Apache Kafka(六)- High Throughput Producer
High Throughput Producer
在有大量消息需要发送的情况下,默认的Kafka Producer配置可能无法达到一个可观的的吞吐。在这种情况下,我们可以考虑调整两个方面,以提高Producer 的吞吐。分别为消息压缩(message compression),以及消息批量发送(batching)。
1. Message Compression
Producer一般发送的数据都是文本数据,例如JSON ,但是这类数据的问题在于:数据量会较大,消耗较多的传输带宽。这种情况下,有必要对Producer的数据进行压缩。
- 数据压缩可以仅在Producer level完成即可,并不需要任何Broker或Consumer端的配置更改
- 控制压缩的参数为 compression.type,可选值为 none(默认),gzip,lz4,snappy
- 发送给Kafka的消息的数据量越大,使用Compression的收益也就越大
- 有博主针对压缩性能进行过测试,详细内容可以参考以下文档:https://blog.cloudflare.com/squeezing-the-firehose/
一般Producer在向kafka传输消息时会用到Producer Batch,将多条消息以一个batch的方式传输。对一个batch的消息进行压缩,然后传输给Kafka,会大大减少消息的传输、使用的网络带宽,以及减少latency:

总的来说,使用compressed batch的好处有:
- 更小的producer request size(压缩比率最高可以达 4x)
- 使用更少的网络带宽 => 也就是更小的延迟
- 更高的吞吐
- 在Kafka端更优的磁盘使用率(存储在磁盘上的消息数据量会更小)
同时也会有缺点:
- Producers需要一些CPU资源用于压缩
- Consumers也需要一些CPU资源用于解压缩
一般场景下,可以尝试使用 snappy 或是 lz4 作为压缩算法,它们有较好的速度以及压缩率。其他算法例如gzip,压缩率较高,但是速度较慢。对于各类不同的压缩算法,一般都是在压缩率与解压缩(以及压缩)速度这两者间做权衡,可根据实际场景进一步做测试并选择适用的压缩算法。最好的方式是:对应用场景下的数据,比较所有的压缩算法的性能,从中选出最优的压缩算法,再应用到生产。
在一个应用场景下,若是需要达到一个较高的吞吐,压缩是必须要考虑在内的。另一方面,我们也要考虑message batch。通过调整linger.ms 以及 batch.size 控制batch的大小,结合压缩,使应用达到更高的吞吐 。
2. Producer Batching
在默认情况下,Kafka Producer会尝试尽可能的发送records。之前我们介绍过一个参数max.in.flight.requests.per.connection,它表示的含义是:
- 最多同时会有5个in flight 连接,也就是说在同一时刻,最多仅有5条message会相互独立地发送
- 在这之后,如果有更多的messages需要被发送,而其他的连接均为in flight。则Kafka会开始将这些消息batching,并进行等待。直到返回了一个ack后,kafka会将这些消息一次性传输出去。更重要的是:此次传输仅为Producer的一个request
显而易见,batching可以让Kafka增大throughput,同时保有较低的延时。此功能也不需要做任何特殊配置,Kafka默认会使用此机制传输消息。另一方面,Batches可以有更高的压缩率,并因此达到更高的效率。
控制batch行为的参数有两个,分别为linger.ms、batch.size。
首先介绍linger.ms:
- Linger.ms:在发送一个batch出去前,一个Producer等待的毫秒数。默认为0,也就是说Kafka会立即发送一个batch
- 若是引入一些延迟(例如linger.ms=5),则消息以batch形式被发送的概率会增加
- 所以在引入了一点延迟成本后,我们可以增加producer的吞吐以及压缩性能,让producer更高效
- 如果一个batch在linger.ms时间到达之前就满了(由batch.size控制),则这个batch会被立即发送到Kafka。所以不需要担心过长的等待时间。
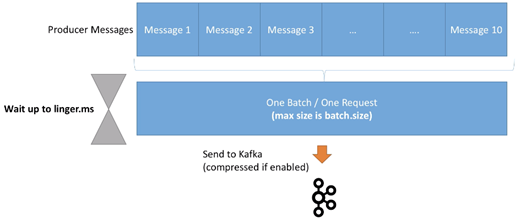
然后是batch.size:
- batch.size:在一个batch中,最多能容纳的字节数。默认为16KB
- 在大多数情况下,增加此参数到32KB或64KB可以有效提高压缩、吞吐、以及请求的性能
- 任何超过此batch size大小的消息不会被batch
- batch的分配基于partition数目,所以确保不要设置太高的值,以防止使用过多内存
- 我们可以使用Kafka Producer Metrics监控average batch size 指标
3. High Throughput Producer 示例
基于之前的Java例子,我们会继续添加snappy 压缩算法到我们的producer中。对于基于文本的数据(例如日志文件或是JSON文件)来说,snappy在CPU与压缩率之间有均有权衡,相对来说是一个较好的压缩算法选择。我们也会将batch.size 增加到 32KB,并通过linger.ms 引入一个较小的延时(20ms)。
配置参数如下:
// high throughput producer at the expense of a lit bit latency and CPU usage
properties.setProperty(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "20");
properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, Integer.toString(32*1024)); // 32 KB batch size
在配置以上参数后,发送给Kafka的消息即为压缩后的消息。不过在Consumer中,不需要做任何配置即可正常读取并将这些消息转回文本。
4. Max.block.ms & buffer.memory
如果一个Producer 发送消息的速度超出了broker可以处理的速度,则records会被buffer在内存中:
- buffer.memory = 33554432(32MB)即为send buffer的默认大小
- 此buffer会随着时间的增加而填满,并随着broker吞吐增加后,buffer数据量减少
如果buffer满了(所有32MB都被占用),则 .send() 方法会被阻塞(也就是说,Producer不会再生产更多数据,不会立即return)并等待。此等待时间由max.block.ms=60000控制,表示的是:在等待多长时间后,若存在以下任一情况,则抛出异常:
- Producer 的send buffer沾满
- Broker不接收任何新数据
- 60s时间已过
如果出现这种类型的异常,则一般说明brokers 宕机,或是负载过高,导致无法响应请求。
Apache Kafka(六)- High Throughput Producer的更多相关文章
- apache kafka源码分析-Producer分析---转载
原文地址:http://www.aboutyun.com/thread-9938-1-1.html 问题导读1.Kafka提供了Producer类作为java producer的api,此类有几种发送 ...
- Apache Kafka Producer For Beginners
在我们上一篇Kafka教程中,我们讨论了Kafka Cluster.今天,我们将通过示例讨论Kafka Producer.此外,我们将看到KafkaProducer API和Producer API. ...
- Exception in thread "main" java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Expiring 1 record(s) for topic_test_1219-2: 30010 ms has passed since batch creatio
代码如下 public static void producer1() throws ExecutionException, InterruptedException { Properties pro ...
- 实践部署与使用apache kafka框架技术博文资料汇总
前一篇Kafka框架设计来自英文原文(Kafka Architecture Design)的翻译及整理文章,非常有借鉴性,本文是从一个企业使用Kafka框架的角度来记录及整理的Kafka框架的技术资料 ...
- 【Apache Kafka】二、Kafka安装及简单示例
(一)Apache Kafka安装 1.安装环境与前提条件 安装环境:Ubuntu16.04 前提条件: ubuntu系统下安装好jdk 1.8以上版本,正确配置环境变量 ubuntu系统下安 ...
- Error when sending message to topic test with key: null, value: 2 bytes with error: (org.apache.kafka.clients.producer.internals.ErrorLoggingCallback)
windows下使用kafka遇到这个问题: Error when sending message to topic test with key: null, value: 2 bytes with ...
- Kafka遇到30042ms has passed since batch creation plus linger time at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:94)
问题描述: 运行生产者线程的时候显示如下错误信息: Expiring 1 record(s) for XXX-0: 30042 ms has passed since batch creation p ...
- apache kafka系列之Producer处理逻辑
最近研究producer的负载均衡策略,,,,我在librdkafka里边用代码实现了partition 值的轮询方法,,,但是在现场验证时,他的负载均衡不起作用,,,所以来找找原因: 下文是一篇描 ...
- Apache Kafka(五)- Safe Kafka Producer
Kafka Safe Producer 在应用Kafka的场景中,需要考虑到在异常发生时(如网络异常),被发送的消息有可能会出现丢失.乱序.以及重复消息. 对于这些情况,我们可以创建一个“safe p ...
随机推荐
- ECMAScript基本对象——RegExp 正则表达式对象
含义:定义字符串的组成规则 使用: 1.定义单个字符:[ ] [a] 表示有一个字符是 小写的a [ab] 表示有一个字符是 小写的a或者b [a-z] 表示有一个字符是 小写的a到z [a-z ...
- thinkphp 5.0 后台数据修改
html代码 <table class="easyui-datagrid" data-options="singleSelect:true,collapsible: ...
- 高数(求x的n次方的导数)
- [HNOI2009]图的同构记数
题意 在所以置换下,本质不同的\(n\)阶图个数 做法 可以假想成\(K_n\),边有黑白两色,黑边存在于原图,白边存在于补图 由于\(n\le 60\),可以手算出拆分数不大,所以我们爆搜置换群 对 ...
- eXosip和osip详解
文档 可以查看exosip osip的在线文档 http://www.antisip.com/doc/ 在线文档 一般先看mainpage 会有库的一个整体说明. 其次看看 modules 会有一些使 ...
- Codeforces 1303E. Erase Subsequences 代码(dp 字符串压缩一维状态优化)
https://codeforces.com/contest/1303/problem/E #include<bits/stdc++.h> using namespace std; ; i ...
- 下载 Microsoft JDBC driver 7.2 for SQL Server
下载 Microsoft JDBC driver 7.2 for SQL Server:https://www.microsoft.com/zh-cn/download/confirmation.as ...
- LaTeX技巧010:LaTtex中如何给每个句子加序号?
效果图: 代码: \documentclass{article} \newcounter{sentence} \renewcommand\thesentence{\textsuperscript{\a ...
- linux 安装java jdk
1.检查一下系统中的jdk版本 [root@localhost software]# java -version 显示: openjdk version "1.8.0_102" O ...
- 在电脑上用chrome浏览器调试android手机里的网页代码时,无法看到本地加载的js文件
在需要调试的js文件最顶部加上代码就可以看到了: console.log('haha'); debugger;