Benchmark of Large-scale Unconstrained Face Recognition-blufr 算法的理解
|
Many efforts have been made in recent years to tackle the unconstrained face recognition challenge. For the benchmark of this challenge, the Labeled Faces in the Wild (LFW) [2] database has been widely used. However, the standard LFW protocol is very limited:
Thereby we develop a new benchmark protocol to fully exploit all the 13,233 LFW face images for large-scale unconstrained face recognition evaluation. The new benchmark protocol, called BLUFR, contains both verification and open-set identification scenarios, with a focus at low FARs. There are 10 trials of experiments, with each trial containing about 156,915 genuine matching scores and 46,960,863 impostor matching scores on average for performance evaluation. We provide a benchmark tool here to further advance research in this field. For more information, please read our IJCB paper and the README files in the benchmark tookit. |
||||||||||||||||||||||||||||||||||||||||||||||
|
The benchmark tookit:BLUFR.zipThe basic feature files: lfw.mat frgc.matOther available features: HighDimLBP LE --Thanks to Dong Chen |
||||||||||||||||||||||||||||||||||||||||||||||
|
Shengcai Liao, scliao@nlpr.ia.ac.cn National Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences. |
||||||||||||||||||||||||||||||||||||||||||||||
Notes: (1) Algorithms are ranked by VR @FAR=0.1%. (2) Performances are measured in (μ - σ) of 10 trials. (3) The citations indicate where the results are from. Download the result files and demo code for performance plot: Results.zip Please contribute your algorithm's performance so that we can keep a track of the state of the art for large-scale unconstrained face recognition. |
||||||||||||||||||||||||||||||||||||||||||||||
|
[1] Shengcai Liao, Zhen Lei, Dong Yi, Stan Z. Li, "A Benchmark Study of Large-scale Unconstrained Face Recognition." In IAPR/IEEE International Joint Conference on Biometrics, Sep. 29 - Oct. 2, Clearwater, Florida, USA, 2014. [pdf] [slides] [2] G. B. Huang, M. Ramesh, T. Berg, and E. Learned-Miller. Labeled faces in the wild: A database for studying face recognition in unconstrained environments. Technical Report 07-49, University of Massachusetts, Amherst, October 2007. https://blog.csdn.net/keyanxiaocaicai/article/details/51005221 现在已知的算法是lfw 有6000对,3000 对正样本,3000 对负样本,利用十重交叉验证的方式来计算识别率。 虽然在现在的lfw 数据集上已经可以达到99% 但是并不能保证在真实的场景下有比较好的性能。 作者提出了一种新的方法,主要是扩展了原来基础上只有6000 对正负样本的计算。 现在作者把lfw 数据集分成一部分训练集,一部分测试集,训练集的样本平均在3400 多张左右,训练集的选取和测试集的选取都基于一些规则(比如要求训练集有1500 个人,其中包含至少437人有2个以上的人脸,因为总共有5749 个人,所以测试集包含其余的(5729-1500)个人,大概是1243 个人有2个以上的人脸,经过测试里面含有2个人以上的人是 1680个,跟paper 里面讲的是吻合的)。 训练集对于我们的作用目前在我看来是用来求主成分分析的W 矩阵,本文要求的时候降维之后为400. 作者把原来的verfication 的任务扩展为 更接近于实际场景的verfication +DIR verfication 任务是只校验两个人脸是不是一个人。 以第一轮为例: 作者训练部分的样本为:2952 那么相应的测试部分的样本为(13233-2952)=10281 对于测试样本经过pca 之后是降低维度之后的样本,先求norm,(如果不求norm 会对结果有什么影响) 10281 个样本之间两两求相似度.(作者采用的trick是求一个下三角的方式) 这样得到是所有10281 之间样本的相似度。 我们还可以得到这些样本之间那些是一类的,那些不是一类的 我们可以得到不是一个人的总的个数和他们的计算分值。(10281*10281-10281)/2 所有对的个数 其中负样本对的个数为:52612506 正样本对的个数为:231834 我们把这些负样本的score 从大往小排,根据: thresholds(~isZeroFAR & ~isOneFAR) = impScore( falseAlarms(~isZeroFAR & ~isOneFAR) ); 这样我们得到每个falseAlarms 点处的阈值: FAR false accept ratio (是将其他人看做你的概率) 计算方法是:非同人分数>T/非同人比较次数 我的理解为:因为负样本为52612506 个,如果FAR 为0.0001 那么允许错分的样本数目为 52612506*0.0001=5261.2506个,那么由于负样本的score 是从上往下排的,所以只允许上面得分高的被错分掉, 那么阈值要设置为0.8293 那么我们可以计算 VR 就是正样本里面score>0.8293 的值, 与全部正样本的比值。 对DIR 我现在的理解为: DIR 是把测试集分成三部分:一部分是gallay set G(only one image per subject was selected),由于测试集包含1242 个人, 那么除了gallay 以外的其他的人脸组成PG, 其他的人脸组成PN, 平均下来,PG 大概有4350 张图片,PN 有3249 个人的4357 张图片。(互斥的关系) 以第五轮为例: PG 有4417 个, PN 有4053 个样本 FAR 的选取方式跟VR 的方式是一样的。阈值的选取方式。 对于PN 里面的样本,都是负样本,那么我们在每一行找一个与gallay 里面的图片相似度最高的得到一个列向量。 把这些元素降序排列, 对于face verification 这个任务,我们采用ROC 曲线来刻画。 对于DIR 这个任务,采用CMC 曲线来刻画 |
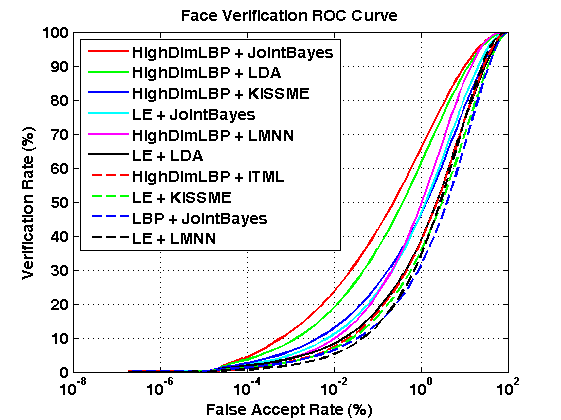
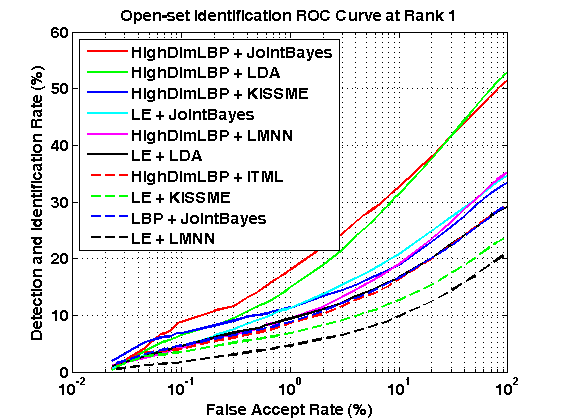

Benchmark of Large-scale Unconstrained Face Recognition-blufr 算法的理解的更多相关文章
- face recognition[翻译][深度学习理解人脸]
本文译自<Deep learning for understanding faces: Machines may be just as good, or better, than humans& ...
- 大规模视觉识别挑战赛ILSVRC2015各团队结果和方法 Large Scale Visual Recognition Challenge 2015
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Legend: Yellow background = winner in thi ...
- Computer Vision_33_SIFT:Improving Bag-of-Features for Large Scale Image Search——2010
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- 论文笔记之:Large Scale Distributed Semi-Supervised Learning Using Streaming Approximation
Large Scale Distributed Semi-Supervised Learning Using Streaming Approximation Google 2016.10.06 官方 ...
- 快速高分辨率图像的立体匹配方法Effective large scale stereo matching
<Effective large scale stereo matching> In this paper we propose a novel approach to binocular ...
- Introducing DataFrames in Apache Spark for Large Scale Data Science(中英双语)
文章标题 Introducing DataFrames in Apache Spark for Large Scale Data Science 一个用于大规模数据科学的API——DataFrame ...
- Lessons learned developing a practical large scale machine learning system
原文:http://googleresearch.blogspot.jp/2010/04/lessons-learned-developing-practical.html Lessons learn ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
Lecture17 Large Scale Machine Learning大规模机器学习 17.1 大型数据集的学习 Learning With Large Datasets 如果有一个低方差的模型 ...
- [C12] 大规模机器学习(Large Scale Machine Learning)
大规模机器学习(Large Scale Machine Learning) 大型数据集的学习(Learning With Large Datasets) 如果你回顾一下最近5年或10年的机器学习历史. ...
随机推荐
- mysql优化1:建表原则
建表三大原则: 定长和变长分离 常用字段和不常用字段分离 使用冗余字段或冗余表 1.定长与变长分离 如 id int,占4个字节,char(4)占4个字符长度,也是定长,time 即每一个单元值占的字 ...
- 剑指offer——58数组中数值和下标相等的元素
题目三: 数组中数值和下标相等的元素. 假设一个单调递增的数组里的每个元素都是整数并且是唯一的.请编程实现一个函数,找出数组中任意一个数值等于其下标的元素.例如,在数组{-3,-1,1,3,5}中,数 ...
- npm和cnpm的安装(window)
一:安装node.js 1.进入https://nodejs.org/en/中下载自己电脑相对应的node.js. 2.将下载下来的node.js进行安装. 3.利用管理员身份打开cmd,在里面输入n ...
- vim + ctag + Taglist (转)
一.ctag 当然,第一步就是要下载它!一条命令搞定: $sudo apt-get install ctags 如果不幸提示找不到软件包ctags,首先你也许应该update一下你的软件源,还不行的话 ...
- 牛客练习赛48 D 小w的基站网络
链接:https://ac.nowcoder.com/acm/contest/923/D来源:牛客网 时间限制:C/C++ 2秒,其他语言4秒 空间限制:C/C++ 262144K,其他语言52428 ...
- python学习10—迭代器、三元表达式与生成器
python学习10—迭代器.三元表达式与生成器 1. 迭代器协议 定义:对象必须提供一个next方法,执行该方法或者返回迭代中的下一项,或者返回一个StopIteration异常,以终止迭代(只能往 ...
- opencv——常见的操作
一 图像阈值处理 准备一张灰度图像 阈值处理通常是设定一个阈值,让图片的所有像素点的值与其比较做出一系列的操作. 在opencv常用的阈值处理函数有五种,分别是THRESH_BINARY.THRESH ...
- 组合,模板,bolck块
如果前面和后面的变量名相同,则后面的变量名会覆盖前面的变量名 模板可以多次使用,只需要将is指定template的name,就可以重复使用该模板,只需要将不同的item值赋值给data就可以实现. 可 ...
- C#中Json和类的相互转化
//在NuGet里下载安装 Newtonsoft.Json,再引用. using Newtonsoft.Json; //写一个用户类 public class UserDataInfo { publi ...
- windows10,nodejs安装步骤
系统: windows10 1.下载: https://nodejs.org/en/ 2.下载最新版本,根据你的系统选择32位或者64位: 3.建议选择源码源码安装,不选择编译后的安装 如: 4.进行 ...