MongoDB 基础API使用
1. 基本概念:
1.1. MongoDB 保留数据库名:
- admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器
- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息
2. 数据库
2.1. 查询数据库
// ----- 查看所有数据库
show dbs
// ----- 查询当前所在数据库
db
2.2. 创建\切换数据库
// ----- DB_NAME: 数据库名, 当该名称数据库不存在时, 创建数据库; 当该名称数据库存在时, 切换数据库.
use DB_NAME
3.3. 删除数据库
// ----- 切换到需要删除的数据库, 然后进行删除
db.dropDatabase()

3. 集合
3.1. 查看所有的集合
show collectios
3.2. 创建集合
// ----- 方式1: 创建集合
/**
* name: 集合的名称 [必填]
* options: 集合的内存大小及索引选项 [选填]
* * capped: (布尔), 如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。当该值为 true 时,必须指定 size 参数。
* * autoIndexId: 如为 true,自动在 _id 字段创建索引。默认为 false。
* * size: 为固定集合指定一个最大值(以字节计)。如果 capped 为 true,也需要指定该字段。
* * max: 指定固定集合中包含文档的最大数量。
*/
db.createCollection(name, [options]) // ----- 方式2: 插入文档时, 自动创建集合
3.3. 删除集合
db.test.drop()

4. 文档
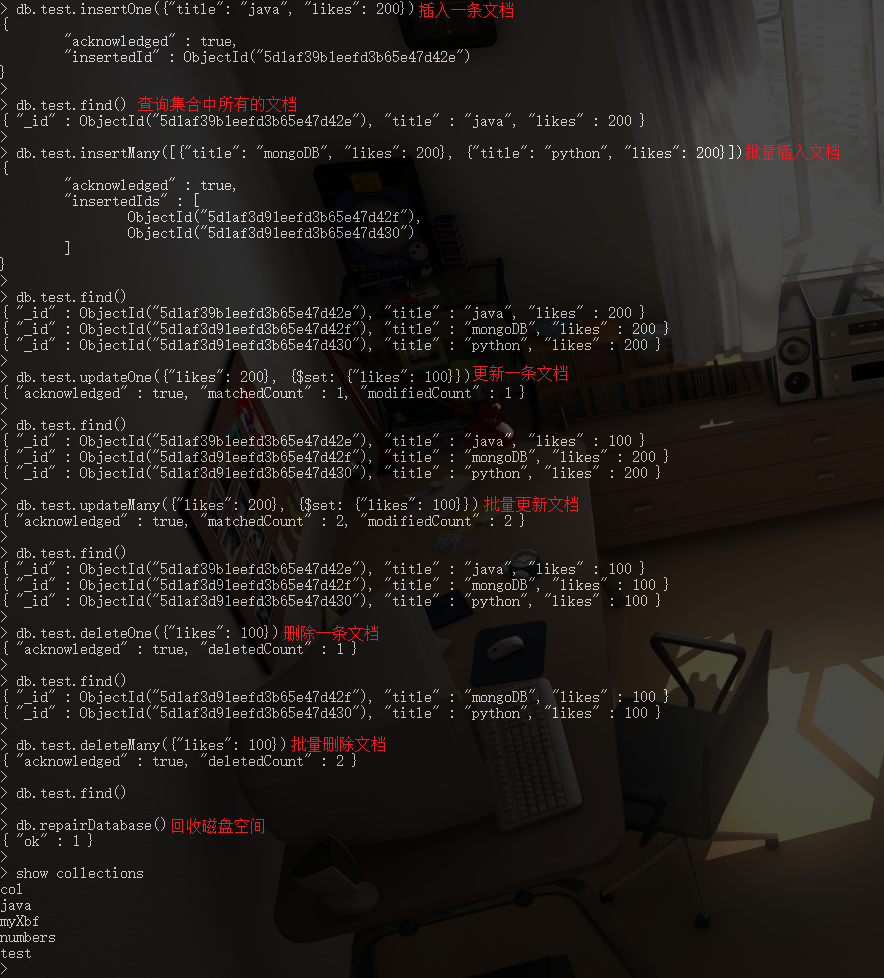
4.1. 插入文档
// ***** 注: 插入文档时, 当指定的集合不存在时, 会自动创建集合
// ----- 插入一条文档
db.COLLECTION_NAME.insertOne(document)
// ----- 插入多条文档
db.COLLECTION_NAME.insertMany([document, document......])
4.2. 查询所有文档
db.test.find()
4.3. 更新文档
/**
* quety: update的查询条件,类似 SQL SELECT 语句的WHERE条件。当条件为空时, 匹配所有文档
* update: update的对象和一些更新的操作符(如$set,$inc...)等,类似于 SQL UPDATE 语句中的SET语句
*/
// ----- 更新第一条符合条件的文档
db.COLLECTION_NAME.updateOne(<query>, <update>)
// ----- 更新所有符合条件的文档
db.COLLECTION_NAME.updateMany(<query>, <update>)
4.4. 删除文档
// ***** query: 删除文档的条件, 当条件为空时, 则匹配所有文档, 类似于 SQL DELETE 语句中的WHERE条件
// ----- 删除第一条符合条件的文档
db.COLLECTION_NAME.deleteOne(<query>)
// ----- 删除所有符合条件的文档
db.COLLECTION_NAME.deleteMany(<query>)
4.5. 回收磁盘空间
db.repairDatabase()
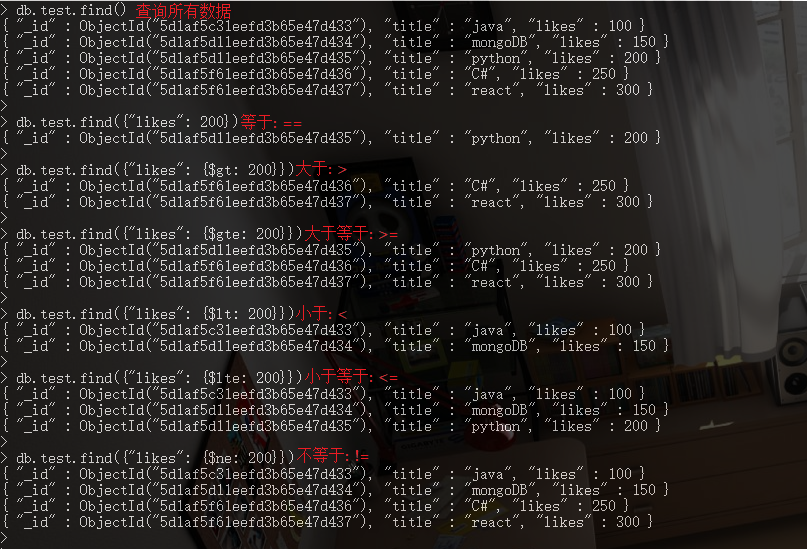
5. 文档的查询 [基础条件]

5.1. 条件查询 [等于 ==]
// ----- 方式1
db.COLLECTION_NAME.find({KEY: VALUE})
// ----- 方式2
db.COLLECTION_NAME.find({KEY: {$eq: VALUE}})
5.2. 条件查询 [大于 >]
db.COLLECTION_NAME.find({KEY: {$gt: VALUE}})
5.3. 条件查询 [大于等于 >=]
db.COLLECTION_NAME.find({KEY: {$gte: VALUE}})
5.4. 条件查询 [小于 <]
db.COLLECTION_NAME.find({KEY: {$lt: VALUE}})
5.5. 条件查询 [小于等于 <=]
db.COLLECTION_NAME.find({KEY: {$lte: VALUE}})
5.6. 条件查询 [不等于 !=]
db.COLLECTION_NAME.find({KEY: {$ne: VALUE}})
6. 文档的查询 [组合条件]
6.1. AND
db.COLLECTION_NAME.find({$and: [{KEY1: {VALUE1}}, {KEY2: {VALUE2}}]})
6.2. OR
db.COLLECTION_NAME.find({$or: [{KEY1: {VALUE1}}, {KEY2: {VALUE2}}]})

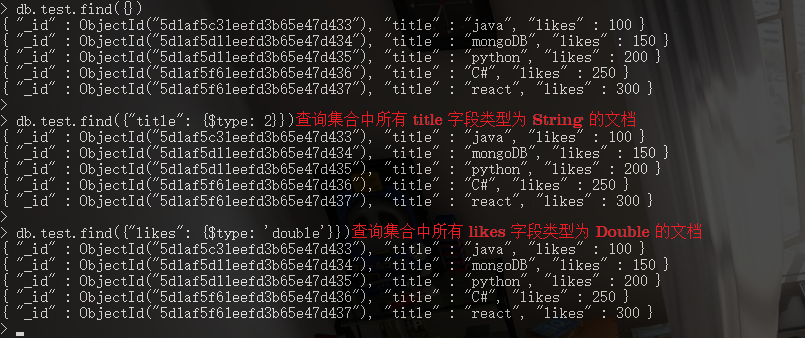
7. 文档的查询 [数据类型]
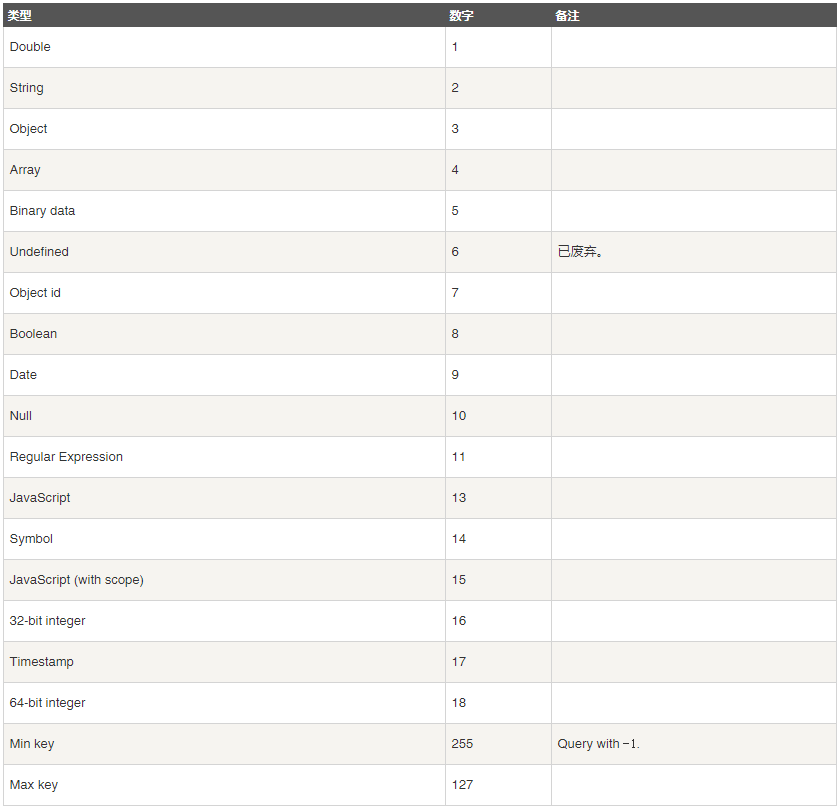
// ***** type_num: 表格中对应的数字; type_str: 表格中对应的类型.
db.COLLECTION_NAME.find({KEY: {$type: <type_num>}})
db.COLLECTION_NAME.find({KEY: {$type: <type_str>}})
8. 文档的查询 [排序和分页]
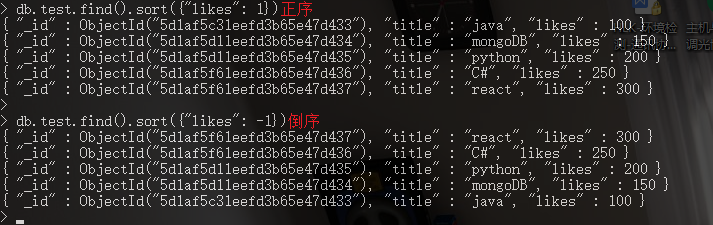
8.1. 排序
// ***** KEY: 排序的字段; SORT: 排序的规则 [1: 正序; -1: 倒序].
db.COLLECTION_NAME.find({}).sort({KEY: SORT})
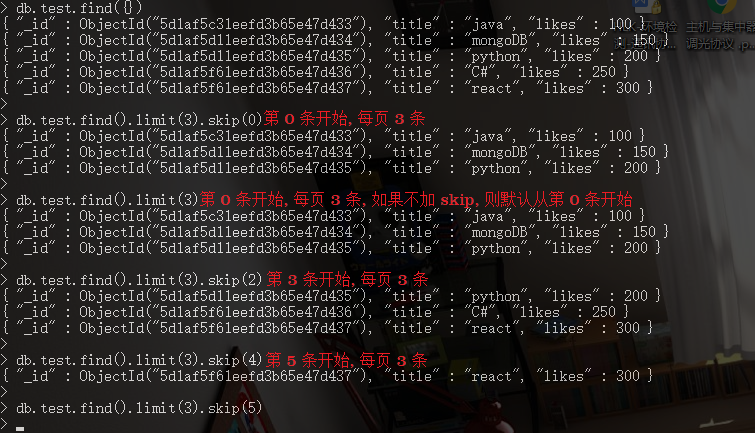
8.2. 分页
// ***** NUM1: 读取的记录条数; NUM2: 跳过的记录条数.
db.COLLECTION_NAME.find().limit(NUM1).skip(NUM2)
8.3. 排序和分页
// ***** 注: skip & limilt & sort 三个放在一起执行的时候,执行的顺序是先 sort > skip > limit
db.COLLECTION_NAME.find().sort({KEY: SORT}).limit(NUM1).skip(NUM2)

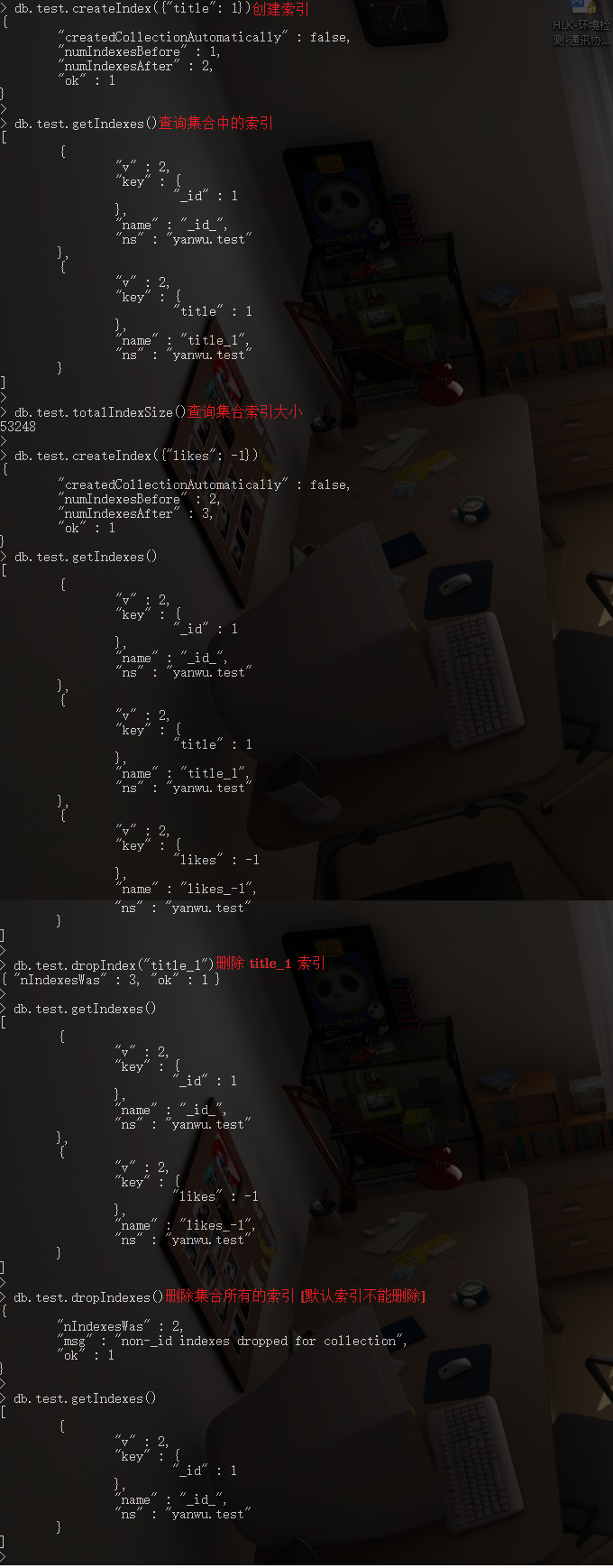
9. 索引
9.1. 创建索引
// ----- keys: 想要创建索引的字段, 1为升序创建索引, -1为降序创建索引
db.COLLECTION_NAME.createIndex(keys, [options])
9.2. 查看集合索引
// ----- 查看集合索引
db.COLLECTION_NAME.getIndexes()
// ----- 查看集合索引大小
db.COLLECTION_NAME.totalIndexSize()
9.3. 删除集合索引
// ----- 根据索引名称删除指定索引
db.COLLECTION_NAME.dropIndex(INDEX_NAME)
// ----- 删除集合所有的索引 (默认索引不能删除)
db.COLLECTION_NAME.dropIndexes()
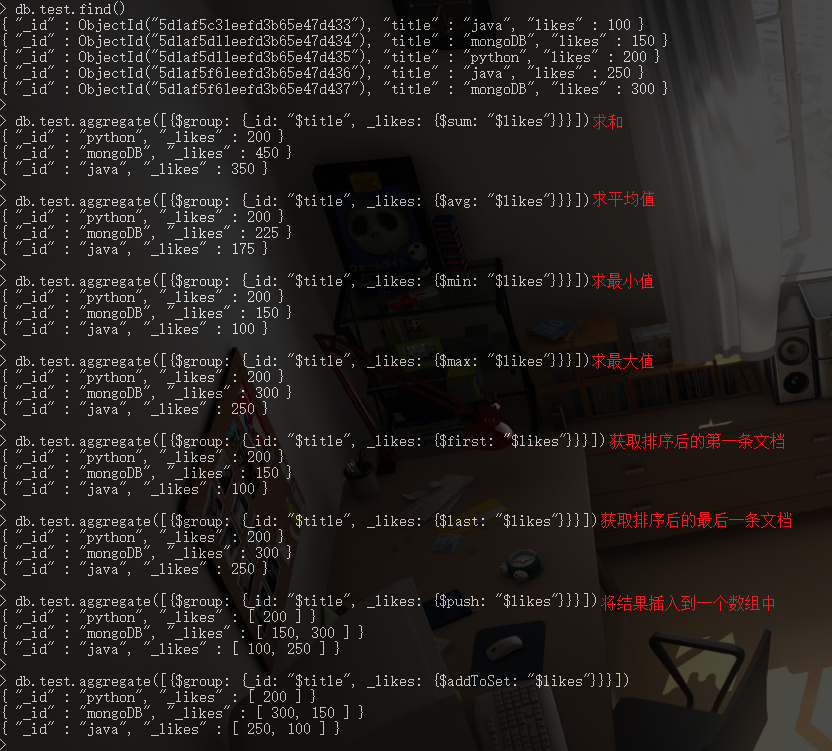
10. 函数 [聚合]
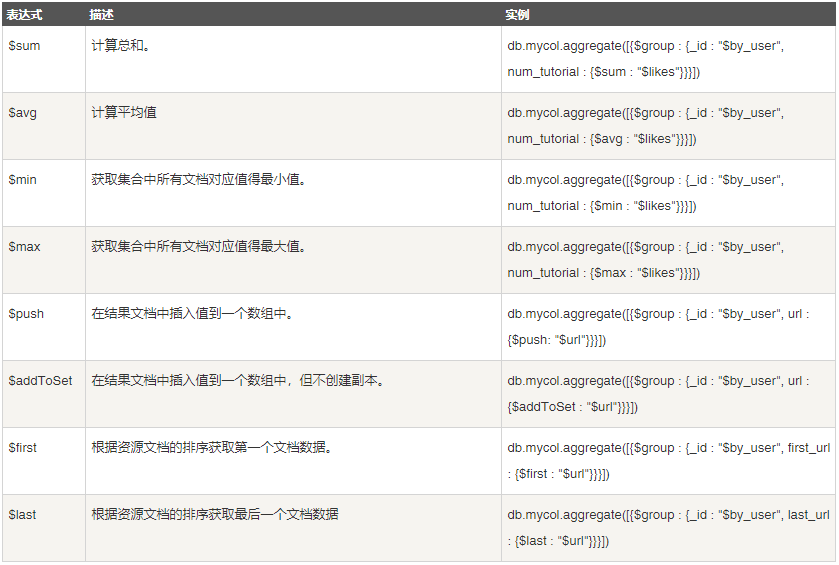
10.1. 求和
// ----- KEY1: 集合中文档分组的字段; KEY2: 求和的字段.
db.COLLECTION_NAME.aggregate([{$group: {_id: "$KEY1", _likes: {$sum: "$KEY2"}}}])
10.2. 求平均值
// ----- KEY1: 集合中文档分组的字段; KEY2: 求平均值的字段.
db.COLLECTION_NAME.aggregate([{$group: {_id: "$KEY1", _likes: {$avg: "$KEY2"}}}])
10.3. 求最小值
// ----- KEY1: 集合中文档分组的字段; KEY2: 求最小的字段.
db.COLLECTION_NAME.aggregate([{$group: {_id: "$KEY1", _likes: {$min: "$KEY2"}}}])
10.4. 求最大值
// ----- KEY1: 集合中文档分组的字段; KEY2: 求最大值的字段.
db.COLLECTION_NAME.aggregate([{$group: {_id: "$KEY1", _likes: {$max: "$KEY2"}}}])
10.5. 获取排序后的第一个文档
// ----- KEY1: 集合中文档分组的字段; KEY2: 排序的字段.
db.COLLECTION_NAME.aggregate([{$group: {_id: "$KEY1", _likes: {$first: "$KEY2"}}}])
10.6. 获取排序后的最后一个文档
// ----- KEY1: 集合中文档分组的字段; KEY2: 排序的字段.
db.COLLECTION_NAME.aggregate([{$group: {_id: "$KEY1", _likes: {$last: "$KEY2"}}}])
MongoDB 基础API使用的更多相关文章
- mongodb基础系列——数据库查询数据返回前台JSP(一)
经过一段时间停顿,终于提笔来重新整理mongodb基础系列博客了. 同时也很抱歉,由于各种原因,没有及时整理出,今天做了一个demo,来演示,mongodb数据库查询的数据在JSP显示问题. 做了一个 ...
- windows下mongodb基础玩法系列二CURD附加一
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
- MongoDB C API
一.编译mongodb c driver: 编译完成之后在c:\mongo-c-driver目录下有bin.include.lib三个文件夹,分别包含所需的dll..h文件.lib. 在自己的项目中引 ...
- mongodb基础用法
安装部分 mongodb配置方法 mongodb的安装目录 C:\MongoDB\Server\3.2\bin 创建以下目录 c:\mongo\log c:\mongo\db 创建mongodb的配置 ...
- MongoDB基础知识 02
MongoDB基础知识 02 6 数据类型 6.1 null : 表示空值或者不存在的字段 {"x":null} 6.2 布尔型 : 布尔类型只有两个值true和false {&q ...
- MongoDB基础知识 01
MongoDB基础知识 1. 文档 文档是MongoDB中的数据的基本单元,类似于关系型数据库管理系统的行. 文档是键值对的一个有序集.通常包含一个或者多个键值对. 例如: {”greeting& ...
- Linux高性能server编程——Linux网络基础API及应用
Linux网络编程基础API 具体介绍了socket地址意义极其API,在介绍数据读写API部分引入一个有关带外数据发送和接收的程序,最后还介绍了其它一些辅助API. socket地址API 主 ...
- 服务器编程入门(4)Linux网络编程基础API
问题聚焦: 这节介绍的不仅是网络编程的几个API 更重要的是,探讨了Linux网络编程基础API与内核中TCP/IP协议族之间的关系. 这节主要介绍三个方面的内容:套接字( ...
- mongodb c api编译
1. autoconf-latest.tar.gz http://ftp.gnu.org/gnu/autoconf/ tar xzvf autoconf-latest.tar.gz ./configu ...
随机推荐
- php工作中常用到的linux命令
压缩并指定目录举例:zip -r /home/kms/kms.zip /home/kms/server/kms 解压并指定目录举例:unzip /home/kms/kms.zip -d /home/k ...
- webstorm格式化代码快捷键
ctrl+alt+L 把网易云音乐的快捷键关了就可以了
- 20190927 - 28 后觉 「雅礼Day3 - 4」
我再不开$C++11$编译我就从三楼跳下去$$\text{%%%lsc}$$ Day3 -lm -O2 -std=c++ Before $Day3$? 全是$Subtask$? $\frac{1}{4 ...
- python 字符串的处理技巧--join
>>> '+'.join('1234')'1+2+3+4'>>> '+'.join(a for a in '1234')'1+2+3+4'>>> ...
- Leetcode16.3Sum Closest最接近的三数之和
给定一个包括 n 个整数的数组 nums 和 一个目标值 target.找出 nums 中的三个整数,使得它们的和与 target 最接近.返回这三个数的和.假定每组输入只存在唯一答案. 例如,给定数 ...
- simple 单例
Message* Message::m_pInstance = ;//类外初始 Message::Message() { } Message::~Message() { ) { delete Inst ...
- web前端学习(二)html学习笔记部分(7)--web存储2
1.2.20 web存储 1.2.20.1 Web存储-客户端存储数据新方法 1.两种方式 1)localStorage - 没有时间限制的数据存储 2)针对一个sessionStorage - ...
- web前端学习(二)html学习笔记部分(4)--audio和video文件播放
1.2.10 html5音频 1.2.10.1 HTML5音频播放 本课主要讲解HTML5播放音频 <!--<button onclick="clickA"> ...
- OpenLayers使用弹出窗口
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <html> <head ...
- Freckles (最小生成树)
#include<iostream> #include<cstring> #include<stdio.h> #include<queue> #incl ...