【实战】使用 Kettle 工具将 mysql 数据增量导入到 MongoDB 中
最近有一个将 mysql 数据导入到 MongoDB 中的需求,打算使用 Kettle 工具实现。本文章记录了数据导入从0到1的过程,最终实现了每秒钟快速导入约 1200 条数据。一起来看吧~
一、Kettle 连接图
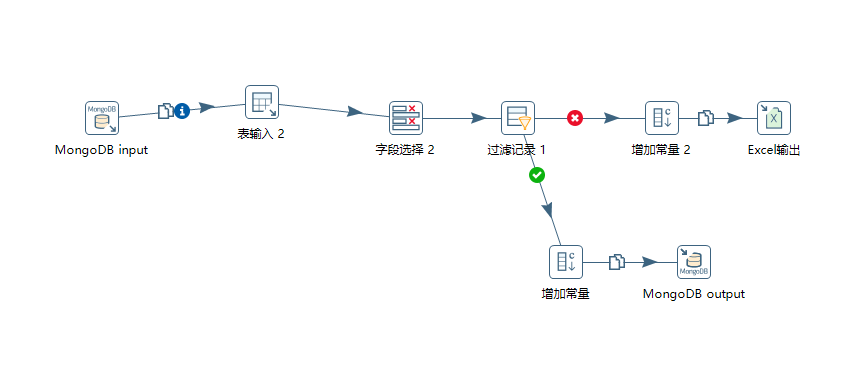
简单说下该转换流程,增量导入数据:
1)根据 source 和 db 字段来获取 MongoDB 集合内 business_time 最大值。
2)设置 mysql 语句
3)对查询的字段进行改名
4)过滤数据:只往 MongoDB 里面导入 person_id,address,business_time 字段均不为空的数据。
- 符合过滤条件的数据,增加常量,并将其导入到 mongoDB 中。
- 不符合过滤条件的数据,增加常量,将其导入到 Excel 表中记录。
二、流程组件解析
1、MongoDB input
1)Configure connection
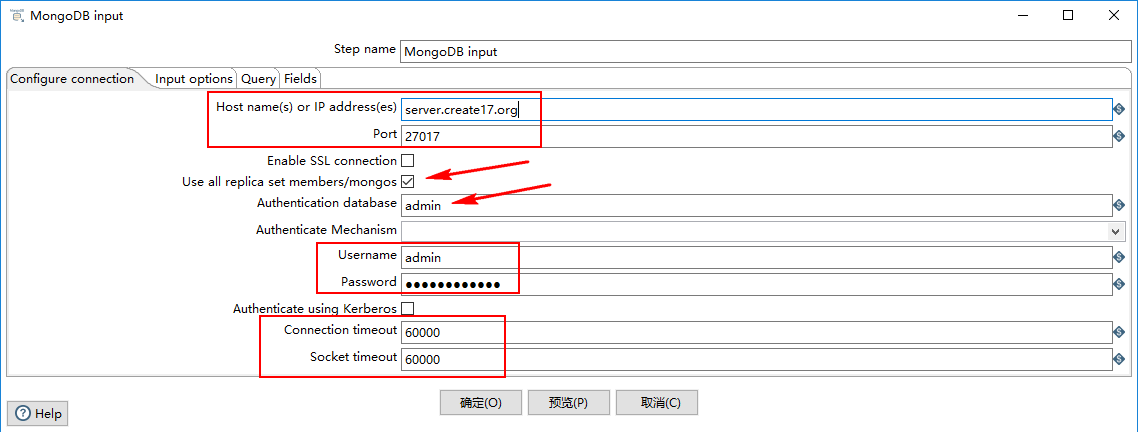
- Host name(s) or IP address(es):网络名称或者地址。可以输入多个主机名或IP地址,用逗号分隔。还可以通过将主机名和端口号与冒号分隔开,为每个主机名指定不同的端口号,并将主机名和端口号的组合与逗号分隔开。例如,要为两个不同的MongoDB实例包含主机名和端口号,您将输入localhost 1:27017,localhost 2:27018,并使 Port 字段为空。
- Port:端口号
- Username:用户名
- Password:密码
- Authenticate using Kerberos:指示是否使用Kerberos服务来管理身份验证过程。
- Connection timeout:连接超时时间(毫秒)
- Socket timeout:等待写操作(以毫秒为单位)的时间
2)Input options

- Database:检索数据的数据库的名称。点击 “Get DBs” 按钮以获取数据库列表。
- Collection:集合名称。点击 “Get collections” 按钮获取集合列表。
- Read preference:表示要先读取哪个节点。
- Tag set specification/#/Tag Set:标签允许您自定义写关注和读取副本的首选项。
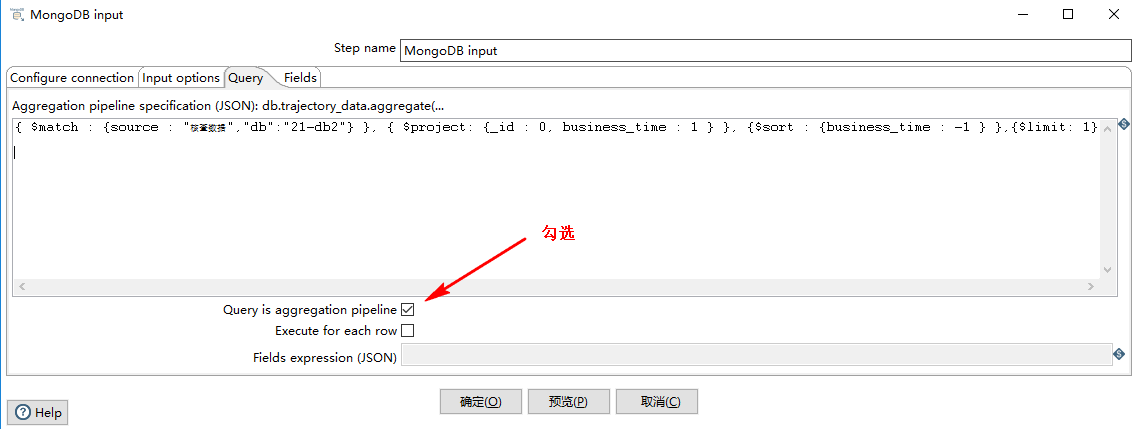
3)query
根据 source 和 db 字段来获取 bussiness_time 的最大值,Kettle 的 MongoDB 查询语句如下图所示:

对应的 MongDB 的写法为:

记得勾选 Query is aggregation pipeline 选项:
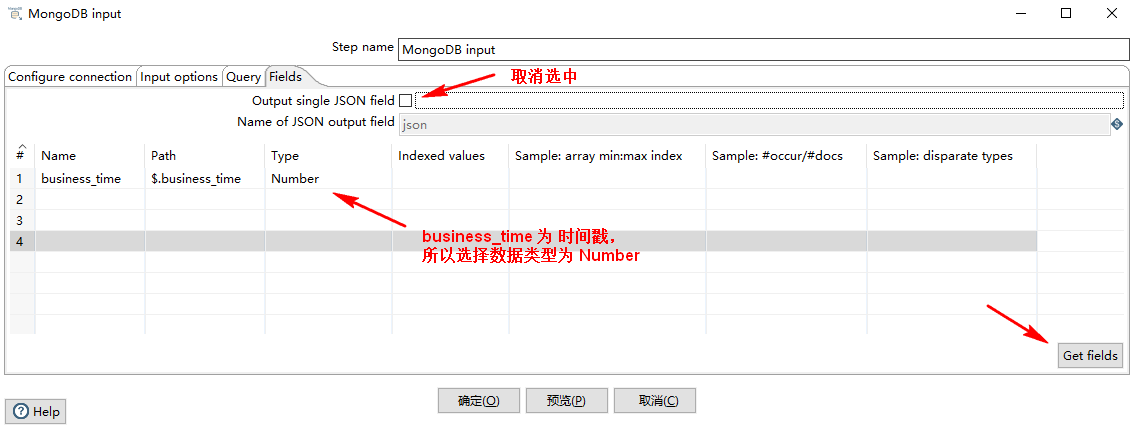
4)Fields
取消选中 Output single JSON field ,表示下一组件接收到的结果是一个 Number 类型的单值,否则就是一个 json 对象。
2、表输入
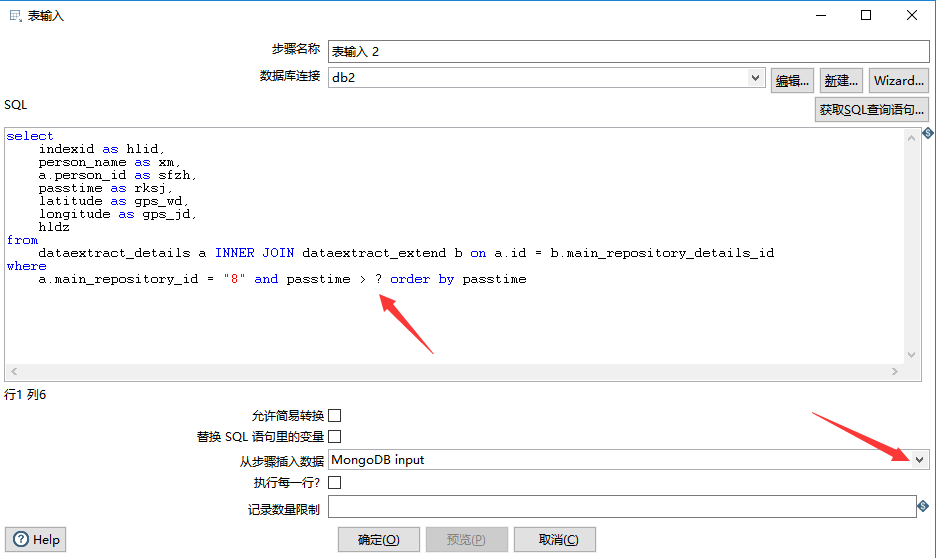
设置 mysql 数据库 jdbc 连接后,填好 SQL 语句之后,在下方的“从步骤插入数据”下拉列表中,选中“MongoDB input”。“MongoDB input” 中的变量,在 SQL 语句中用 ? 表示,如下图所示:
如果导数的时候发生中文乱码,可以点击 编辑 ,选择 数据库连接 的 选项,添加配置项:characterEncoding utf8,即可解决。如下图所示:

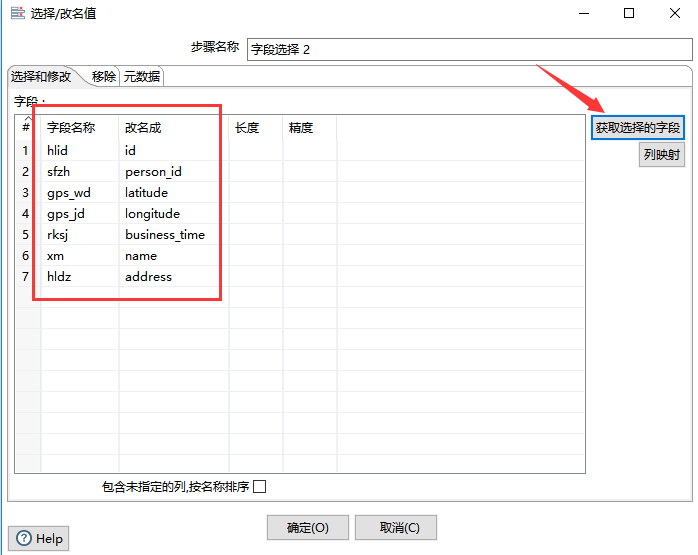
3、字段选择
如果查询出来的列名需要更改,则可以使用“字段选择”组件,该组件还可以移除某字段,本次应用中,主要使用该组件将字段名进行修改。如下图所示:
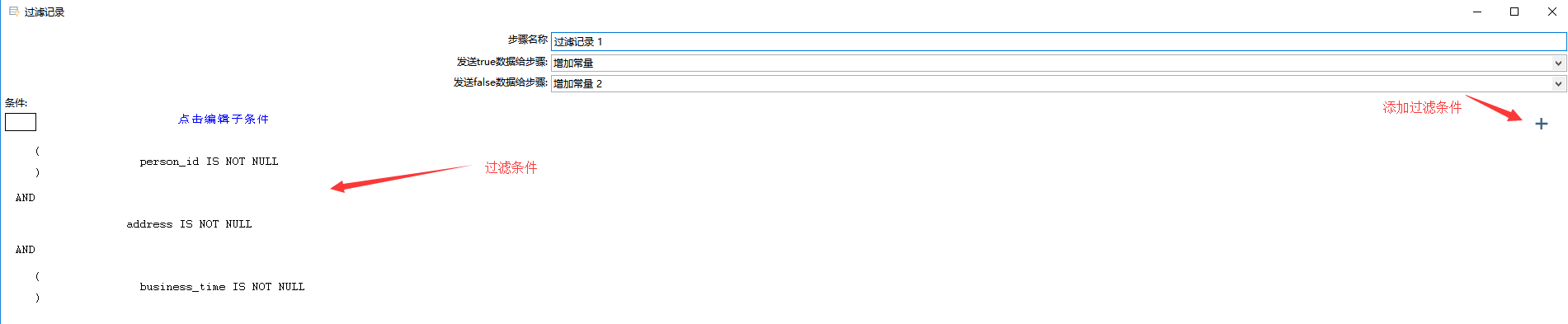
4、过滤选择
只保留 person_id,address,business_time 字段都不为空的数据:
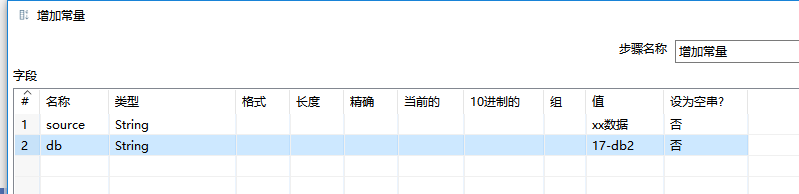
5、增加常量
很简单,在“增加常量”组件内设置好要增加常量的类型和值即可。
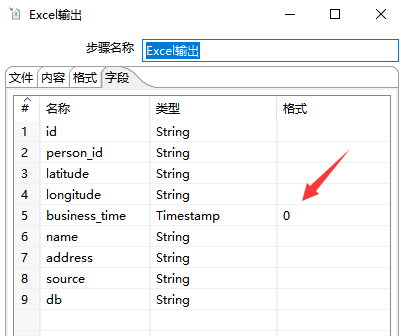
6、Excel 输出
添加“Excel 输出”,设置好文件名,如果有必要的话还可以设置 Excel 字段格式,如下图所示:
7、MongoDB output
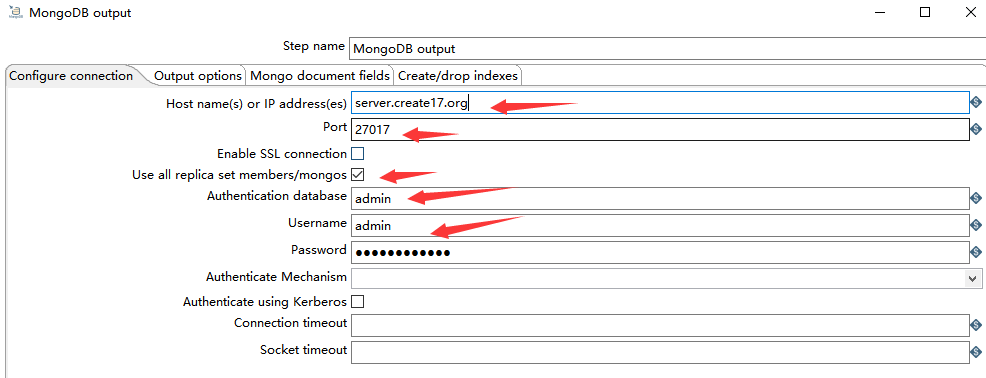
1)Configure connection
如下图所示,由于一开始就介绍了 MongoDB 的连接方式,所以在这里不在赘述。
2)Output options
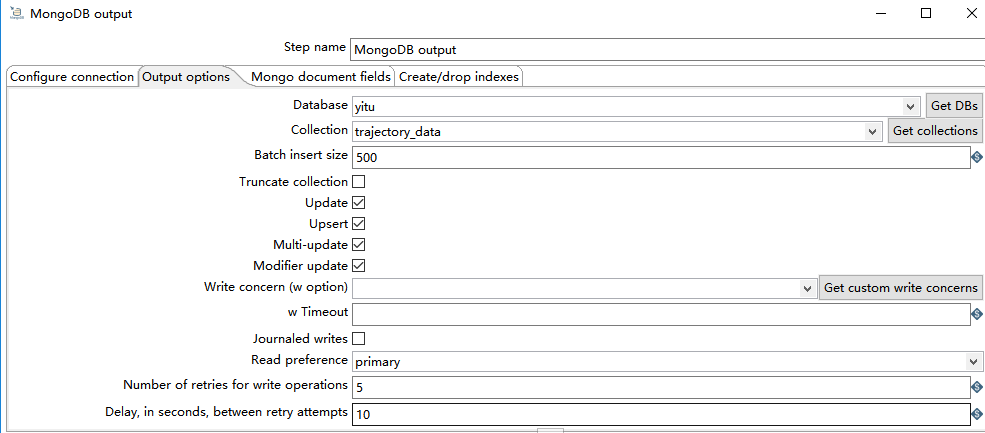
- Batch insert size:每次批量插入的条数。
- Truncate collection:执行操作前先清空集合
- Update:更新数据
- Upsert:选择 Upsert 选项将写入模式从 insert 更改为 upsert(即:如果找到匹配项则更新,否则插入新记录)。使用前提是 勾选 Update 选项。
- Muli-update:多次更新,可以更新所有匹配的文档,而不仅仅是第一个。
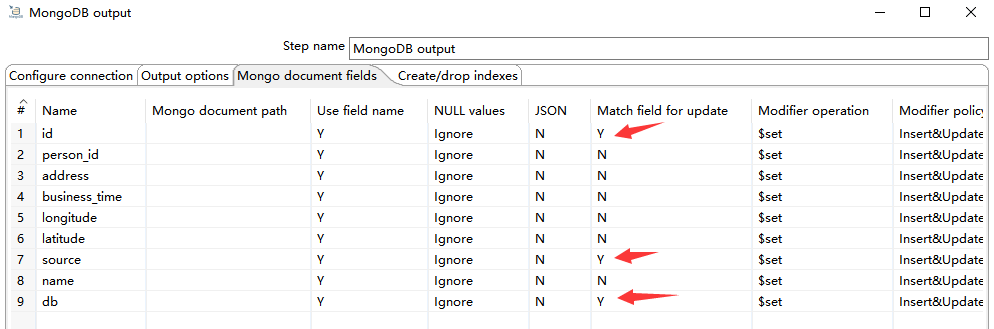
3)Mongo document fields
根据 id、source、db 字段插入更新数据,如下图所示:
更多 MongoDB output 可参考:https://wiki.pentaho.com/display/EAI/MongoDB+Output
三、索引优化
1、mysql
为 mysql 查询字段添加索引。(略)
2、MongoDB
对 MongoDB 查询做优化,创建复合索引:
对于 MongoDB input 组件来说,会关联查询出 business_time 最大值,所以要创建复合索引,创建复合索引时要注意字段顺序,按照查询顺序创建:
db.trajectory_data.createIndex({source: 1, db: 1, business_time: 1})
对于 MongoDB output 组件来说,因为已经设置了 插入或更新 数据的规则,也会涉及到查询,所以再设置一个复合索引:
db.trajectory_data.createIndex({id: 1, source: 1, db: 1})
四、运行
运行前,需要在集合内插入一条含 business_time 字段的 demo 数据,否则 MongoDB input 会因为查不到数据而报错:
db.trajectory_data.insert({
id: 0,
source: 'xx数据',
db: "17-db2",
business_time: 0
})
成功插入数据后,执行该转换:
- 可视化操作
- 命令行操作:${KETTLE_HOME}/pan.sh -file=xxx.ktr
可通过点击 “执行结果” --> “步骤度量” 来查看各组件运行状态,如下图所示:
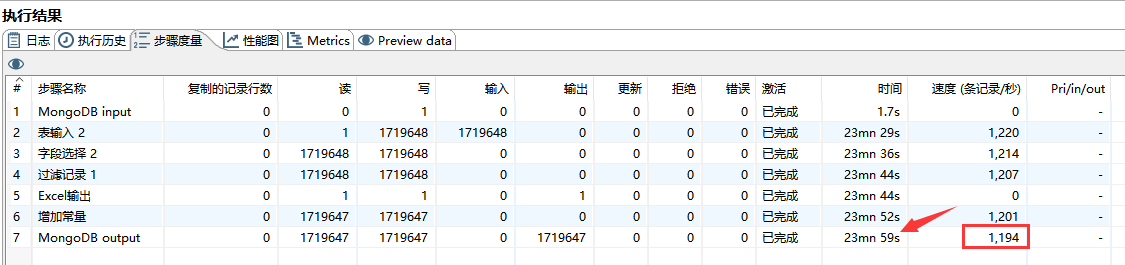
24 分钟共导了 172 万的数据,每秒钟约导入 1200 条数据。
这样子,这个转换基本就算完成了。可以在 linux 上写一个定时任务去执行这个转换,每次转换 mysql 都会将大于 mongoDB 集合中 business_time 字段最大值的数据增量导入到 MongoDB 中。
五、不足
像上述的 Kettle 流程也是有不足的。假如一次性拉取的数据量过大,很有可能导致 Mysql 或 Kettle 内存溢出而报错。所以上述流程只适合小数据量导入。大数据量导入的话还是建议分批次导入或者分页导入,大家可以研究一下。

【实战】使用 Kettle 工具将 mysql 数据增量导入到 MongoDB 中的更多相关文章
- MySQL数据导出导入【转】
MySQL基础 关于MySQL数据导出导入的文章,目的有二: 1.备忘 2.供开发人员测试 工具 mysqlmysqldump 应用举例 导出 导出全库备份到本地的目录 mysqldump -u$US ...
- 第3节 sqoop:6、sqoop的数据增量导入和数据导出
增量导入 在实际工作当中,数据的导入,很多时候都是只需要导入增量数据即可,并不需要将表中的数据全部导入到hive或者hdfs当中去,肯定会出现重复的数据的状况,所以我们一般都是选用一些字段进行增量的导 ...
- Sqoop- sqoop将mysql数据表导入到hive报错
sqoop将mysql数据表导入到hive报错 [root@ip---- lib]# sqoop import --connect jdbc:mysql://54.223.175.12:3308/gx ...
- 文本数据增量导入到mysql
实现思路: 实现Java读取TXT文件中的内容并存到内存,将内存中的数据和mysql 数据库里面某张表数据的字段做一个比较,如果比较内存中的数据在mysql 里存在则不做处理,如果不存在则 ...
- 完美转换MySQL的字符集 Mysql 数据的导入导出,Mysql 4.1导入到4.0
MySQL从4.1版本开始才提出字符集的概念,所以对于MySQL4.0及其以下的版本,他们的字符集都是Latin1的,所以有时候需要对mysql的字符集进行一下转换,MySQL版本的升级.降级,特别是 ...
- mysql 数据到 导入导出 总结
数据库数据的导入和导出受secure_file_priv配置项影响#限制导入导出,null时无法进行数据的导入导出,空时不限制,设置了目录则只能对该目录下的文件进行导入导出show variables ...
- 关于C#读取MySql数据时,返回DataTable中某字段数据是System.Array[]形式
我在使用C#(VS2008)读取MySql数据库(5.1版本)时,返回的DataTable数据中arrivalDate字段数据显示为System.Array[]形式(程序中没有对返回的数据进行任何加工 ...
- Linux下MySql数据的导入导出
1,每天4点备份mysql数据: 2,为节省空间,删除超过3个月的所有备份数据: 3,删除超过7天的备份数据,保留3个月里的 10号 20号 30号的备份数据: mysqldump -u用戶名 -p密 ...
- 将EXCEL数据表导入到SQL中
工具/原料 SQL Server Management Studio 已建立SQL数据库 方法/步骤 打开SQL Server Management Studio,按图中的路径进入导入数据界面. ...
随机推荐
- 一个基于 Slab 缓存的 scull: scullc
是时候给个例子了. scullc 是一个简化的 scull 模块的版本, 它只实现空设备 -- 永久 的内存区. 不象 scull, 它使用 kmalloc, scullc 使用内存缓存. 量子的大小 ...
- 2018.11.23 浪在ACM 集训队第六次测试赛
2018.11.23 浪在ACM 集训队第六次测试赛 整理人:刘文胜 div 2: A: Jam的计数法 参考博客:[1] 万众 B:数列 参考博客: [1] C:摆花 参考博客: [1] D:文化之 ...
- 关于react的redux的知识点
项目小的时候我们getState()进行管理数据,只有当数据庞大的时候我们采用Redux来进行管理. Redux: ①:它是专注于状态管理的库,和React是解耦的 ②:它是单向数据流,单一的状态 ③ ...
- Windows 服务安装与卸载 (通过 Sc.exe)
1. 安装 新建文本文件,重命名为 ServiceInstall.bat,将 ServiceInstall.bat 的内容替换为: sc create "Verity Platform De ...
- C# 如何解析XML
- linux上传文件的命令
由于svm挂机不能通过svn提交代码,所以今天尝试了一下linux的rz和sz命令 1.sz命令是把文件下载到本地,使用方法如下 sz 文件名 回车之后会弹出一个本地的路径选择框,选择要下载的路径即 ...
- 编写自己的JDBC框架(转)
一.元数据介绍 元数据指的是"数据库"."表"."列"的定义信息. 1.1.DataBaseMetaData元数据 Connection.g ...
- Service Mesh服务网格清单
Service Mesh服务网格清单 Istio Istio官网 Istio中文官网 Istio开源 无需太多介绍Service Mesh明日之星,扛把子,截止2019.11还有太多问题没解决 复杂性 ...
- RecursiveTask和RecursiveAction的使用总结
一:什么是Fork/Join框架 Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架.我们再通 ...
- 【E20200101-1】Centos 7.x 关闭防火墙(firewall)和SELinux
一.准备工作 1.1.服务器准备 操作系统:centos 7.x 1.2.安装好用的文本编辑工具nano # yum -y install nano 二.关闭SELinux 2.1.查看SELinux ...