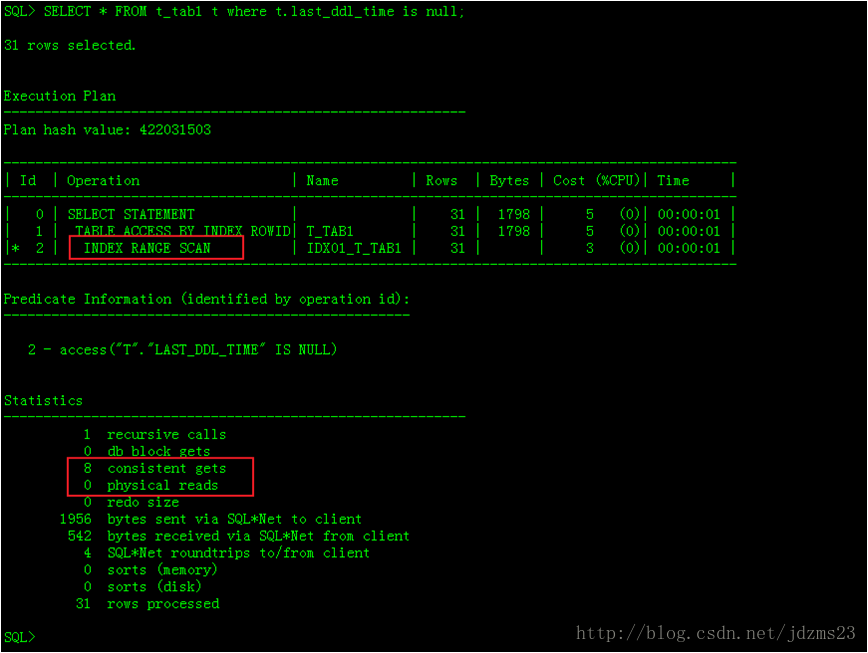
SELECT * FROM t_tab1 t where t.last_ddl_time is null; 执行计划如下图:
例2:用合适的函数索引来避免看似无法避免的全表扫描
- drop table t_tab1 purge;
- create table t_tab1 as
- SELECT t.owner,
- t.object_name,
- t.object_type,
- t.OBJECT_ID,
- t.created,
- t.last_ddl_time
- FROM dba_objects t;
- CREATE INDEX IDX01_T_TAB1 ON T_TAB1(object_name);
- analyze table t_tab1 compute statistics;
- set autot trace
- SELECT * FROM t_tab1 t where t.object_name like '%20121231';
drop table t_tab1 purge;
create table t_tab1 as
SELECT t.owner,
t.object_name,
t.object_type,
t.OBJECT_ID,
t.created,
t.last_ddl_time
FROM dba_objects t;
CREATE INDEX IDX01_T_TAB1 ON T_TAB1(object_name);
analyze table t_tab1 compute statistics;
set autot trace
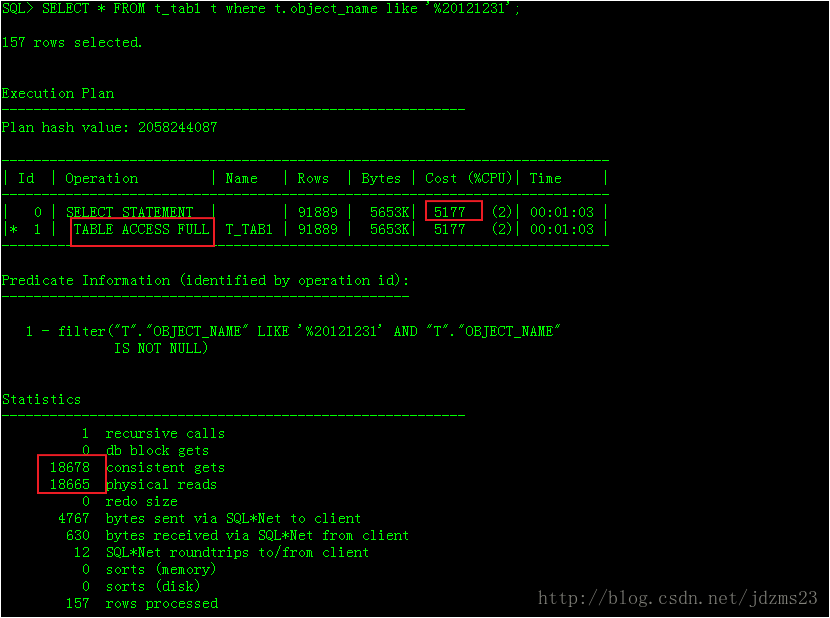
SELECT * FROM t_tab1 t where t.object_name like '%20121231';
执行计划如下:
改进索引,此处使用反转函数索引,此外经常用到的函数索引还有,instr(),substr()等
- drop index IDX01_T_TAB1;
- CREATE INDEX IDX02_T_TAB1 ON T_TAB1(reverse(object_name));
- analyze table t_tab1 compute statistics;
- SELECT * FROM t_tab1 t where reverse(t.object_name) like reverse('%20121231');
drop index IDX01_T_TAB1;
CREATE INDEX IDX02_T_TAB1 ON T_TAB1(reverse(object_name));
analyze table t_tab1 compute statistics;
SELECT * FROM t_tab1 t where reverse(t.object_name) like reverse('%20121231');
执行计划如下:
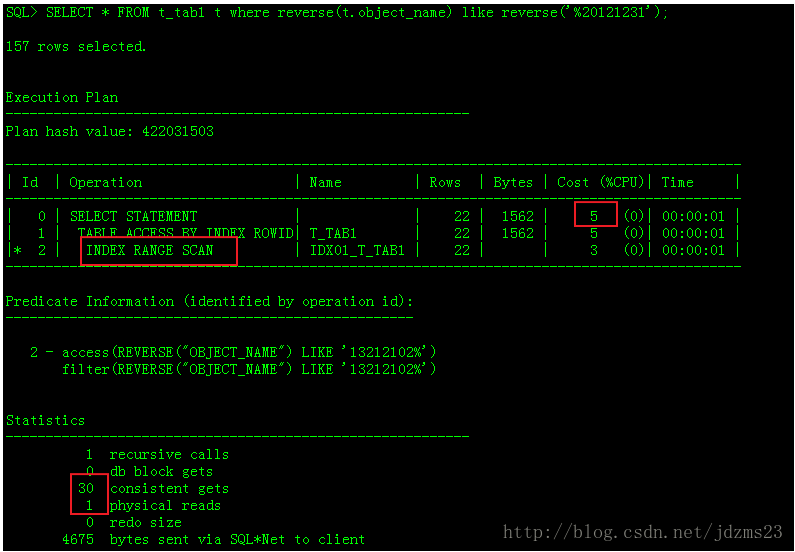
5.其他优化技术及应用
5.1其他优化技术及思路
并行技术,并行执行目标SQL语句,这实际上是以额外的资源消耗来换取执行时间的缩短,很多情况下使用并行是针对某些SQL的唯一优化手段。
使用shell调度或其他调度工具。
SQL语句级别的并行:/*+parallel*/
/*+ parallel(table_name 4)*/
表压缩技术
compress
NOLOGGING
减少日志
Partition技术
分而治之
中间表/临时表事务分解思路
‘大事化小’
求平衡
CPU,Memory很强大,IO存在瓶颈(最普遍的情况)
使用新特性
insertall 啦 使用listagg()比wm_concat()快大概50倍、row_number()等分析函数
软硬件资源合理搭配
黔驴技穷,要求加硬件资源? Boss会对你说,找会计去吧,提前给你开工资 ……
5.2 SQL优化总结
SQL的优化的手段是五花八门、不一而足的,包括但不限于如下措施:
我们可以通过重新收集统计信息或者手工修改统计信息或者使用Hint来加以解决;
Oracle性能优化之SQL语句的更多相关文章
- ORACLE性能优化之SQL语句优化
版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[+] 操作环境:AIX +11g+PLSQL 包含以下内容: 1. SQL语句执行过程 2. 优化器及执行计划 3. 合 ...
- SQL Server数据库性能优化之SQL语句篇【转】
SQL Server数据库性能优化之SQL语句篇http://www.blogjava.net/allen-zhe/archive/2010/07/23/326927.html 近期项目需要, 做了一 ...
- 数据库性能优化之SQL语句优化
一.问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的编写等是体会不出SQL语句各种写法的性能优劣,但是如果将应用系统提交实际应用后,随着数据库中数据的增加,系统 ...
- [转]数据库性能优化之SQL语句优化1
一.问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用系统提交实际应用后,随着数据库中数据的增加,系统 ...
- 数据库性能优化之SQL语句优化(下)
(1) 选择最有效率的表名顺序(只在基于规则的优化器中有效): ORACLE 的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最 ...
- 数据库性能优化之SQL语句优化1
一.问题的提出 在 应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用系统提交实 际应用后,随着数据库中数据的增加, ...
- 数据库性能优化之SQL语句优化(上)
一.问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用系统提交实际应用后,随着数据库中数据的增加,系统的 ...
- Oracle性能优化之查询语句通用原则
作者早期文章 Oracle优化 索引是表的一个概念部分 , 用来提高检索数据的效率, ORACLE 使用了一个复杂的自平衡 B-tree 结构 . 通常 , 通过索引查询数据比全表扫描要快 . 当 O ...
- EBS开发性能优化之SQL语句优化
(1)选择运算 尽可能先做选择运算,这是优化策略中最重要.最基本的一条,选择运算一般会使计算的中间结果大大变小,在对同一表格进行多个选择运算时,选择条件的排列顺序对性能也有很大影响,因为排列顺序不仅影 ...
随机推荐
- IDEA 回滚SVN更新内容
- ubuntu添加sudo权限
ubuntu有时候没有开通sudo功能,有些操作只能切换到root进行,很不方便. 1.切换到root su root 2.打开suduers文件 gedit /etc/sudoers 3.找到下面这 ...
- Linux下多网卡同网段多IP网络分流设定方法
Linux下多网卡同网段多IP网络分流设定方法 -- :: 标签:Linux下多网卡同网段多IP网络分流设定方法 当服务器需要较高的网络流量时,在其它资源不造成瓶颈的情况下无疑会用到多网卡. 第1选项 ...
- oracle数据库常用plsql语句
(一)oracle中常用的数据类型 (二)PL-sql基本语法 1.创建数据库表.删除数据库表 create table table1--创建表 ( field1 number(8), field2 ...
- Unity3d 枚举某个目录下所有资源
using UnityEngine; using System.Collections; using UnityEditor; using System.Collections.Generic; us ...
- 常见web错误码 404 500
404表示文件或资源未找到java WEB常见的错误代码1.1xx-信息提示:这些状态代码表示临时的响应.客户端在收到常规响应之前,应准备接收一个或多个1xx响应.100-继续.101-切换协议.2. ...
- Win7下同时使用有线和无线时的优先级设置
终于找到这个问题的解决方案了!!!!我是通过方法1改跃点数实现的,方法2无效. http://linshengling.blog.163.com/blog/static/114651912012102 ...
- 3.kvm的基本管理
1.查看KVM虚拟机配置文件 #KVM虚拟机默认配置文件位置 [root@kvm qemu]# pwd /etc/libvirt/qemu [root@kvm qemu]# ll total 12 # ...
- linux线程的实现
首先从OS设计原理上阐明三种线程:内核线程.轻量级进程.用户线程 内核线程 内核线程就是内核的分身,一个分身可以处理一件特定事情.这在处理异步事件如异步IO时特别有用.内核线程的使用是廉价的,唯一使用 ...
- 解决svn迁移过程中出现:SVN Error: is not the same repository as的问题
一.背景 由于公司业务的需要,新购买了一批机器,那么面临着的就是svn等一系列东西进行迁移的问题,在svn迁移以后,本地的svn代码在切换时出现了SVN Error: 旧服务器地址 is not th ...