Python运维开发:初识Python(一)
一、Pythton简介
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
Python(英国发音:/ˈpaɪθən/ 美国发音:/ˈpaɪθɑːn/),是一种面向对象、直译式的计算机程序语言,具有近二十年的发展历史。它包含了一组功能完备的标准库,能够轻松完成很多常见的任务。它的语法简单,与其它大多数程序设计语言使用大括号不一样,它使用缩进来定义语句块。 与Scheme、Ruby、Perl、Tcl等动态语言一样,Python具备垃圾回收功能,能够自动管理内存使用。它经常被当作脚本语言用于处理系统管理任务和网络程序编写,然而它也非常适合完成各种高级任务。Python虚拟机本身几乎可以在所有的作业系统中运行。使用一些诸如py2exe、PyPy、PyInstaller之类的工具可以将Python源代码转换成可以脱离Python解释器运行的程序。 Python的官方解释器是CPython,该解释器用C语言编写,是一个由社区驱动的自由软件,目前由Python软件基金会管理。 Python支持命令式程序设计、面向对象程序设计、函数式编程、面向侧面的程序设计、泛型编程多种编程范式。
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。
目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团等。互联网公司广泛使用Python来做的事一般有:自动化运维、自动化测试、大数据分析、爬虫、Web 等。
为什么是Python而不是其他语言?
C 和 Python、Java、C#等
C语言: 代码编译得到 机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作
其他语言: 代码编译得到 字节码 ,虚拟机执行字节码并转换成机器码再后在处理器上执行
Python 和 C Python这门语言是由C开发而来
对于使用:Python的类库齐全并且使用简洁,如果要实现同样的功能,Python 10行代码可以解决,C可能就需要100行甚至更多.
对于速度:Python的运行速度相较与C,绝逼是慢了
Python 和 Java、C#等
对于使用:Linux原装Python,其他语言没有;以上几门语言都有非常丰富的类库支持
对于速度:Python在速度上可能稍显逊色
所以,Python和其他语言没有什么本质区别,其他区别在于:擅长某领域、人才丰富、先入为主。
Python的种类
- Cpython
Python的官方版本,使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。 - Jyhton
Python的Java实现,Jython会将Python代码动态编译成Java字节码,然后在JVM上运行。 - IronPython
Python的C#实现,IronPython将Python代码编译成C#字节码,然后在CLR上运行。(与Jython类似) - PyPy(特殊)
Python实现的Python,将Python的字节码字节码再编译成机器码。 - RubyPython、Brython ...
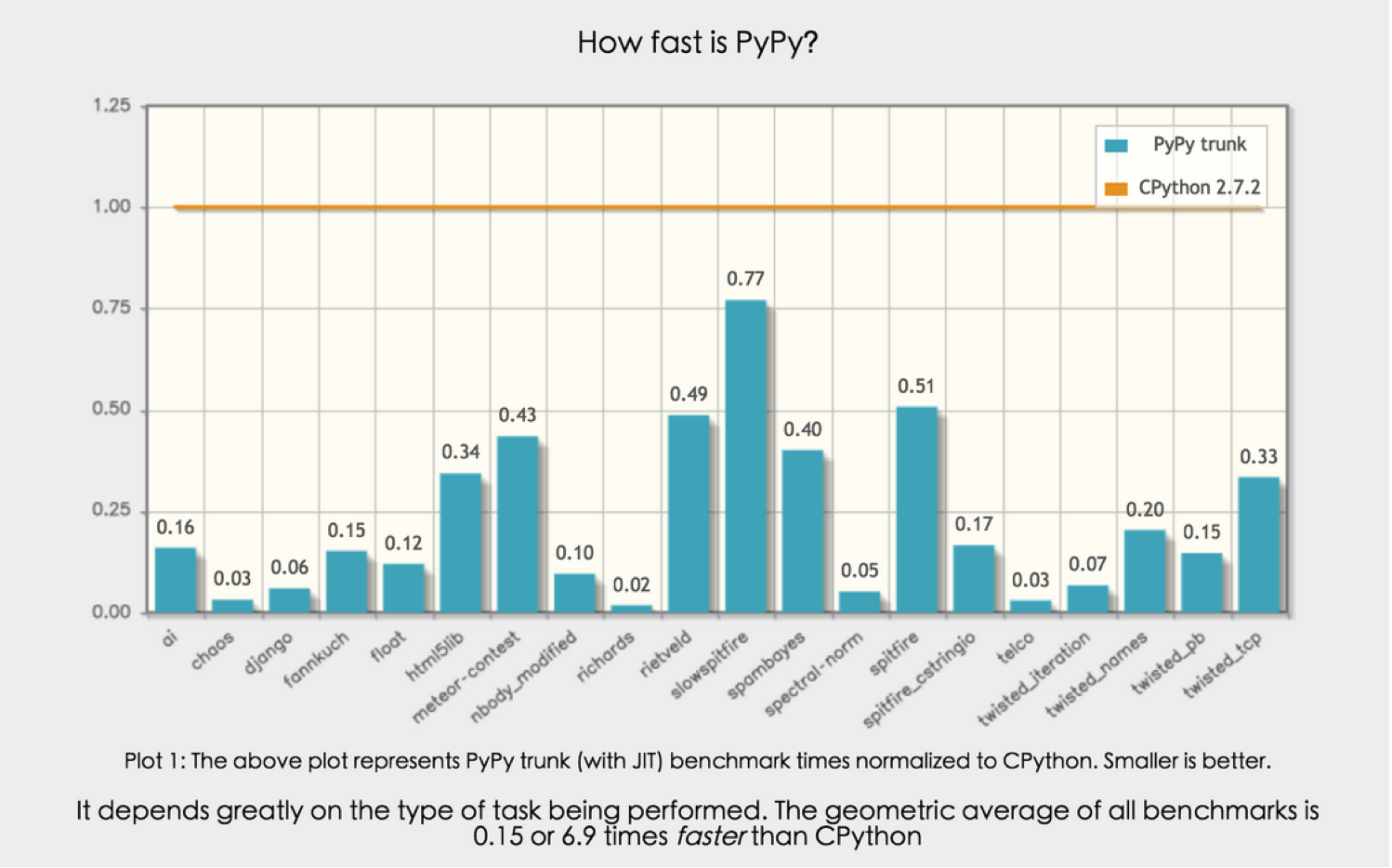
以上除PyPy之外,其他的Python的对应关系和执行流程如下:


PyPy,在Python的基础上对Python的字节码进一步处理,从而提升执行速度!
二、python环境
安装Python
window:(多版本共存)
1、下载安装包 https://www.python.org/downloads/2、安装python2.7.11 默认安装路径:C:\python273、配置环境变量 【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用;分割】 如:原来的值;C:\python27,切记前面有分号4、安装python3.5.1 默认安装路径: C:\python365、将python3.6中的执行程序python.exe重命名成python36、配置环境变量 【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用;分割】 如:原来的值;C:\python36,切记前面有分号7、这样就实现python2.7和python3.6多版本linux:1、无需安装,原装Python环境2、Python27和Python36可以共存更新Python
windows:
卸载重装即可
linux:
Linux的yum依赖自带Python,为防止错误,此处更新其实就是再安装一个Python
查看默认Python版本
python -V 1、安装gcc,用于编译Python源码
yum install gcc
2、下载源码包,https://www.python.org/ftp/python/
3、解压并进入源码文件
4、编译安装
./configure
make all
make install
5、查看版本
/usr/local/bin/python3.6 -V
6、修改默认Python版本
mv /usr/bin/python /usr/bin/python2.7
ln -s /usr/local/bin/python3.6 /usr/bin/python
7、防止yum执行异常,修改yum使用的Python版本
vi /usr/bin/yum
将头部 #!/usr/bin/python 修改为 #!/usr/bin/python2.7
三、Python 代码编写
1、第一句Python代码
在 /home/dev/ 目录下创建 hello.py 文件,内容如下:
print("hello world")
执行 hello.py 文件,即: python /home/dev/hello.py
python内部执行过程如下:
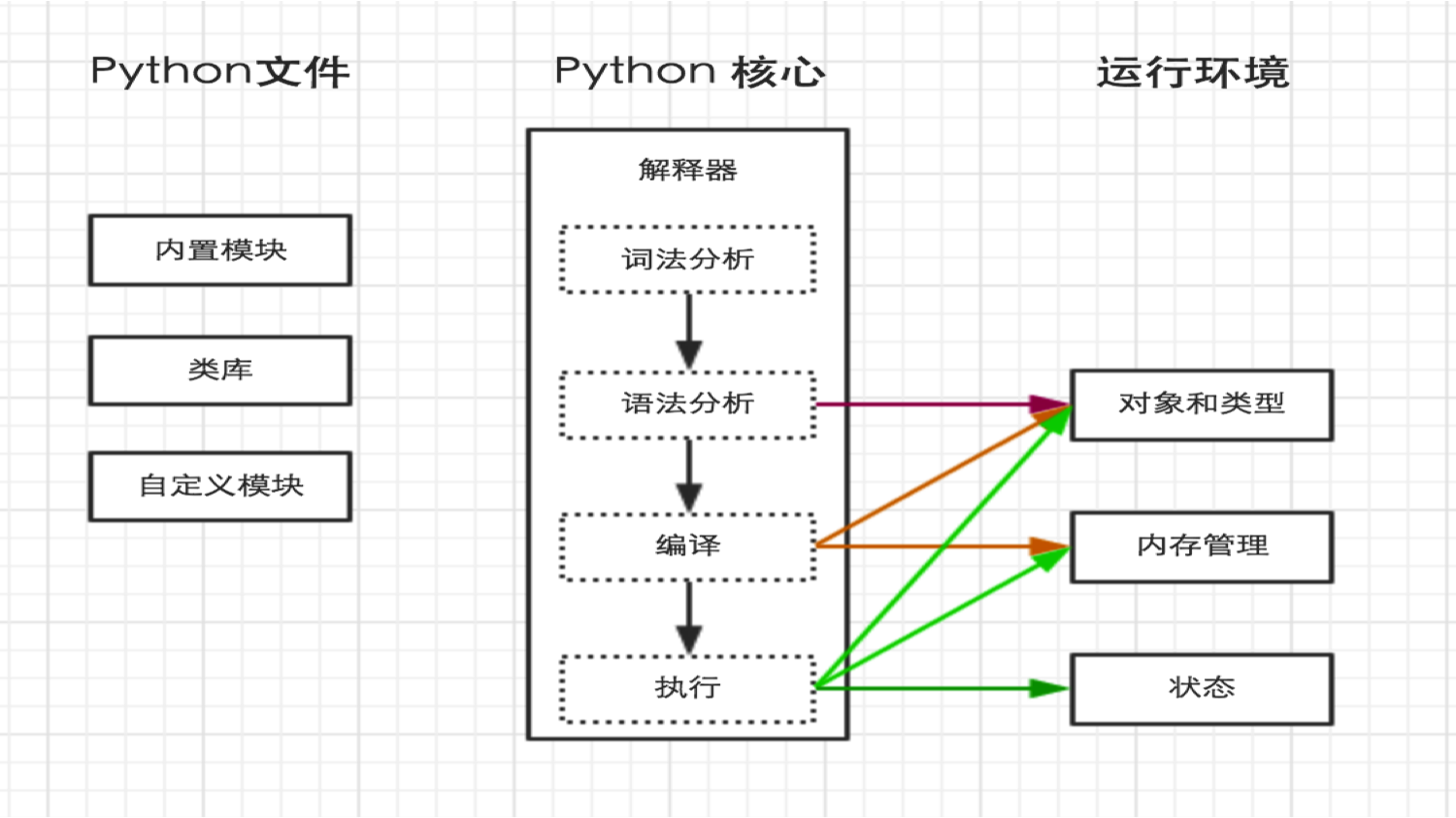
2、解释器
上一步中执行 python /home/dev/hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
#!/usr/bin/env python
print ("hello,world")
如此一来,执行: ./hello.py 即可。
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py
在Linux下执行的时候,第一行指出文件由python解释器来执行,第二行是告诉解释器在加载文件时,采用何种编码,不加上这句的话,在python2中显示中文会出现乱码,在python3中则不会,所以你如果用的是windows而且用的是python3,其实可以不用加这两句,不过实际中还是建议加上这两句。到这里我们就用了两种方式输Hello World。
四、内容编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
1、ASCII
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。

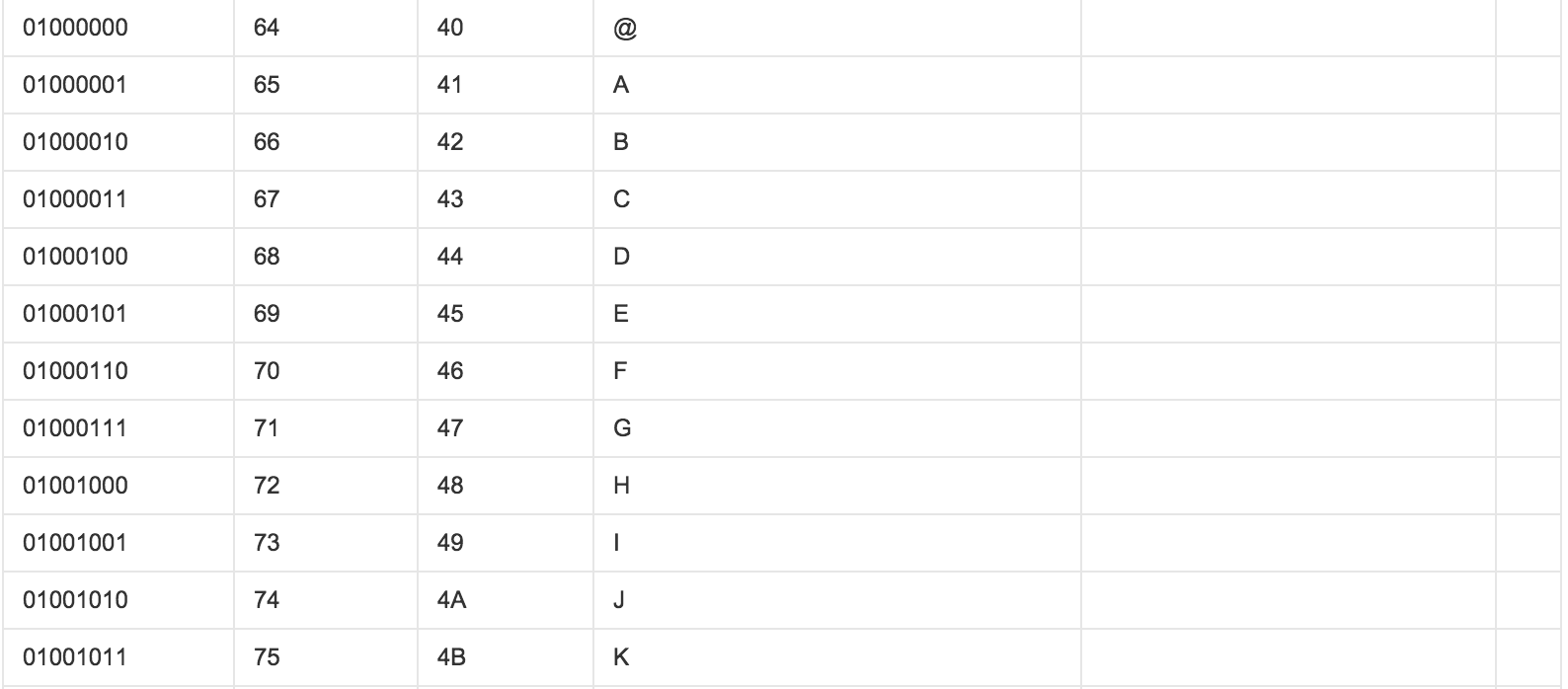
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
2、Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
3、UTF-8
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python2.X解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
#!/usr/bin/env python
print "你好,世界"
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
print "你好,世界"
注意:python3.x中字符集默认为UTF-8,python2.x还是ASCII所以需要设置#coding:utf-8
#!/usr/bin/env python
#-*- coding:utf-8 -*- # Python27,解码要指定原编码,编码要指定编成什么码 temp = "李杰" temp_unicode = temp.decode("utf-8") temp_gbk = temp_unicode.encoding("gbk") print(temp_gbk) # Python35,gbk和utf-8可以直接转换 temp = "李杰" # 为 utf-8 编码
temp_gbk = temp.enoding("utf-8")
五、注释
当行注视:# 被注释内容
多行注释:""" 被注释内容 """
表示续行符: \
注意:如果''''''三引号是在一个def 函数或者class 定义类的下方则是对这个函数或者类的说明,可以通过__doc__动态获得文档子串
六、执行脚本传入参数
Python有大量的模块,从而使得开发Python程序非常简洁。类库包括3种:
- Python内部提供的模块
- 业内开源的模块
- 程序员自己开发的模块
Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持
sys
Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数
#!/usr/bin/env python
# -*- coding: utf-8 -*- import sys
print (sys.argv)
# 输出[root@localhost]# python test.py helo world['test.py', 'helo', 'world'] #把执行脚本时传递的参数获取到了os
>>> import os
>>> os.system("df -h")
注意:os.system()执行系统命令,如果有变量存储该执行的结果,该变量只会存储该命令执行成功或者失败返回值,不会存储命令执行的结果,os.system("df -h")会有返回值。
>>> result = os.system("df -h")
df: ‘/mnt/hgfs’: Protocol error
Filesystem Size Used Avail Use% Mounted on
udev 3.9G 0 3.9G 0% /dev
tmpfs 797M 9.4M 788M 2% /run
/dev/sda1 189G 10G 170G 6% /
tmpfs 3.9G 16M 3.9G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
cgmfs 100K 0 100K 0% /run/cgmanager/fs
tmpfs 797M 76K 797M 1% /run/user/1000
>>> print(result)
256
如果需要保存命令执行的结果需哟使用os.popen("系统命令").read(),然后使用变量赋值输出即可
>>> result = os.popen("df -h").read()
>>> print(result)
Filesystem Size Used Avail Use% Mounted on
udev 3.9G 0 3.9G 0% /dev
tmpfs 797M 9.4M 788M 2% /run
/dev/sda1 189G 10G 170G 6% /
tmpfs 3.9G 16M 3.9G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
cgmfs 100K 0 100K 0% /run/cgmanager/fs
tmpfs 797M 76K 797M 1% /run/user/1000
sys与os结合使用
#!/usr/bin/env python
import os,sys os.system(''.join(sys.argv[1:])) # 执行
[root@localhost]#python e.py df
df: ‘/mnt/hgfs’: Protocol error
Filesystem 1K-blocks Used Available Use% Mounted on
udev 4059116 0 4059116 0% /dev
tmpfs 815812 9596 806216 2% /run
/dev/sda1 198036724 10435852 177518160 6% /
tmpfs 4079040 15996 4063044 1% /dev/shm
tmpfs 5120 4 5116 1% /run/lock
tmpfs 4079040 0 4079040 0% /sys/fs/cgroup
cgmfs 100 0 100 0% /run/cgmanager/fs
tmpfs 815812 76 815736 1% /run/user/1000
七、 pyc 文件
执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
八、变量
1、声明变量
#!/usr/bin/env python
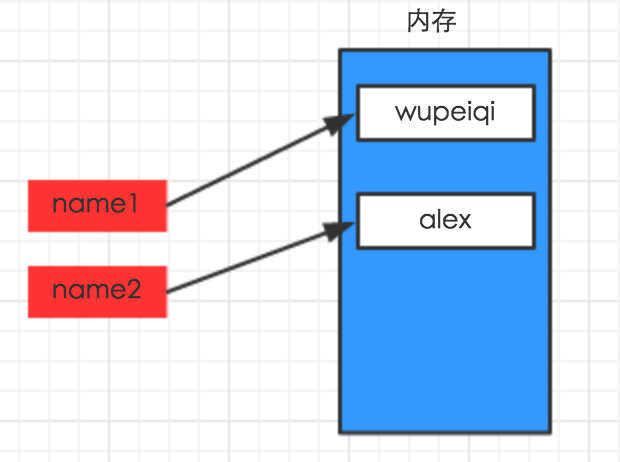
# -*- coding: utf-8 -*- name = "wupeiqi"
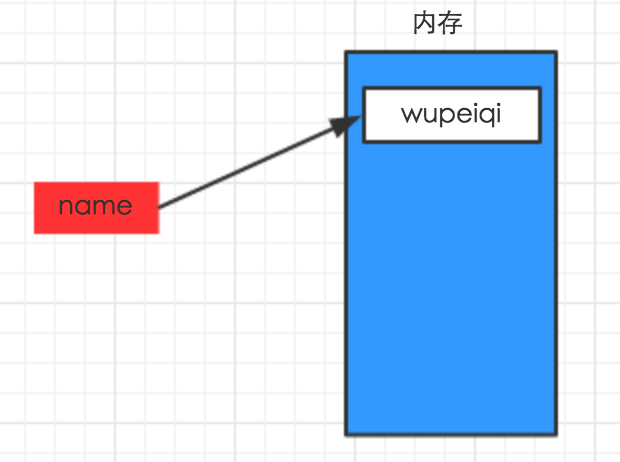
上述代码声明了一个变量,变量名为: name,变量name的值为:"wupeiqi"
变量的作用:昵称,其代指内存里某个地址中保存的内容
2、变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class',
'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally',
'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not',
'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with',
'yield']# 通过Import keyword查看 import keyword
print(keyword.kwlist)
变量的赋值
#!/usr/bin/env python
# -*- coding: utf-8 -*- name1 = "wupeiqi"
name2 = "alex"
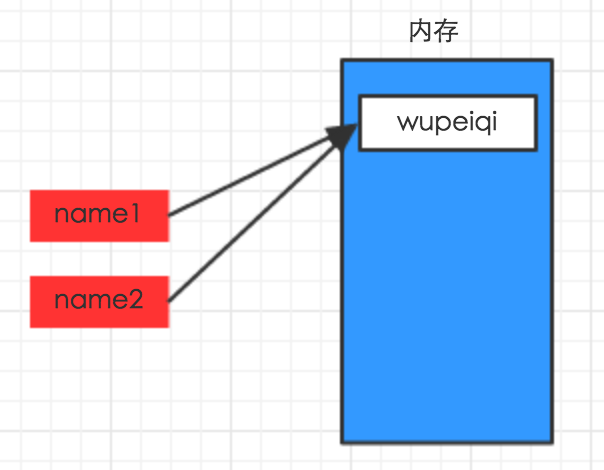
#!/usr/bin/env python
# -*- coding: utf-8 -*- name1 = "wupeiqi"
name2 = name1
3、变量最佳命名方式:
- 使用下划线'_'作为连接,如 name_variables
- 使用大小写,称为驼峰法,如 NameVariables,nameVariables
注意:两种命名方式不要混用,只要你喜欢的一种即可
4、变量命名惯例:
- 以单一下划线开头的变量名(_x)不会被from module import * 语句导入
- 以两个下划线开头但结尾没有下划线的变量名(__x)是类的本地变量
- 前后有双下划线的变量名(__x__)是系统定义的变量名,对python解释器有特殊意义
- 交互式模式下,变量名"_"用于保存最后表达式的结果
Python输入:
1、Python3.x提供了一个input(),可以让用户输入字符串。比如输入用户的名字:
python3中格式化输出默认接收的都视为字符串,如果你获取的是要数字类型则需要另外强制转换为int()转换为数字类型才能获得数字
>>> name = input("please input your name:")
please input your name:tomcatxiao
>>> print("Hello " + name)
Hello tomcatxiao
>>> age = input("please enter your age:")
please enter your age:21
>>> type(age)
<class 'str'>
>>> age1 = input("please enter your age:")
>>> age1 = int(age1)
>>> type(age1)
<class 'int'>
输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法,即:
#!/usr/bin/env python
# -*- coding: utf-8 -*- import getpass # 将用户输入的内容赋值给 pwd 变量
pwd = getpass.getpass("请输入密码:") # 打印输入的内容
print (pwd)
注意:在pycharm IDE工具中这段代码是行不通的,在Linux命令行或者Windows cmd中是可以的
2、Python2.x提供了一个raw_input()和input(),input()在python2中基本不用忘了吧,当然我这里会演示他们的区别
raw_input()在字符串和数值型都没有问题
>>> name = raw_input("please enter your name:")
please enter your name:tomcatxiao
>>> print name
tomcatxiao
>>> age = raw_input("your age is:")
your age is:21
>>> print age
21
input()在输入字符串的时候报错,变量未定义,数值型则没有报错,如果是字符串则需要引号'' or "",或者事先定义变量赋值
>>> name = input("please input your name:")
please input your name:tomcatxiao
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1, in <module>
NameError: name 'tomcatxiao' is not defined
>>> age = input("your age is:")
your age is:21
对于上面的代码进行修改下,将字符串事先赋值给一个变量,然后从input中输入则没有报错
>>> myname = "tomcatxiao"
>>> name = input("please input your name:")
please input your name:myname >>> print name
tomcatxiao
Python输出:
Python中输出是用print,Python2.x中print是语句,Python3.x中则是print()函数
注意:python3中格式化输出默认接收的都视为字符串,如果是数字则需要另外强制转换为int()转换为数字类型
十、If 流程控制和缩进
python的比较操作:
所有的Python对象都支持比较操作:
- 可用于测试值相等、相对大小等
- 如果是复合对象,python会检查其所有部分,包括自动遍历各级嵌套对象,知道可以得出最终结果
测试操作符:
- "==" 操作符测试值的相等性
- "is" 表达式测试对象的一致性
- "in" 成员关系测试
如何实现比较操作:
python中不同类型的比较方法:
- (1)数字:通过相对大小进行比较
- (2)字符串:按照字典次序逐次进行比较
- (3)列表和元组:自左至右比较各部分内容
- (4)字典:对排序之后的(键、值)列表进行比较
python中真和假的含义:
- (1)非0数字为真,否则为假
- (2)非空对象为真,否则为假
- (3)None则始终为假
比较和相等测试会递归地应用于数据结构中
返回值为True或False
组合条件测试:
- X and Y: 与运算
- X or Y: 或运算
- not X : 非运算
if测试的语法结构:
if boolean_expression1:
suite1
elif boolean_expression2:
suite2
else:
else_suite
注意:
elif语句是可选的
仅用与占位,而后在填充相关语句时,可以使用pass
if/else三元表达式:
通常在为某变量设定默认值时通常用到如下表达式
A = X if Y else Z 或 if Y:
A = X
else
A = Z
其通用条件表达式语法格式为:
expression1 if boolean_express else expression2
如果boolean_express的值为True,则条件表达式的结果为express1,否则为express2
十一、循环for,while
循环机制及应用场景
while循环:
- (1)用于编写通用迭代结构
- (2)顶端测试为真即会执行循环体,并会重复多次测试知道为假后执行循环后的其他语句
for循环:
- (1)一个通用的序列迭代器,用于遍历任何有序的序列对象内的元素
- (2)可用于字符串、元组、列表和其他的内置可迭代对象,以及通过类所创建的新对象
python也提供了一些能够进行隐性迭代的工具:
- (1)in成员关系测试
- (2)列表解析
- (3)map、reduce和filter函数
break: 跳出最内层的循环
continue: 跳出所处的最近层循环的开始处
pass: 占位语句
while循环:
1、基本循环
while True: 死循环
语法格式:
while boolean_express:
while_suite
else:
else_suite
注意:
- else分支为可选部分
- 只要boolean_express的结果为True,循环就会执行
- boolean_express的结果为False时终止循环,此时如果有else分支,则会执行
示例:
url = 'www.baidu.com'
while url:
print(url)
url = url[:-1]
#======================
x = 0;
y = 100
while x < y:
print(x)
x += 1
#======================
url = 'www.baidu.com'
while url:
print(url)
url = url[:-1]
else:
print('game over')
2、break
break用于退出所有循环
while True:
print ("123")
break
print ("456")
3、continue
continue用于退出本次循环,继续下一次循环
while True:
print ("123")
continue
print ("456“)
while大量练习:
# 练习1:逐一显示指定列表中的所有元素
# 方法1:
l1 = list(range(1,6))
while l1:
print(l1[0])
l1.pop(0) # 方法2:
l1 = list(range(1,6))
while l1:
print(l1[-1])
l1.pop() ## 方法3:
l1 = list(range(1,6))
print(l1)
i = 0
while i < len(l1):
print('index:', i, 'num:', l1[i])
i += 1 # 练习2:求100以内所有偶数之和
sum = 0
n = 1
while n <= 100:
if n % 2 == 0:
sum = sum + n
n = n + 1 print('100以内所有偶数之和:',sum) # 练习3:逐一显示指定字典的所有键;并于显示结束后说明总键数;
d1 = {'x':11, 'y':22, 'z':33}
k1 = d1.keys()
while k1:
print(k1[0])
k1.pop[0]
else:
print(len(d1)) # 练习4:创建一个包含了100以内所有奇数的列表
l1 = []
x = 1
while x < 100:
l1.append(x)
x += 2
else:
print(l1) # 练习5:逆序逐一显示一个列表的所有元素
l1 = list(range(1,6))
while l1:
print(l1[-1])
l1.pop(-1) # 练习6:
# 列表l1 = [0,1,2,3,4,5,6]
# 列表l2 = ['Sun','Mon','Tue','Wed','Thu','Fri','Sat']
# 以第一个列表中的元素为键,以第二个列表中的元素为值生成字典d1 l1 = [0,1,2,3,4,5,6]
l2 = ['Sun','Mon','Tue','Wed','Thu','Fri','Sat']
d1 = {}
i = 0
while i < len(l1):
if len(l1) == len(l2):
d1[l1[i]] = l2[i]
i += 1
else:
print(d1)
for循环:
语法格式:
for expression1 in iterable:
for_suite
else:
else_suite
通常,expression或是一个单独的变量,或是一个变量序列,一般以元组的形式给出
如果以元组或列表用于expression,则其中的每个数据项都会拆分到表达式的项
T = [(1,2),(3,4),(5,6),(7,8)]
for (a,b) in T:
print(a,b) 结果:
1 2
3 4
5 6
7 8
编写循环的技巧:
(1)for循环比while循环执行速度快
(2)python提供了两个内置函数,用于在for循环中定制特殊的循环python3.x 只有range,python2.x有(range,xrange)
- range: 一次性地返回连续的整数列表
- xrange: 一次产生一个数据元素,相较于range更节约空间
- zip:返回并行的元素元组的列表,常用于在for循环中遍历数个序列
range()函数:非完备遍历
用于每隔一定的个数元素挑选一个元素
>>> s = "How are you these day?"
>>> range(0, len(s), 2)
range(0, 22, 2)
>>> for i in range(0, len(s), 2):
print(s[i])
结果:
H
w
a
e
y
u
t
e
e
d
y
修改列表
>>> L = [1,2,3,4,5]
>>> for i in range(len(L)):
... L[i] += 1
...
>>> L
[2, 3, 4, 5, 6]
zip()函数:并行遍历
取得一个或多个序列为参数,将给定序列中的并排的元素配成元组,返回这些元组的列表
当参数长度不同时,zip会以最短序列的长度为准
1.可在for循环中用于实现并行迭代
>>> L1 = [1,2,3,4,5,6,7]
>>> L2 = ['a','b','c','d','e','e','f','g']
>>> zip(L1,L2))
<zip object at 0x0000021FA418B088>
>>> for i in (zip(L1,L2)):
... print(i)
...
(1, 'a')
(2, 'b')
(3, 'c')
(4, 'd')
(5, 'e')
(6, 'e')
(7, 'f')
2. zip也常用于动态构造字典
>>> keys = [1,2,3,4,5,6,7]
>>> values = ['Sun','Mon','Tue','Wed','Thu','Fri','Sat']
>>> for k,v in zip(keys,values):
... D[k] = v
...
>>> D
{1: 'Sun', 2: 'Mon', 3: 'Tue', 4: 'Wed', 5: 'Thu', 6: 'Fri', 7: 'Sat'}
for大量练习:
for循环练习:
练习1:逐一分开显示指定字典d1中的所有元素,类似如下;
k1 v1
k2 v2 d1 = {'x':123,'y':321,'z':734}
for k, v in d1.items():
print(k ,v) 结果:
x 123
y 321
z 734 练习2:逐一显示列表中L1=['Sun','Mon','Tue','Wed','Thu','Fri','Sat']中索引为奇数的元素; L1=['Sun','Mon','Tue','Wed','Thu','Fri','Sat']
L2 =['Sun','Mon','Tue','Wed','Thu','Fri','Sat']
for i in range(1, len(L1), 2):
print(L1[i]) 结果:
Mon
Wed
Fri 练习3:将属于列表L1=['Sun','Mon','Tue','Wed','Thu','Fri','Sat'],但不属于列表L2=['Sun','Mon','Tue','Thu','Sat']的所有元素定义为一个新列表l3; L1=['Sun','Mon','Tue','Wed','Thu','Fri','Sat']
L2=['Sun','Mon','Tue','Thu','Sat']
L3=[]
for i in L1:
if i not in L2:
L3.append(i)
else:
print(L3) 结果:
['Wed', 'Fri'] 练习4:
将属于列表namelist=['stu1','stu2','stu3','stu4','stu5','stu6','stu7'],
删除列表removelist=['stu3','stu7','stu9'];请将属于removelist列表中的每个元素从namelist中移除(属于removelist,但不属于namelist的忽略即可) namelist=['stu1','stu2','stu3','stu4','stu5','stu6','stu7']
removelist=['stu3','stu7','stu9']
for i in removelist:
if i in namelist:
namelist.remove(i)
print(namelist) 结果:
['stu1', 'stu2', 'stu4', 'stu5', 'stu6']
场景一、用户登陆验证
#!/usr/bin/env python3
# -*- coding: utf-8 -*- import getpass name = 'tom'
pwd = 123456
count = 0 while True:
if count < 3:
print("please enter your name and password !")
username = input("username: ")
password = getpass.getpass("password: ") if username == name and password == pwd:
print("恭喜你登录成功")
break
else:
print("登录失败!用户名或者密码错误")
count += 1
else:
print("你已经错误3次,正在退出")
break
场景二、根据用户输入内容输出其权限
#!/usr/bin/env python3
# -*- coding: utf-8 -*- # 根据用户输入内容打印其权限
# alex --> 超级管理员
# eric --> 普通管理员
# tony,rain --> 业务主管
# 其他 --> 普通用户 tag = True
while tag:
name = input('请输入用户名:')
if name == 'q' or name == 'Q':
tag = False
else:
if name == 'alex':
print("超级管理员")
elif name == 'eric':
print("普通管理员")
elif name == 'tony' or name == 'rain':
print("业务主管")
else:
print("普通用户")
场景三、猜年龄游戏
#!/usr/bin/env python3
# -*- coding: utf-8 -*- age = 22
count = 0 for i in range(10):
if count < 3:
num = int(input("please input age: "))
if num == age:
print("恭喜你,答对了")
break
elif num > age:
print("你猜的数字太大了")
else:
print("你猜的数字太小了")
else:
ss = input("你太笨了,这都猜不对,还继续玩吗?[yes | not]: ")
if ss == 'yes' or ss == 'YES':
count = 0
continue
else:
print("Bye, 下次再玩")
break count += 1
Python运维开发:初识Python(一)的更多相关文章
- python运维开发(十一)----python操作缓存memcache、redis
内容目录: 缓存 memcache redis memcache Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数 ...
- Python运维开发基础03-语法基础 【转】
上节作业回顾(讲解+温习60分钟) #!/usr/bin/env python3 # -*- coding:utf-8 -*- # author:Mr.chen #只用变量和字符串+循环实现“用户登陆 ...
- Python运维开发基础01-语法基础【转】
开篇导语 整个Python运维开发教学采用的是最新的3.5.2版,当遇到2.x和3.x版本的不同点时,会采取演示的方式,让同学们了解. 教学预计分为四大部分,Python开发基础,Python开发进阶 ...
- Python运维开发基础01-语法基础
标签(空格分隔): Mr.chen之Python3.0执教笔记(QQ:215379068) --仅供北大青鸟内部学习交流使用 开发不是看出来的,开发一定是练出来的: 想学好开发,没有捷径可走,只有不断 ...
- Python运维开发基础10-函数基础【转】
一,函数的非固定参数 1.1 默认参数 在定义形参的时候,提前给形参赋一个固定的值. #代码演示: def test(x,y=2): #形参里有一个默认参数 print (x) print (y) t ...
- Python运维开发基础09-函数基础【转】
上节作业回顾 #!/usr/bin/env python3 # -*- coding:utf-8 -*- # author:Mr.chen # 实现简单的shell命令sed的替换功能 import ...
- Python运维开发基础08-文件基础【转】
一,文件的其他打开模式 "+"表示可以同时读写某个文件: r+,可读写文件(可读:可写:可追加) w+,写读(不常用) a+,同a(不常用 "U"表示在读取时, ...
- Python运维开发基础07-文件基础【转】
一,文件的基础操作 对文件操作的流程 [x] :打开文件,得到文件句柄并赋值给一个变量 [x] :通过句柄对文件进行操作 [x] :关闭文件 创建初始操作模板文件 [root@localhost sc ...
- Python运维开发基础06-语法基础【转】
上节作业回顾 (讲解+温习120分钟) #!/usr/bin/env python3 # -*- coding:utf-8 -*- # author:Mr.chen # 添加商家入口和用户入口并实现物 ...
- Python运维开发基础05-语法基础【转】
上节作业回顾(讲解+温习90分钟) #!/usr/bin/env python # -*- coding:utf-8 -*- # author:Mr.chen import os,time Tag = ...
随机推荐
- 网管到CEO的10年逆袭之路
把我个人近一年来讲的技术人员如何成长的鸡汤课整理了出来,送给大家<网管到CEO的10年逆袭之路>
- GNU 下命令objcopy 用法
概念: 将目标文件的一部分或者全部内容拷贝到另外一个目标文件中,或者实现目标文件的格式转换. 常用转换: 1 把elf格式转成s19格式: objcopy --srec-len --srec-forc ...
- hbase之InitMetaProcedure流程
hbase中相关命令行操作在服务端都是由相应的Procedure来执行完成的,并不是一个单独的操作,而是由其状态机中的一系列状态按照流程来完成的.特别的,我这次本着有图有真相的原则来为大家分析这一流程 ...
- [EXP]Microsoft Windows 10 (Build 17134) - Local Privilege Escalation (UAC Bypass)
#include "stdafx.h" #include <Windows.h> #include "resource.h" void DropRe ...
- js动态创建表单数据
var formData = new FormData(); formData.append("file",fileList[i]); formData.append(" ...
- update-rc.d: error: XXX Default-Start contains no runlevels, aborting.
root@hm-saas-db:/etc/init.d# update-rc.d confluence disable update-rc.d: error: confluence Default-S ...
- Django--缓存设置
Django缓存机制 一. 缓存介绍 缓存是将一些常用的数据保存内存或者memcache中,在一定的时间内有人来访问这些数据时,则不再去执行数据库及渲染等操作,而是直接从内存或memcache的缓存中 ...
- man sm-notify(sm-notify命令中文手册)
本人译作集合:http://www.cnblogs.com/f-ck-need-u/p/7048359.html sm-notify命令是用来发送重启通知信息给NFS对端的,在锁状态恢复过程中起着至关 ...
- 18.Class 的基本语法
Class 的基本语法 Class 的基本语法 简介 JavaScript 语言中,生成实例对象的传统方法是通过构造函数.下面是一个例子. function Point(x, y) { this.x ...
- 关于Android屏幕的参数
屏幕尺寸信息: 级别 对应Drawable dp尺寸 Layout 文件夹 案例 标注 small drawable-ldpi 426x320 dp layout-small 典型 (240x320 ...