spring cloud 微服务日志跟踪 sleuth logback elk 整合
看过我之前的文章的就可以一步一步搭建起日志传输到搜索引擎 不知道的 看下之前的文章
(1) 记一次logback传输日志到logstash根据自定义设置动态创建ElasticSearch索引
(2)关于” 记一次logback传输日志到logstash根据自定义设置动态创建ElasticSearch索引” 这篇博客相关的优化采坑记录
(3)日志收集(ElasticSearch)串联查询 MDC
这里我们结合sleuth 可以降服务之间的调用使用唯一标识串联起来已达到我们通过一个标识可以查看所有跨服务调用的串联日志,与上一篇 的MDC不同
sleuth 简单原理说下
就是在最初发起调用者的时候在请求头head中添加唯一标识传递到直接调用的服务上面
然后之后的服务做类似的操作
好了 不多比比了
上代码
首先所有的服务或spring boot项目都引入以下包
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>com.cwbase</groupId>
<artifactId>logback-redis-appender</artifactId>
<version>1.1.5</version>
</dependency>
一个是传输redis使用一个是调用链跟踪使用
下面是logback配置文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false" scan="true" scanPeriod="1 seconds">
<include resource="org/springframework/boot/logging/logback/base.xml" />
<!-- <jmxConfigurator/> -->
<contextName>logback</contextName> <property name="log.path" value="\logs\logback.log" /> <property name="log.pattern"
value="%d{yyyy-MM-dd HH:mm:ss.SSS} -%5p ${PID} --- traceId:[%X{mdc_trace_id}] [%15.15t] %-40.40logger{39} : %m%n" /> <appender name="file"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}</file> <encoder>
<pattern>${log.pattern}</pattern>
</encoder> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>info-%d{yyyy-MM-dd}-%i.log
</fileNamePattern> <timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <maxFileSize>10MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<maxHistory>10</maxHistory>
</rollingPolicy> </appender> <appender name="redis" class="com.cwbase.logback.RedisAppender"> <tags>test</tags>
<host>IP</host><!--redis IP-->
<port>6379</port><!--redis端口-->
<key>test</key><!--redis队列名称-->
<!-- <mdc>true</mdc> -->
<callerStackIndex>0</callerStackIndex>
<location>true</location> <additionalField>
<key>X-B3-ParentSpanId</key>
<value>@{X-B3-ParentSpanId}</value>
</additionalField>
<additionalField>
<key>X-B3-SpanId</key>
<value>@{X-B3-SpanId}</value>
</additionalField>
<additionalField>
<key>X-B3-TraceId</key>
<value>@{X-B3-TraceId}</value>
</additionalField>
</appender> <root level="info">
<!-- <appender-ref ref="CONSOLE" /> -->
<!-- <appender-ref ref="file" /> -->
<!-- <appender-ref ref="UdpSocket" /> -->
<!-- <appender-ref ref="TcpSocket" /> -->
<appender-ref ref="redis" />
</root> <!-- <logger name="com.example.logback" level="warn" /> --> </configuration>
与之前的logback.xml配置文件相比主要更改一下内容
<additionalField>
<key>X-B3-ParentSpanId</key>
<value>@{X-B3-ParentSpanId}</value>
</additionalField>
<additionalField>
<key>X-B3-SpanId</key>
<value>@{X-B3-SpanId}</value>
</additionalField>
<additionalField>
<key>X-B3-TraceId</key>
<value>@{X-B3-TraceId}</value>
</additionalField>
一会在详细解释上述三个字段含义 下面先看项目目录结构
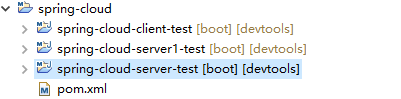
一个父工程(pom工程)三个spring boot子项目 子项目调用关系如下

三个子项目代码如下
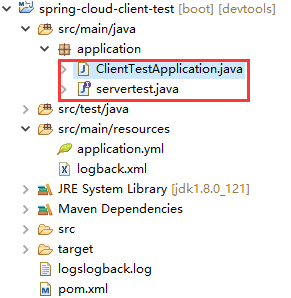
spring-cloud-client-test工程结构及代码
package application; import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.feign.EnableFeignClients;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController; @EnableAutoConfiguration
@EnableFeignClients
@RestController
@SpringBootApplication
public class ClientTestApplication {
protected final static Logger logger = LoggerFactory.getLogger(ClientTestApplication.class); public static void main(String[] args) {
SpringApplication.run(ClientTestApplication.class, args);
} @Autowired
servertest server; @GetMapping("/client")
public String getString(){
logger.info("开始调用服务端");
return server.getString();
}
@GetMapping("/client1")
public String getString1(){
logger.info("开始调用服务端1");
return server.getString1();
}
}
package application; import org.springframework.cloud.netflix.feign.FeignClient;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod; @FeignClient("SPRING-CLOUD-SERVER-TEST")
public interface servertest {
@RequestMapping(value = "/server", method = RequestMethod.GET, consumes = MediaType.APPLICATION_JSON_VALUE, produces = MediaType.APPLICATION_JSON_VALUE)
public String getString();
@RequestMapping(value = "/server1", method = RequestMethod.GET, consumes = MediaType.APPLICATION_JSON_VALUE, produces = MediaType.APPLICATION_JSON_VALUE)
public String getString1();
}
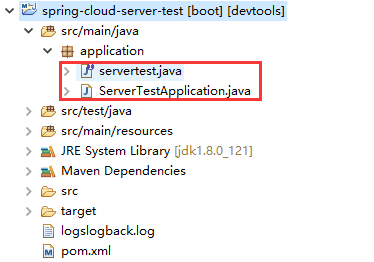
spring-cloud-server-test工程及代码结构
package application; import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.feign.EnableFeignClients;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController; @EnableAutoConfiguration
@EnableFeignClients
@RestController
@SpringBootApplication
public class ServerTestApplication {
protected final static Logger logger = LoggerFactory.getLogger(ServerTestApplication.class); public static void main(String[] args) {
SpringApplication.run(ServerTestApplication.class, args);
} @Autowired
servertest server; @GetMapping("/server")
public String getString(){
logger.info("接收客户端的调用");
return server.getString();
}
@GetMapping("/server1")
public String getString1(){
logger.info("接收客户端的调用1");
return server.getString1();
}
}
package application; import org.springframework.cloud.netflix.feign.FeignClient;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod; @FeignClient("SPRING-CLOUD-SERVER1-TEST")
public interface servertest {
@RequestMapping(value = "/server", method = RequestMethod.GET, consumes = MediaType.APPLICATION_JSON_VALUE, produces = MediaType.APPLICATION_JSON_VALUE)
public String getString();
@RequestMapping(value = "/server1", method = RequestMethod.GET, consumes = MediaType.APPLICATION_JSON_VALUE, produces = MediaType.APPLICATION_JSON_VALUE)
public String getString1();
}
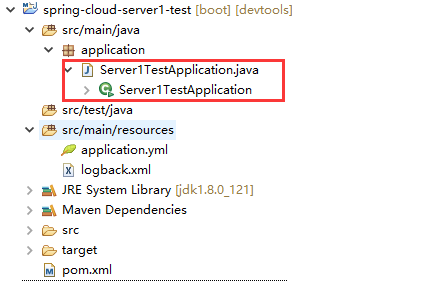
spring-cloud-server1-test工程及代码结构
package application; import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController; @RestController
@SpringBootApplication
public class Server1TestApplication {
protected final static Logger logger = LoggerFactory.getLogger(Server1TestApplication.class); public static void main(String[] args) {
SpringApplication.run(Server1TestApplication.class, args);
} @GetMapping("/server")
public String getString(){
logger.info("接收客户端的调用");
return "My is server";
}
@GetMapping("/server1")
public String getString1(){
logger.info("接收客户端的调用1");
return "My is server1";
}
}
好了 全部代码就是以上这些 下面看日志传输之后的效果

上图就是最后的结果
我们可以通过 X-B3-TraceId 串联所有的服务 这个值每次请求都不一样但是会随着调用链一直传递下去
X-B3-SpanId 这个值属于方法级别的值 也就是说 方法调用方法是父子级别的传递(方便调用跟踪)
X-B3-ParentSpanId 这个值就是上一个方法的X-B3-SpanId 我说的不是很明白大家可以查阅相关资料了解
好了到这里就基本完成了
总结思考
使用sleuth我们可以很好的串联快服务的日志,结合MDC就可以出现很完美的调用流水查询但是我们要做到一次查询 要么做表达式筛选要么查询两次 。我们有没有办法将二者结合那,我想并不困难自己重写sleuth相关方法可以做到,但是我们要考虑这是有问题的,什么问题那 就是 同样的MDC key-value 调用 sleuth会变 但是MDC值不变 我们要融合成什么样子才能达到想要的目的的,这个就不好说了 ,通过表达式筛选已经很方便了还有么有必要这样做那,做了之后怎么避免副作用那!有待考究

spring cloud 微服务日志跟踪 sleuth logback elk 整合的更多相关文章
- Spring Cloud微服务实战:手把手带你整合eureka&zuul&feign&hystrix
转载自:https://www.jianshu.com/p/cab8f83b0f0e 代码实现:https://gitee.com/ccsoftlucifer/springCloud_Eureka_z ...
- Spring Cloud 微服务六:调用链跟踪Spring cloud sleuth +zipkin
前言:随着微服务系统的增加,服务之间的调用关系变得会非常复杂,这给运维以及排查问题带来了很大的麻烦,这时服务调用监控就显得非常重要了.spring cloud sleuth实现了对分布式服务的监控解决 ...
- Spring Cloud微服务学习笔记
Spring Cloud微服务学习笔记 SOA->Dubbo 微服务架构->Spring Cloud提供了一个一站式的微服务解决方案 第一部分 微服务架构 1 互联网应用架构发展 那些迫使 ...
- 一张图了解Spring Cloud微服务架构
Spring Cloud作为当下主流的微服务框架,可以让我们更简单快捷地实现微服务架构.Spring Cloud并没有重复制造轮子,它只是将目前各家公司开发的比较成熟.经得起实际考验的服务框架组合起来 ...
- Spring Cloud 微服务架构解决方案
1 理解微服务 1.1 软件架构演进 软件架构的发展经历了从单体结构.垂直架构.SOA架构到微服务架构的过程. 1.1.1 单体架构 特点: 1.所有的功能集成在一个项目工程中. 2.所有的功能打一个 ...
- spring cloud 微服务介绍(转)
一.理解微服务 我们通过软件架构演进过程来理解什么是微服务,软件架构的发展经历了从单体结构.垂直架构.SOA架构到微服务架构的过程. 1. 单体架构 1.1 特点(1)所有的功能集成在一个项目工程 ...
- Spring Cloud微服务系列文,服务调用框架Feign
之前博文的案例中,我们是通过RestTemplate来调用服务,而Feign框架则在此基础上做了一层封装,比如,可以通过注解等方式来绑定参数,或者以声明的方式来指定请求返回类型是JSON. 这种 ...
- Dubbo和Spring Cloud微服务架构比较
Dubbo 出生于阿里系,是阿里巴巴服务化治理的核心框架,并被广泛应用于中国各互联网公司:只需要通过 Spring 配置的方式即可完成服务化,对于应用无入侵,设计的目的还是服务于自身的业务为主. 微服 ...
- 在阿里云容器服务上开发基于Docker的Spring Cloud微服务应用
本文为阿里云容器服务Spring Cloud应用开发系列文章的第一篇. 一.在阿里云容器服务上开发Spring Cloud微服务应用(本文) 二.部署Spring Cloud应用示例 三.服务发现 四 ...
随机推荐
- Go基础系列:Go中的方法
Go方法简介 Go中的struct结构类似于面向对象中的类.面向对象中,除了成员变量还有方法. Go中也有方法,它是一种特殊的函数,定义于struct之上(与struct关联.绑定),被称为struc ...
- 分布式系统监视zabbix讲解十一之zabbix升级--技术流ken
思考 现在有这样一个需求,业务场景想要使用的监控模版没有3.0版本的,只有2.0,我们都知道2.0的模版无法导入进3.0版本的zabbix中,这个时候应该怎么获得3.0的监控模版哪?本篇博客将详细演示 ...
- [转]Node.JS使用Sequelize操作MySQL
Sequelize官方文档 https://sequelize.readthedocs.io/en/latest/ 本文转自:https://www.jianshu.com/p/797e10fe23 ...
- Windows server 2008 R2配置多个远程连接
1.右键计算机属性——远程设置——出现系统属性对话框——选择“远程”选项卡,按如下图操作:. 2.默认只有administrator具有远程桌面的权限,其他用户都没有权限远程桌面连接服务器.因此,我们 ...
- C#设计模式之十六观察者模式(Observer Pattern)【行为型】
一.引言 今天是2017年11月份的最后一天,也就是2017年11月30日,利用今天再写一个模式,争取下个月(也就是12月份)把所有的模式写完,2018年,新的一年写一些新的东西.今天我们开始讲“行为 ...
- 输出映射resultType
√1:简单类型 √2:简单类型列表 √3:POJO类型只有列名或列名的别名与POJO的属性名一致,该列才可以映射成功只要列名或列名的别名与POJO的属性名有一个一致,就会创建POJO对象如果列名或列名 ...
- js 策略模式 实现表单验证
策略模式 简单点说就是:实现目标的方式有很多种,你可以根据自己身情况选一个方法来实现目标. 所以至少有2个对象 . 一个是策略类,一个是环境类(上下文). 然后自己就可以根据上下文选择不同的策略来执 ...
- js/es6 元素拖动
元素事件:鼠标按下事件/鼠标移动事件/鼠标松开事件 元素样式:让元素脱离文档流,采用绝对定位的方式. 一.鼠标按下事件 当鼠标在元素上面按下时,保存元素的初始偏移量和鼠标按下时的坐标,然后在状态变量里 ...
- RBAC 几种常见的控制权限模型
1. 几种常见的权限模型 2. ACL 和 RBAC 对比 3. RBAC 权限模型的优势 (1)简化了用户和权限的关系 (2).易于扩展 易于维护 4.优势(给权限和收回权限) 5.架构
- H5_canvas与svg
Canvas 什么是canvas: HTML5 的 canvas 元素是使用 JavaScript 在网页上绘制图像,canvas 元素本身是没有绘图能力的,所有的绘制工作必须在 JavaScript ...