【巨杉数据库Sequoiadb】巨杉⼯具系列之一 | ⼤对象存储⼯具sdblobtool
近期,巨杉数据库正式推出了完整的SequoiaDB 工具包,作为辅助工具,更好地帮助大家使用和运维管理分布式数据库。为此,巨杉技术社区还将持续推出工具系列文章,帮助大家了解巨杉数据库丰富的工具矩阵。
本文作为系列第一篇,将分享巨杉数据库大数据存储工具 sdblobtool 的基本介绍和应用实践。
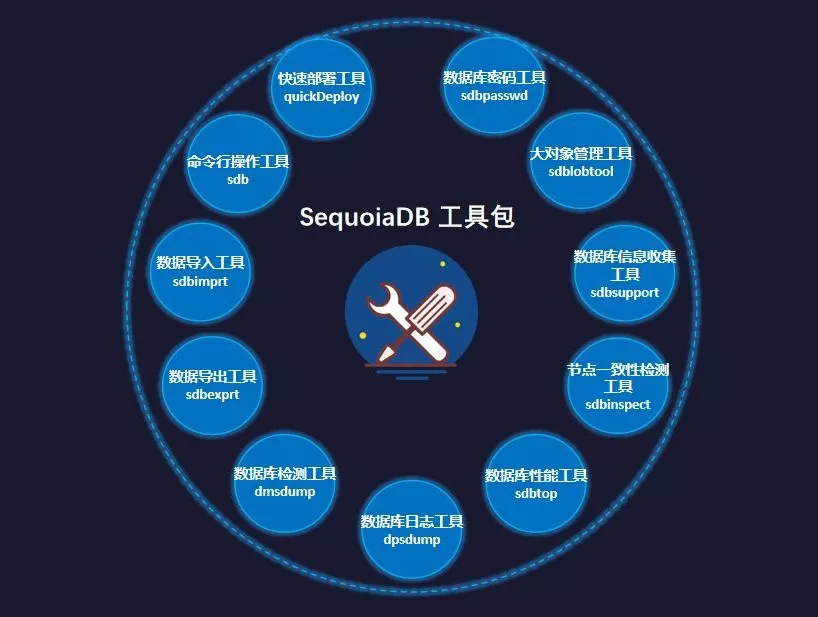
巨杉工具矩阵
一、对象存储与自建存储对比
通俗地讲,自建存储就是自己购买服务器设备存储文件,通过运维人员手工进行文件的上传下载。而对象存储,则是使用不同的存储形态来存储文件。目前,对象存储独立的存储形态有三种:块存储、⽂件存储以及新出现的对象存储。
块存储:简单来说,块存储就是将硬盘直接挂载到主机,在主机上我们能够看到的就是一块块的硬盘以及硬盘分区。从存储架构的角度而言,块存储又分为DAS存储(Direct-Attached Storage,直连式存储)和SAN存储(Storage Area Network,存储区域网络)。
文件存储:指的是在文件系统上的存储,也就是主机操作系统中的文件系统。我们知道,文件系统中有分区,有文件夹,子文件夹,整体形成⼀个自上而下的⽂件结构,⽤户可以通过操作系统中的应⽤程序来打开和修改文件系统下的⽂件。
对象存储:指的是⾯向对象/⽂件的、海量的互联网存储对象。虽然它也是文件,但它是已经被封装的⽂件(编程中的对象就有封装性的特点)。在对象存储系统⾥,用户不能直接打开和修改⽂件,但可以像 ftp ⼀样上传和下载⽂件。另外,对象存储不像⽂件系统那样有⼀个很多层级的⽂件结构,而是只有⼀个“桶”的概念(也就是存储空间),“桶”⾥⾯全部都是对象,是一种非常扁平化的存储方式。
二、巨杉数据库大对象存储
SequoiaDB 和各大云平台对象存储都提供存储服务,都具备分布式、可扩展、高可用等特性。各大云平台对象存储是专门为对象存储而设计的,而SequoiaDB的块存储引擎则针对非结构化数据存储。
SequoiaDB 的块存储字段类型叫做LOB(Large OBject,大对象),其核心机制是将内容文件打散成多个数据块,每个数据块被分别发送到不同分区独立存放。如下图所示:

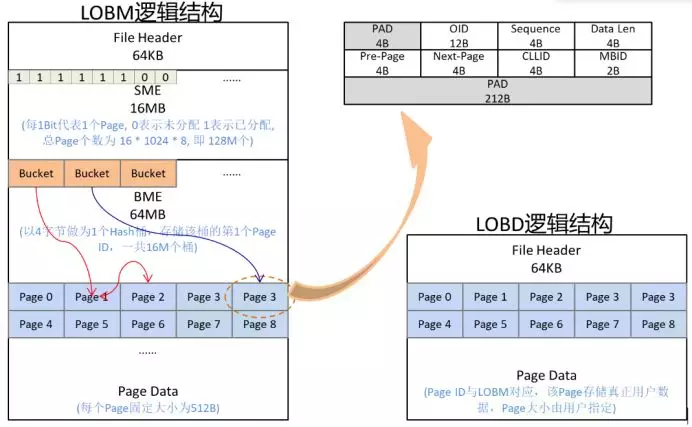
LOB 文件逻辑结构
与其他解决方案相比,由于不存在独立中控元数据节点,SequoiaDB 提供的 LOB 存储机制理论上可以存放近乎无限数量的对象文件,并且不会由于元数据堆积而造成性能下降。同时,由于数据块被散列分布到所有数据节点,整个系统的吞吐量随集群磁盘数量的增加近乎线性提升。最后,SequoiaDB 提供原生的内容管理接口,通过 REST 访问方式支持批次管理、版本管理、流程管理等一系列基本CM特性。
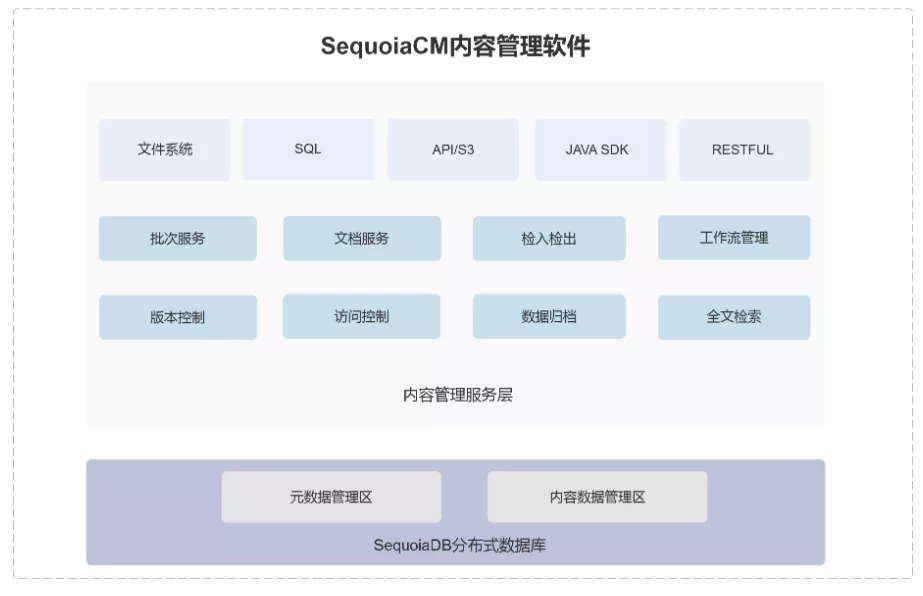
基于LOB 存储机制的内容管理平台架构图
从使用方式上看,SequoiaDB的 LOB 机制可以使用原生 API 的访问形式,对底层 LOB 对象进行读写访问;同时,用户也可以通过高阶 CM API Java 接口,Java 驱动会将请求封装成 RESTful 形式,通过发送接收 HTTP 报文进行对象和批次级别读写更新操作。
相对于其他云存储平台,巨杉数据库对象存储具有以下优势:
安全性
SequoiaDB 提供基于本地化的对象存储,通过多副本数据备份,实现数据安全,安全性毋庸置疑。
支持全类型数据的覆盖
SequoiaDB 是⼀款以 JSON/BSON 数据类型作为底层存储格式的分布式关系型数据库,支持灵活的数据类型定义和存储,支持全类型数据的覆盖,可同时存储结构化、半结构化和非结构化数据,对大数据的存储与分析提供了了一个坚实、可靠、高效与灵活的底层平台。
更加灵活的一致性策略
目前,SequoiaDB 数据分区组的数据一致性是基于集合级别进行配置的。用户在使用SequoiaDB 的过程中,可以随时调整数据一致性的强度。在一个多副本的 SequoiaDB 集群中,集合默认的数据⼀致性行级别为“最终⼀致性”。
深度整合大数据体系组件
SequoiaDB 的企业版本不仅集成了 Hadoop 的 HDFS、MapReduce和Spark,还向客户提供完善的 SQL 解决方案和丰富的第三方插件,例如 ETL 工具 Kettle 的 SequoiaDB 插件,Spark SQL 的扩展包--支持 Spark SQL 自动同步操作 SequoiaDB 数据集等。
SequoiaDB 不仅通过了全球最大的 Hadoop 发行商 Cloudera 的官方认证(全球只有四家 NoSQL 数据库获得),还获得了了 DataBricks 的官方认证,同时,SequoiaDB 也是国内三家经过 DataBricks 授权,拥有发行 Spark 权利的厂商之⼀。
三、大对象存储工具 sdblobtool ⽤法
sdblobtool 是一款用于管理 SequoiaDB 集合中大对象的工具,具有大对象(lob)的导出、导⼊、迁移的功能。
1. 大对象的导出
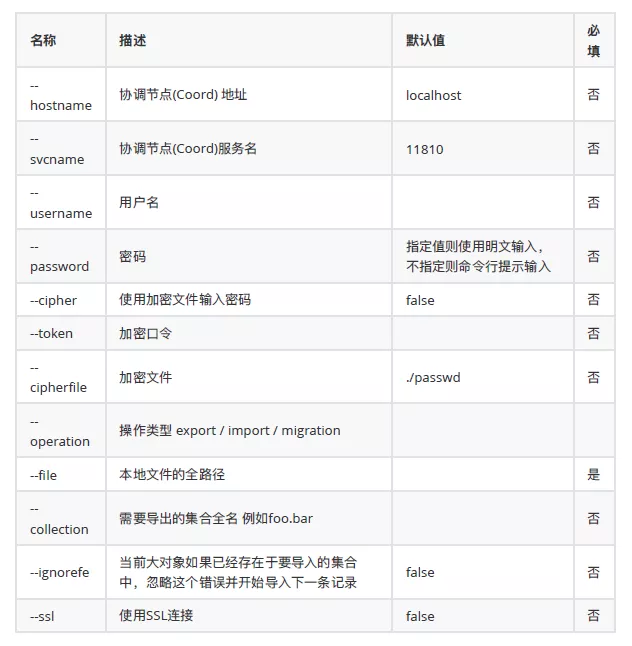
导出功能是将集合中的⼤对象导出到本地⽂件。导出参数:

Note:--prefer 的取值包括 M 或 m 指master(主节点); S 或 s(从节点); A 或 a 表示anyone; 通过1~255指定instanceid(实例id)
导出示例:1. 连接主机名为 sdb 的数据库服务器中服务名为11810协调节点,将集合空间为 sample,集合为 employee 中的大对象导⼊到本地文件 mylob。
[sdbadmin@sdb01]$ sdblobtool --operation export --hostname sdb --svcname 11810--collection sample.employee --file /opt/file/lobfile
执行效果
[sdbadmin@sdb] sdblobtool --operation export --hostname sdb --svcname 11810 --collection sample.employee --file /home/sdbadmin/myloblob exporting has been done, total num:6#查看当前目录下的日志文件[sdbadmin@sdb] ls -lrt总用量 104-rw-r-----1 sdbadmin sdbadmin_group 99328 10月 27 18:24 myblog-rw-r--r--1 sdbadmin sdbadmin_group 1497 10月 27 18:24 sdblobtool.log
导出日志
2019-10-27-18.24.33.252414 Level:EVENTPID:23987 TID:23987Function:main Line:323Message:Start sdblobtool [Ver:3.2, Re;ease: 42463, Build: 2019-07-27-20.55.27]...2019-10-27-18.24.33.252848 Level:EVENTPID:23987 TID:23987Function:main Line:344File:SequoiaDB/engine/pmd/sdblobtool.cppMessage:options:{省略}2019-10-27-18.24.33.257633 Level:EVENTPID:23987 TID:23987Function:_exportLobFile:Sequoiadb/engine/mig/migLobTool.cppMessage:begin to export lob2019-10-27-18.24.33.270184 Level:EVENTPID:23987 TID:23987Function:_exportLobFile:Sequoiadb/engine/mig/migLobTool.cppMessage:lob exporting has been done, total num:62019-10-27-18.24.33.270323 Level:EVENTPID:23987 TID:23987Function:_exportLobFile:Sequoiadb/engine/pmd/sdblobtool.cppMessage:sdblobtool quit. rc: 0, shell rc: 0.
2. 连接主机名为 sdb01 的数据库服务器器中服务名为 11810 协调节点,使用用户名 sdbadmin,密码 sdbadmin,将集合空间为 sample,集合为 employee 中的大对象导入到本地文件 lobfile。
[sdbadmin@sdb01]$ sdblobtool --operation export --hostname sdb01 --svcname11810 --username sdbadmin --password sdbadmin --collection samole.employee --file/opt/file/lobfile
3. 将集合空间为bizz,集合为 img 中的大对象导入到本地文件 lobfile 中,并指定从主节点导出。
[sdbadmin@sdb01]$ sdblobtool --operation export --hostname sdb01 --svcname11810 --collection bizz.img --prefer M --file /opt/file/lobfile
2. 大对象的导入⼤对象导入是将本地文件中的大对象文件导入到集合中, 导入参数:

Note: 指定--ignorefe 时只需要添加 --ignorefe即可,不需要为其指定具体值。--file的本地⽂文件指使用 sdblobtool 导出⽣生成的文件。
导入示例:1. 将本地文件 mylob 中的⼤对象导入至集合空间 sample,集合 employee2 中,当遇到已经存在的大对象时跳过。
[sdbadmin@sdb01]$ sdblobtool --operation import --hostname sdb --svcname 11810--collection sample.employee2 --file /home/sdbadmin/mylob --ignorefe
执行效果
[sdbadmin@sdb] ls lrt总用量 100-rw-r-----1 sdbadmin sdbadmin_group 99328 10月 27 18:27 mylob[sdbadmin@sdb][sdbadmin@sdb] sdblobtool --operation import --hostname sdb --svcname 11810 --collection sample.employee2 --file /home/sdbadmin/mylob --ignorefFile version: 1 TotalNum: 6 CreateTime: 2019-10-27-18.27.27.894000lob importing has been done, total num: 0[sdbadmin@sdb][sdbadmin@sdb] ls -lrt总用量 104-rw-r-----1 sdbadmin sdbadmin_group 99328 10月 27 18:27 mylob-rw-r--r--1 sdbadmin sdbadmin_group 1492 10月 27 18:30 sdblobtool.log
导出日志
2019-10-27-18.30.08.474176 Level:EVENTPID:8084 TID:8084Function:main Line:323File:SequoiaDB/engine/pmd/sdblobtool.cppMessage:Start sdblobtool [Ver: 3.2, Release: 42463, Build: 2019-07-27-20.55.27]...2019-10-27-18.30.08.474534 Level:EVENTPID:8084 TID:8084Function:main Line:344File:SequoiaDB/engine/pmd/sdblobtool.cppMessage:options:{ "hostname": "sdb", "svcname": "11810", "usrname": "", "passwd": "", "operation": "import", "collection": "foo.bar2", "file": "/home/sdbadmin/mylob", "ignorefe": true, "dsthost": "localhost", "dstservice": "11810", "dstusrname": "", "dstpasswd": "", "PreferedInstance": "M", "ssl": false }2019-10-27-18.30.08.478471 Level:EVENTPID:8084 TID:8084Function:_importLob Line:628File:SequoiaDB/engine/mig/migLobTool.cppMessage:begin to import lob2019-10-27-18.30.08.484134 Level:EVENTPID:8084 TID:8084Function:_importLob Line:654File:SequoiaDB/engine/mig/migLobTool.cppMessage:lob importing has been done, total num:02019-10-27-18.30.08.484228 Level:EVENTPID:8084 TID:8084Function:main Line:365File:SequoiaDB/engine/pmd/sdblobtool.cppMessage:sdblobtool quit. rc: 0, shell rc: 0.
2. 使用用户名 sdbadmin 密码 sdbadmin 将本地文件 mylob 中的大对象导入至集合空间 sample,集合 employee2 中,当遇到已经存在的大对象则跳过。
[sdbadmin@sdb01]$ sdblobtool --operation import --hostname sdb01 --username sdbadmin --passwd sdbadmin --svcname 11810 --collection sample.employee2 --file /home/sdbadmin/mylob --ignorefe3. 大对象迁移大对象迁移是将集合中的大对象迁移到另一个集合中,迁移参数:
Note:指定--ignorefe 时只需要添加 --ignorefe即可,不需要为其指定具体值。
迁移示例:连接集群主机名为 sdb01 中的协调节点11810,将集合空间 sample,集合 employee 下的大对象复制到另一个集群,目标集群主机名为 sdb02,协调节点为11810,集合空间 sample,集合 employee2 中,需要已存在的大对象跳过。
[sdbadmin@sdb01]$ sdblobtool --operation migration --hostname sdb01 --svcname 11810 --collection sample.employee --dsthost sdb02 --dstservice 11810 --dstcollection sample.employee2 --ignorefe4. 导出成功标志
指定大对象迁移命令后,控制台会在命令执行后给出本次命令执行结果:
大对象导出
lob exporting has been done, total num:6大对象导入
File version: 1 TotalNum: 6 CreateTime: 2019-10-27-18.27.27.894000lob importing has been done, total num: 0
用户通过控制台输出可以判断本次导入或者导出是否存在问题。然后再进入导入/导出生成的 sdblobtool.log 日志文件,检查日志文件中文件导出数量的统计,查看日志文件是否存在 ERROR 信息,判断本地操作是否存在错误。
5. 大对象工具日志
使用 sdblobtool 时,命令执行结束会在当前所在目录生成 "sdblobtool.log" 日志文件,当发生错误时,用户可以进入日志文件查看错误的详细信息。
6. 常见问题以下为使用 sdblobtool 工具时常见问题。

其他问题可参照巨杉数据库错误码文档进行对照错误码参考文档: http://doc.sequoiadb.com/cn/sequoiadb-cat_id-1432190985-edition_id-0
四、总结
巨杉数据库对象存储通过多副本备份机制实现数据安全,并且具备更加灵活的⼀致性策略,支持全类型数据覆盖,深度整合大数据体系组件。sdblobtool 是一款用于管理 SequoiaDB 集合中大对象的工具,具有大对象(lob)的导出、导入、迁移的功能,使用便捷高效。
【巨杉数据库Sequoiadb】巨杉⼯具系列之一 | ⼤对象存储⼯具sdblobtool的更多相关文章
- 【巨杉数据库SequoiaDB】为“战疫” 保驾护航,巨杉在行动
2020年,我们经历了一个不平静的新春,在这场大的“战疫”中,巨杉数据库也积极响应号召,勇于承担新一代科技企业的社会担当,用自己的行动助力这场疫情防控阻击战! 赋能“战疫”快速响应 巨杉数据库目前服务 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 四步走,快速诊断数据库集群状态
1.背景 SequoiaDB 巨杉数据库是一款金融级分布式数据库,包括了分布式 NewSQL.分布式文件系统与对象存储.与高性能 NoSQL 三种存储模式,分别对应分布式在线交易.非结构化数据和内容管 ...
- 【巨杉数据库SequoiaDB】巨杉数据库 v5.0 Beta版 正式发布
2020年疫情的出现对众多企业运营造成了严重的影响.面对突发状况,巨杉利用长期积累的远程研发协作体系,仍然坚持进行技术创新,按照已有规划推进研发工作,正式推出了巨杉数据库(SequoiaDB) v ...
- 【巨杉数据库SequoiaDB】省级农信国产分布式数据库应用实践
本文转载自<金融电子化> 原文链接:https://mp.weixin.qq.com/s/WGG91Rv9QTBHPsNVPG8Z5g 随着移动互联网的迅猛发展,分布式架构在互联网IT技术 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 巨杉数据库数据高性能数据导入迁移实践
SequoiaDB 一款自研金融级分布式数据库产品,支持标准SQL和分布式事务功能.支持复杂索引查询,兼容 MySQL.PGSQL.SparkSQL等SQL访问方式.SequoiaDB 在分布式存储功 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 分布式数据库千亿级超大表优化实践
01 引言 随着用户的增长.业务的发展,大型企业用户的业务系统的数据量越来越大,超大数据表的性能问题成为阻碍业务功能实现的一大障碍.其中,流水表作为最常见的一类超大表,是企业级用户经常碰到的性能瓶颈. ...
- 【巨杉数据库SequoiaDB】社区分享 | SequoiaDB + JanusGraph 实践
本文来自社区用户投稿,感谢小伙伴的技术分享 项目背景 大家好!在春节这段时间里,由于一直在家,所以花时间捣鼓了一下代码,自己做了 SequoiaDB 和 JanusGraph 的兼容扩展工作. 自己觉 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 巨杉数据库的并发 malloc 实现
本文由巨杉数据库北美实验室资深数据库架构师撰写,主要介绍巨杉数据库的并发malloc实现与架构设计.原文为英文撰写,我们提供了中文译本在英文之后. SequoiaDB Concurrent mallo ...
- 巨杉数据库SequoiaDB】巨杉Tech | SequoiaDB 分布式事务实现原理简介
1 分布式事务背景 随着分布式数据库技术的发展越来越成熟,业内对于分布式数据库的要求也由曾经只用满足解决海量数据的存储和读取这类边缘业务向核心交易业务转变.分布式数据库如果要满足核心账务类交易需求,则 ...
随机推荐
- 来去学习之---KMP算法--next计算过程
一.概述 KMP算法是一种字符串匹配算法,比如现有字符串 T:ABCDABCDABCDCABCDABCDE, P:ABCDABCDE P字符串对应的next值:[0,0,0,0,1,2,3,4,0] ...
- 用PHP&JS实现的ID&密码校验程序
声明:本程序纯粹是本人在学习过程中突发奇想做的,并未考虑任何可行性,实用性,只是留下来供以后参考. 前端页面 sign.html <!DOCTYPE html> <html> ...
- 刷题94. Binary Tree Inorder Traversal
一.题目说明 题目94. Binary Tree Inorder Traversal,给一个二叉树,返回中序遍历序列.题目难度是Medium! 二.我的解答 用递归遍历,学过数据结构的应该都可以实现. ...
- PHPJN0001:phpmyadmin 允许密码为空 设置
phpmyadmin连接mysql数据库,出于安全考虑,默认不允许使用空密码连接数据库.因为数据库一般都设置密码访问. 但如果只是本机环境测试使用,每隔一段时间都需要填写密码,不是很方便. 如果没有修 ...
- Oracle查询如何才能行转列?-sunziren
原创文章,转载务必注明出处. 今天工作的时候,碰到一个问题,涉及oracle行转列,用了半小时解决,因此在这里写个博客记录一下解决办法. 原数据库表的数据是: 想要达到的效果是: 经过思考,这是一个o ...
- Win10多用户同时登陆远程桌面
想记录一下最近解决的一些问题,发现还是博客最合适,虽然之前从来没写过,希望以后能养成这个好习惯. 家里有一台台式机装着Win10,还有一台macbook,平时遇到需要用Win系统又不想坐在书桌前时,我 ...
- 小Z的袜子(hose) HYSBZ - 2038 莫队+分块
#include<bits/stdc++.h> using namespace std; typedef long long ll; typedef pair<ll,ll>pl ...
- Asciidoctor-pdf生成pdf文件
本文使用asciidoc语法编写. = Asciidoctor-pdf生成pdf文件 Pinnsvin Pinnsvin@163.com v1.0 {docdate} :plantuml-server ...
- P5367 【模板】康托展开
我们的生活充满了未知与玄学 ---------------------------------------- 链接:P5367 ------------------------------------ ...
- c#---out参数
一个方法有多个返回值时,返回值类型相同可以返回一个数组 static void Main(string[] args) { , , , , , , , , , }; int[] result = Ge ...