Explain执行计划与索引优化实践
一、何为explain执行计划?
使用explain关键字可以模拟优化器执行SQL语句,从而知道MySQL是如何使用索引来处理你的SQL查询语句以及连接表,可以分析查询语句或是结构的性能瓶颈,帮助我们选择更好的索引和写出更优化的查询语句。(说白了,就是优化SQL的工具)
二、如何使用explain?
在你的SQL查询语句前加上 explain 即可,如explain select * from table,MySQL会在查询上设置一个标记,执行查询时,会返回执行计划的信息,而不是执行这条SQL(如果 from 中包含子查询,仍会执行该子查询,将结果放入临时表)。
三、使用explain的例子
需要使用三张表,分别为 actor 演员表,film 电影表,film_actor 电影-演员关联表。
CREATE TABLE `actor` (
`id` int(11) NOT NULL COMMENT '主键id',
`name` varchar(45) DEFAULT NULL COMMENT '演员名称',
`update_time` datetime DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `actor` (`id`, `name`, `update_time`) values('1','a','2020-02-11 22:56:00');
insert into `actor` (`id`, `name`, `update_time`) values('2','b','2020-02-11 22:56:00');
insert into `actor` (`id`, `name`, `update_time`) values('3','c','2020-02-11 22:56:00');
CREATE TABLE `film` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`name` varchar(10) DEFAULT NULL COMMENT '电影名称',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
insert into `film` (`id`, `name`) values('3','film0');
insert into `film` (`id`, `name`) values('1','film1');
insert into `film` (`id`, `name`) values('2','film2');
CREATE TABLE `film_actor` (
`id` int(11) NOT NULL COMMENT '主键id',
`film_id` int(11) NOT NULL COMMENT '电影id',
`actor_id` int(11) NOT NULL COMMENT '演员id',
`remark` varchar(255) DEFAULT NULL COMMENT '备注',
PRIMARY KEY (`id`),
KEY `idx_film_actor_id` (`film_id`,`actor_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `film_actor` (`id`, `film_id`, `actor_id`, `remark`) values('1','1','1',NULL);
insert into `film_actor` (`id`, `film_id`, `actor_id`, `remark`) values('2','1','2',NULL);
insert into `film_actor` (`id`, `film_id`, `actor_id`, `remark`) values('3','2','1',NULL);
执行完以上SQL后,三张表数据对应如下:

下面展示explain中每个列的信息:
1、id列
id列的编号是select语句的序列号,有几个 select 就有几个id,并且id的序号是按 select 出现的顺序而增长的(id越大,对应的select语句越先执行,如果id相等,则从上往下执行,id为NULL最后执行)。
MySQL将select查询分为简单查询(SIMPLE)和复杂查询(PRIMARY)。
复杂查询分为三类:简单子查询、派生表(from语句中的子查询)、union查询。
(1)简单子查询
执行SQL语句:EXPLAIN SELECT (SELECT 1 FROM actor LIMIT 1) FROM film

(2)from子句中的子查询
执行SQL语句:EXPLAIN SELECT id FROM (SELECT id FROM film) AS der

分析:这个查询执行时有个临时表别名为der,外部select查询引用了这个临时表。
(3)union查询
执行SQL语句:EXPLAIN SELECT 1 UNION ALL SELECT 1

分析:union结果总是放在一个匿名临时表中,临时表不在SQL中出现,因此它的id为NULL。(不推荐使用union,性能不高)
2、select_type列
这一列表示对应行是简单还是复杂查询,如果是复杂查询,又是上述三种复杂查询中的哪一种。
(1)SIMPLE:简单查询。查询不包含子查询和union。
执行SQL语句:EXPLAIN SELECT * FROM film WHERE id=2

(2)PRIMARY:复杂查询中最外层的select。
(3)SUBQUERY:包含在select中的子查询(不在from子句中)。
(4)DERIVED:包含在from子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(DERIVED的英文含义)。
执行SQL语句:EXPLAIN SELECT (SELECT 1 FROM actor WHERE id=1) FROM (SELECT * FROM film WHERE id=1) der

(5)UNION:在union中的第二个和随后的select。
(6)UNION RESULT:从union临时表检索结果的select。
执行SQL语句:EXPLAIN SELECT 1 UNION ALL SELECT 1

3、table列
这一列表示explain的一行正在访问哪个表。
当from子句中有子查询时,table列是<DERIVED N>格式,表示当前查询依赖id=N的查询,于是先执行id=N的查询。
当有union时,UNION RESULT的table列的值为<union 1,2>,1和2表示参与union的select行id。
4、type列
(温馨提示:以下部分理论有可能解释完还是懵逼,没关系,继续往下看,有实践例子)
这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据记录的大概范围。
SQL语句查询效率从最优到最差依次为:system > const > eq_ref > ref > range > index > ALL。
一般来说,得保证查询达到range级别,最好达到ref。
NULL:MySQL能够在SQL语句执行之前(即优化阶段)分析分解查询语句,在执行阶段用不着再访问表或索引。例如:在索引列中选取最小值,可以单独查找索引来完成,不需要在执行时访问表,出现的频率不高。
const,system:MySQL能够对查询的某部分进行优化并将其转化成一个常量(可以看show warnings的结果)。用于主键索引或唯一索引的所有列与常数比较时,表最多有一个匹配行,读取1次,速度比较快。system是const的特例,表里只有一条记录匹配时为system。
执行SQL语句:EXPLAIN EXTENDED SELECT * FROM (SELECT * FROM film WHERE id=1) tmp

分析:上面的子查询SELECT * FROM film WHERE id = 1语句where后面id使用的是主键索引查询,主键是唯一的,所以查询结果一定是只有一条记录,对于明确知道结果集只有一条记录的查询,它的type为const类型,性能已经非常高了;而第一个select复杂查询的表只有一条记录,所以结果也肯定只有一条记录(第二个select子查询之前表中可能是多条记录),这种特例它的type为system类型,性能最高。
执行SQL语句:EXPLAIN EXTENDED SELECT * FROM (SELECT * FROM film WHERE id=1) tmp; SHOW WARNINGS;

分析:用explain extended查看执行计划会比explain多一列filtered,该列给出一个百分比的值,这个值和rows列一起使用,可以估计出那些将要和explain中的前一个表进行连接的行的数目,前一个表就是指explain的id列的值比当前表的id小的表。explain extended还可以搭配show warnings一起使用,它可以给出一个优化建议,真正执行时是执行优化建议的那条SQL,但是如果是很复杂的SQL,它优化出来的结果可能都没你原先的SQL性能高。
eq_ref:主键索引或唯一索引的所有部分被连接使用,最多只会返回一条符合条件的记录。这可能是在const之外最好的连接类型了,简单的select查询不会出现这种type。
执行SQL语句:EXPLAIN SELECT * FROM film_actor LEFT JOIN film ON film_actor.film_id=film.id

分析:有两条记录,说明有2次查询, id相等,则从上往下执行,说明第1条先执行查询film_actor表,第2条左连接查询film表。左连接film表并关联film.id,由于film.id是唯一索引,film表只能关联一行记录,所以第2条select的type为eq_ref。
ref:相比eq_ref,不使用唯一索引,而是使用普通索引或者唯一索引的前缀部分,索引要和某个值相比较,可能会找到多条符合条件的记录。
① 简单select查询,name是普通索引(非唯一索引)
执行SQL语句:EXPLAIN SELECT * FROM film WHERE NAME="film1"

② 关联表查询,idx_film_actor_id是film_id和actor_id的联合索引,这里使用了film_actor的索引左边前缀部分 film_id。
执行SQL语句:EXPLAIN SELECT * FROM film LEFT JOIN film_actor ON film.id=film_actor.film_id

range:范围扫描通常出现在in(),between,>,<,>=等操作中。使用一个索引来检索给定范围的行。
执行SQL语句:EXPLAIN SELECT * FROM actor WHERE id>1

index: 扫描全表索引,这通常会比ALL快一些。(index是从索引中读取的,而ALL是从硬盘中读取)
执行SQL语句:EXPLAIN SELECT * FROM film;(film表所有字段都加了索引)

ALL: 即全表扫描,意味着MySQL需要从头到尾去查找所需要的行(不走索引)。通常情况下这需要增加索引来优化了。
执行SQL语句:EXPLAIN SELECT * FROM actor;(actor表有一个字段没加索引)

5、possible_keys列
这一列显示查询可能使用哪些索引来查找。
explain时可能出现possible_key有列,而key显示NULL的情况,这种情况是因为表中数据不多,MySQL认为索引对此查询帮助不大,选择了全表查询。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查where子句是否可以创造一个适当的索引来提高查询性能,然后用explain查看效果。
6、key列
这一列显示MySQL实际采用哪个索引来优化对该表的访问。
如果没有使用索引,则该列是NULL。如果想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用force index、ignore index。
7、key_len列
这一列显示了MySQL在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
举例来说,film_actor表的联合索引idx_film_actor_id由film_id和actor_id两个int列组成,并且每个int是4字节。通过下面结果中的key_len=4可推断出只使用了第一个列flim_id来执行索引查找。
执行SQL语句:EXPLAIN SELECT * FROM film_actor WHERE film_id=2

key_len计算规则如下:
① 字符串
- char(n):n字节长度
- varchar(n):2字节存储字符串长度,如果是UTF-8,则长度为3n+2
② 数值类型
- tinyint:1字节
- smallint:2字节
- int:4字节
- bigint:8字节
③ 时间类型
- date:3字节
- timestamp:4字节
- datetime:8字节
④ 如果字段允许为NULL,需要1字节记录是否为NULL
8、ref列
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量)、字段名(例:film.id)。
9、rows列
这一列是MySQL估计要读取并检测的行数,注意这个不是结果集里的行数。
10、Extra列
这一列展示的是额外信息。常见的重要值如下:
Using index: 查询的列被索引覆盖,并且where筛选条件是索引的前导列(类似联合索引的最左前缀原则),是性能高的表现。一般是使用了覆盖索引(即索引包含了所有查询的字段)。对于InnoDB来说,如果是普通索引性能会有不少提高。
执行SQL语句:EXPLAIN SELECT film_id FROM film_actor WHERE film_id=1

Using where:查询的列不完全被索引覆盖,where筛选条件非索引的前导列。(不走索引,性能较低)
执行SQL语句:EXPLAIN SELECT * FROM actor WHERE name='a'

Using where; Using index:查询的列被索引覆盖,并且where筛选条件是索引列之一但不是索引的前导列,意味着无法直接通过索引来查找符合条件的数据。
执行SQL语句:EXPLAIN SELECT film_id FROM film_actor WHERE actor_id=1

NULL:查询的列未被索引覆盖,并且where筛选条件是索引的前导列,意味着用到了索引,但是部分字段未被索引覆盖,必须通过“回表”来实现,不是纯粹地用到了索引,也不是完全没用到索引。
执行SQL语句:EXPLAIN SELECT * FROM film_actor WHERE film_id=1

Using index condition:MySQL 5.6版本开始加入的新特性,与Using where类似,查询的列不完全被索引覆盖,where条件中是一个前导列的范围。
执行SQL语句:EXPLAIN SELECT * FROM film_actor WHERE film_id>1

Using temporary:MySQL需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先要想到用索引来优化。
① actor.name没有索引,此时创建了一张临时表来distinct。(distinct:去除查询结果中的重复记录)
执行SQL语句:EXPLAIN SELECT DISTINCT NAME FROM actor

② film.name建立了idx_name索引,此时查询时extra是Using index,没有用临时表。
执行SQL语句:EXPLAIN SELECT DISTINCT NAME FROM film

Using filesort:MySQL会对结果使用一个外部索引排序,而不是按照索引次序从表里读取行。此时MySQL会根据连接类型浏览所有符合条件的记录,并保存排序关键字和行指针,然后排序关键字并按顺序检索行信息。这种情况下一般也是要考虑使用索引来优化。
① actor.name未创建索引,会浏览actor整个表,保存排序关键字name和对应的id,然后排序name并检索行记录。
执行SQL语句:EXPLAIN SELECT * FROM actor ORDER BY name

② film.name建立了idx_name索引,此时查询时extra是Using index,因为索引底层数据结构已经是排好序的。
执行SQL语句:EXPLAIN SELECT * FROM film ORDER BY name

四、索引优化最佳实践
使用了 employees 员工表:
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`name` varchar(24) NOT NULL COMMENT '员工姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '员工年龄',
`position` varchar(20) NOT NULL COMMENT '员工职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
insert into `employees` (`id`, `name`, `age`, `position`, `hire_time`) values('1','LiLei','22','manager','2020-02-13 14:22:55');
insert into `employees` (`id`, `name`, `age`, `position`, `hire_time`) values('2','HanMeimei','23','dev','2020-02-13 14:22:57');
insert into `employees` (`id`, `name`, `age`, `position`, `hire_time`) values('3','Lucy','23','dev','2020-02-13 14:22:59');
1、全值匹配
执行SQL语句:EXPLAIN SELECT * FROM employees WHERE name='LiLei'

执行SQL语句:EXPLAIN SELECT * FROM employees WHERE name='LiLei' AND age=22

执行SQL语句:EXPLAIN SELECT * FROM employees WHERE name='LiLei' AND age=22 AND position='manager'

2、索引最左前缀原则
如果索引了多列,要遵循最左前缀原则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
提问:为什么联合索引要想命中索引必须采用最左前缀原则?(命中索引:即是否用到了索引)
以下索引优化规则很多都可以结合下面这张图思考,联合索引底层的索引数据结构图(B+树),索引的排序首先按10002排序,接着是Staff,最后才是1996-08-03,如果不先拿第一个字段10002去比较,根本没法比较,导致无法命中索引。
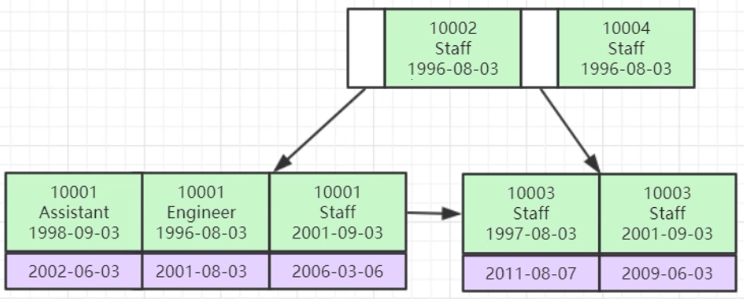
提问:以下SQL命中索引?
① EXPLAIN SELECT * FROM employees WHERE age = 22 AND position = 'manager';
② EXPLAIN SELECT * FROM employees WHERE position = 'manager';
③ EXPLAIN SELECT * FROM employees WHERE name = 'LiLei';
④ EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' AND position = 'manager';
分析:
①中的where条件后面age=22不是索引的最左前列,后面就不用看了,没有命中索引,②也是如此。

③中的name是索引idx_name_age_position的最左前列,命中索引。

④中的name命中索引,position没有命中索引,因为跳过索引中的age列,中间断了,age列还是需要全表扫描。

3、不要在索引列上做任何操作(如计算、函数、自动或手动类型转换),否则会导致索引失效而转向全表扫描
执行SQL语句:EXPLAIN SELECT * FROM employees WHERE LEFT(name, 3)='LiLei'

4、存储引擎不能使用索引中范围条件右边的列
执行SQL语句:EXPLAIN SELECT * FROM employees WHERE name='LiLei' AND age>22 AND position='manager'

分析:长度为78,name为74,age是int类型,所以为4,即只有name和age命中索引,position没有命中索引,因为它属于age范围条件右边的索引列。
5、尽量使用覆盖索引(只访问索引的查询,索引列包含查询列),减少 select * 语句
执行SQL语句:EXPLAIN SELECT name,age FROM employees WHERE name='LiLei'

执行SQL语句:EXPLAIN SELECT * FROM employees WHERE name='LiLei'

6、MySQL在使用不等于(!= 或者 <>)的时候无法使用索引,会导致全表扫描
执行SQL语句:EXPLAIN SELECT * FROM employees WHERE name != 'LiLei'

7、is null,is not null也无法使用索引
执行SQL语句:
EXPLAIN SELECT * FROM employees WHERE name IS NULL

8、like以通配符开头('$abc'),MySQL索引会失效导致全表扫描
执行SQL语句:EXPLAIN SELECT * FROM employees WHERE name LIKE '%Lei'

执行SQL语句:EXPLAIN SELECT * FROM employees WHERE name LIKE 'Lei%'

提问:如何解决like '%字符串%' 索引没有命中?
① 使用覆盖索引,查询字段必须是建立覆盖索引字段
执行SQL语句:EXPLAIN SELECT name,age,position FROM employees WHERE name LIKE '%Lei%'

② 当覆盖索引指向的字段是varchar(380)及以上的字段时,覆盖索引会失效!
9、字符串不加单引号,索引失效(内部会做一个字符串转换函数)
执行SQL语句:EXPLAIN SELECT * FROM employees WHERE name=1000

10、少用or或in,用它查询时,非主键字段的索引会失效,主键索引有时生效,有时不生效,跟数据量有关,具体还得看MySQL的查询优化结果
执行SQL语句:EXPLAIN SELECT * FROM employees WHERE name='LiLei' OR name='Hanmeimei'

总结:
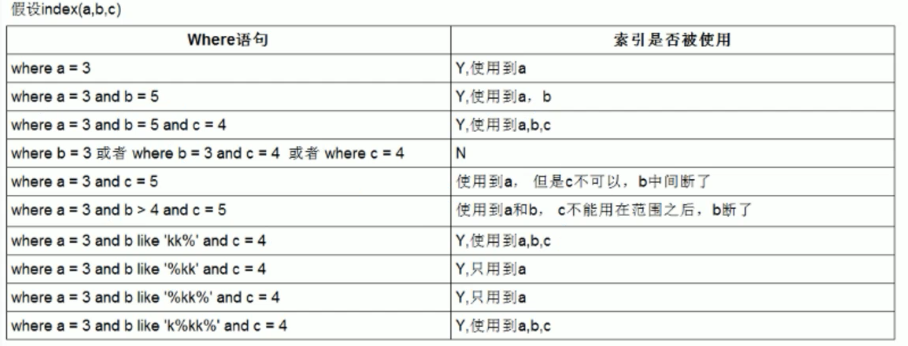
like KK% 相当于等于常量,%KK 和 %KK% 相当于范围。
Explain执行计划与索引优化实践的更多相关文章
- Explain 执行计划 和 SQL优化
Explain 介绍 在分析查询性能时,考虑EXPLAIN关键字同样很管用.EXPLAIN关键字一般放在SELECT查询语句的前面,用于描述MySQL如何执行查询操作.以及MySQL成功返回结果集需要 ...
- 【MySQL】MySQL的执行计划及索引优化
我们知道一般图书馆都会建书目索引,可以提高数据检索的效率,降低数据库的IO成本.MySQL在300万条记录左右性能开始逐渐下降,虽然官方文档说500~800w记录,所以大数据量建立索引是非常有必要的. ...
- Python进阶----索引原理,mysql常见的索引,索引的使用,索引的优化,不能命中索引的情况,explain执行计划,慢查询和慢日志, 多表联查优化
Python进阶----索引原理,mysql常见的索引,索引的使用,索引的优化,不能命中索引的情况,explain执行计划,慢查询和慢日志, 多表联查优化 一丶索引原理 什么是索引: 索引 ...
- MongoDB性能篇之创建索引,组合索引,唯一索引,删除索引和explain执行计划
这篇文章主要介绍了MongoDB性能篇之创建索引,组合索引,唯一索引,删除索引和explain执行计划的相关资料,需要的朋友可以参考下 一.索引 MongoDB 提供了多样性的索引支持,索引信息被保存 ...
- 不会看 Explain执行计划,劝你简历别写熟悉 SQL优化
昨天中午在食堂,和部门的技术大牛们坐在一桌吃饭,作为一个卑微技术渣仔默默的吃着饭,听大佬们高谈阔论,研究各种高端技术,我TM也想说话可实在插不上嘴. 聊着聊着突然说到他上午面试了一个工作6年的程序员, ...
- 网站优化—mysql explain执行计划
explain执行计划 简介MySQL调优: 先发现问题(慢查询,profile) 对于使用索引和没有使用索引,了解到索引可以快速去查找数据 了解什么是索引(索引是排好序的快速查找的数据结构) 索引的 ...
- [转载] EXPLAIN执行计划中要重点关注哪些要素
原文: https://mp.weixin.qq.com/s?__biz=MjM5NzAzMTY4NQ==&mid=400738936&idx=1&sn=2910b4119b9 ...
- EXPLAIN执行计划中要重点关注哪些要素(叶金荣)
原文:http://mp.weixin.qq.com/s/CDKN_nPcIjzA_U5-xwAE5w 导读 EXPLAIN的结果中,有哪些关键信息值得注意呢? MySQL的EXPLAIN当然和ORA ...
- EXPLAIN执行计划中要重点关注哪些要素
MySQL的EXPLAIN当然和ORACLE的没法比,不过我们从它输出的结果中,也可以得到很多有用的信息. 总的来说,我们只需要关注结果中的几列: 列名 备注 type 本次查询表联接类型,从这里可以 ...
随机推荐
- 「 深入浅出 」java集合Collection和Map
本系列文章主要对java集合的框架进行一个深入浅出的介绍,使大家对java集合有个深入的理解. 本篇文章主要具体介绍了Collection接口,Map接口以及Collection接口的三个子接口Set ...
- 插画版Kubernetes指南
原文地址:https://www.cnblogs.com/kouryoushine/articles/8007648.html 是根据一个视频翻译过来的,比较形象 编者按:Matt Butcher 是 ...
- 玩转Django2.0---Django笔记建站基础十(一)(常用的Web应用程序)
第十章 常用的Web应用程序 Django为开发者提供了常见的Web应用程序,如会话控制.高速缓存.CSRF防护.消息提示和分页功能.内置的Web应用程序大大优化了网站性能,并且完善了安全防护机制,而 ...
- .net core 常见设计模式-IChangeToken
场景 一个对象A,希望它的某些状态在发生改变时通知到B(或C.D),常见的做法是在A中定义一个事件(或直接用委托),当状态改变时A去触发这个事件.而B直接订阅这个事件 这种设计有点问题B由于要订阅A的 ...
- Shell常用命令之echo
echo 字符串的输出 选项 -n:不换行输出 -e:启用反斜杠转义符 -E:禁用反斜杠转义符 反斜杠转义符 \a:发出警告声 \b:删除前一个字符 \c:最后不加上换行符号 \f:换行但光标仍然停留 ...
- Docker深入浅出系列 | 单节点多容器网络通信
目录 教程目标 准备工作 带着问题开车 同一主机两个容器如何相互通信? 怎么从服务器外访问容器 Docker的三种网络模式是什么 Docker网络通信原理 计算机网络模型回顾 Linux中的网卡 查看 ...
- ubuntu系统下安装pip3及第三方库的安装
ubuntu系统下会自带python2.x和python3.x坏境,不需要我们去安装.并且ubuntu系统下还会自动帮助我们安装python2.x坏境下的pip安装工具, 但是没有python3.x坏 ...
- Android头像更换之详细操作
Android开发之头像的更换(拍照,从手机照片中选择) 先说一下昨天未解决的问题:原因是自己在获取对象时,没有将新加的图片属性加到该对象里,导致一直爆空指针异常. 接下来分析一下头像更换的具体操作: ...
- js笔记(3)--js实现数组转置(两种方法)
js实现数组转置 第一种方法: <script> window.onload=function(){ var array1=[[11,22,33,333],[4 ...
- 使用ClouderaManager管理的HBase的RegionServer无法启动(启动失败)的问题
问题概述 "新冠期间"远程办公,需要重新搭建一套ClouderaManager(CM)开发环境,一位测试同事发现HBase的RegionServer无法启动,在CM界面上启动总是失 ...