sql server 索引阐述系列五 索引参数与碎片
-- 创建聚集索引
create table [dbo].[pub_stocktest] add constraint [pk_pub_stocktest] primary key clustered
(
[sid] asc
)with (pad_index = off, statistics_norecompute = off, sort_in_tempdb = off, ignore_dup_key = off,
online = off, allow_row_locks = on, allow_page_locks = on) on [primary] -- 创建非聚集索引
create nonclustered index [ix_model] on [dbo].[pub_stocktest]
(
[model] asc
)
include ( [name]) with (pad_index = off, statistics_norecompute = off, sort_in_tempdb = off, drop_existing = off,
online = off, allow_row_locks = on, allow_page_locks = on, FILLFACTOR = 85) on [primary]
1.1 Filefactor参数
使用Filefactor可以对索引的每个叶子分页存储保留一些空间。对于聚集索引,叶级别包含了数据,使用Filefactor来控制表的保留空间,通过预留的空间,避免了新的数据按顺序插入时,需腾出空位而进行分页分隔。
Filefactor设置生效注意,只有在创建索引时才会根据已经存在的数据决定预留的空间大小,如里需要可以alter index重建索引并重置原来指定的Filefactor值。
在创建索引时,如果不指定Filefactor,就采用默认值0 也就是填充满,可通过sp_configure 来配置全局实例。Filefactor也只就用于叶子级分页上。如果要在中间层控制索引分页,可以通过指定pad_index选项来实现.该选择会通知到索引上所有层次使用相同的Filefactor。Pad_index也只有索引在新建或重建时有用。
1.2 Drop_existing 参数
删除或重建一个指定的索引作为单个事务来处理。该项在重建聚集索引时格外有用,当删除一个聚集索引时,sqlserver会重建每个非聚集索引以便将书签从聚集索引键改为RID。如果再新建或者重建聚集索引,Sql server会再一次重建全部的非聚集索引,如果再新建或重建的聚集索引键值相同,可以设置Drop_existing=ON。
1.3 IGNORE_DUP_KEY
是指如果一个update或者insert语句影响多行数据,但有一行键被发现产生重值时,整个语句就会回滚,IGNORE_DUP_KEY=on时产生重复键值时不会引起整个语句的回滚,重复的行会被舍弃其它的行会被插入或更新。
1.4 Statistics_norecompute
选项决定了是否需要自动更新索引上的统计,每个索引维护着该索引首位字段的数值分布的柱状图,在查询执行计划时,查询优化器利用这些统计信息来判断一个特定索引的有效性。当数据达到一个阀值时,统计值会变。Statistics_norecompute选项允许一个关联的索引在数据修改时不自动更新统计值。该选择覆盖了auto_update_statistics的on值。
1.5 ONLINE
值默认OFF, 索引操作期间,基础表和关联的索引是否可用于查询和数据修改操作。
当值为ON时,能够继续对基础表和索引进行查询或更新,但在短时间内获取sch_m架构修改锁,必须等待此表上的所有阻塞事务完成,在操作期间,此锁会阻止所有其它事务。
当值为OFF时,可以会获取共享锁,防止更新基础表,但允许读操作。
1.6 MAXDOP
索引操作期间替代max degree of parallelism 实例配置,默认值为0, 根据当前系统工作负荷使用实际数量的处理器。
1.7 包含性列(included columns)
包含列只在叶级别中出现,不控制索引行的顺序,它作用是使叶级别包含更多信息从而覆盖索引的调优能力,覆盖索引只出现在非聚集索引中,在叶级别就可以找到满足查询的全部信息。
1.8 on [primary]
在创建索引时 create index 最后一个子句允许用户指定索引被放置在哪里。可以指定特定的文件组或预定义的分区方案。默认存放与表文件组相同一般都是主文件组中。
1.9约束和索引
当我们创建主键或者唯一性约束时,会创建一个唯一性索引,被创建出来支持约束的索引名称与约束名称相同。
约束是一个逻辑概念,而索引是一个物理概念,建立索引实际是创建一个占用存储空间并且在数据修改操作中必须得到维护的物理结构。
创建约束就索引内部结构或优化器的选择来看是没有区别的。
二 索引碎片
2.1 SHOWCONTIG
-- SQLserver 2000使用SHOWCONTIG查看索引碎片 (已过时)
dbcc SHOWCONTIG (tablename,'indexname')
例如下面查询一个PUB_StockCollect表下的IX_StockModel索引
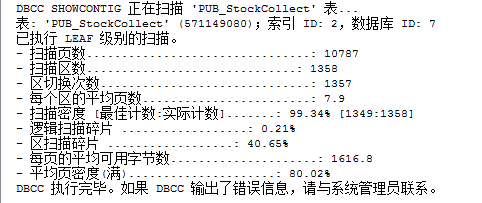
(1)Page Scanned-扫描页数:如果你知道行的近似尺寸和表或索引里的行数,那么你可以估计出索引里的页数。看看扫描页数,如果明显比你估计的页数要高,说明存在内部碎片。
(2)Extents Scanned-扫描扩展盘区数:用扫描页数除以8,四舍五入到下一个最高值。该值应该和DBCC SHOWCONTIG返回的扫描扩展盘区数一致。如果DBCC SHOWCONTIG返回的数高,说明存在外部碎片。碎片的严重程度依赖于刚才显示的值比估计值高多少。
(3)Extent Switches-扩展盘区开关数:该数应该等于扫描扩展盘区数减1。高了则说明有外部碎片。
(4)Avg. Pages per Extent-每个扩展盘区上的平均页数:该数是扫描页数除以扫描扩展盘区数,一般是8。小于8说明有外部碎片。
(5)Scan Density [Best Count:Actual Count]-扫描密度[最佳值:实际值]:DBCC SHOWCONTIG返回最有用的一个百分比。这是扩展盘区的最佳值和实际值的比率。该百分比应该尽可能靠近100%。低了则说明有外部碎片。
(6)Logical Scan Fragmentation-逻辑扫描碎片:无序页的百分比。该百分比应该在0%到10%之间,高了则说明有外部碎片。
(7)Extent Scan Fragmentation-扩展盘区扫描碎片:无序扩展盘区在扫描索引叶级页中所占的百分比。该百分比应该是0%,高了则说明有外部碎片。
(8)Avg. Bytes Free per Page-每页上的平均可用字节数:所扫描的页上的平均可用字节数。越高说明有内部碎片,不过在你用这个数字决定是否有内部碎片之前,应该考虑fill factor(填充因子)。
(9)Avg. Page Density (full)-平均页密度(完整):每页上的平均可用字节数的百分比的相反数。低的百分比说明有内部碎片。
总结:(1)逻辑扫描碎片:越低越好 (2)平均页密度:80%左右最好,低于%60重建索引,(3)最佳计数与实际计数相差较大重建索引。
sql server 索引阐述系列五 索引参数与碎片的更多相关文章
- sql server 索引阐述系列二 索引存储结构
一.概述. "流光容易把人抛,红了樱桃,绿了芭蕉“ 转眼又年中了,感叹生命的有限,知识的无限.在后续讨论索引之前,先来了解下索引和表数据的内部结构,这一节将介绍页的存储,页分配单元类型,区的 ...
- sql server 索引阐述系列一索引概述
一. 索引概述 关于介绍索引,有一种“文章太守,挥毫万字,一饮千钟”的豪迈感觉,因为索引需要讲的知识点太多.在每个关系型数据库里都会作为重点介绍,因为索引关系着数据库的整体性能, 它在数据库性能优化里 ...
- sql server 索引阐述系列七 索引填充因子与碎片
一.概述 索引填充因子作用:提供填充因子选项是为了优化索引数据存储和性能. 当创建或重新生成索引时,填充因子的值可确定每个叶级页上要填充数据的空间百分比,以便在每一页上保留一些剩余存储空间作为以后扩展 ...
- 【目录】sql server 进阶篇系列
随笔分类 - sql server 进阶篇系列 sql server 下载安装标记 摘要: SQL Server 2017 的各版本和支持的功能 https://docs.microsoft.com/ ...
- SQL Server调优系列基础篇(索引运算总结)
前言 上几篇文章我们介绍了如何查看查询计划.常用运算符的介绍.并行运算的方式,有兴趣的可以点击查看. 本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方 ...
- SQL Server调优系列玩转篇三(利用索引提示(Hint)引导语句最大优化运行)
前言 本篇继续玩转模块的内容,关于索引在SQL Server的位置无须多言,本篇将分析如何利用Hint引导语句充分利用索引进行运行,同样,还是希望扎实掌握前面一系列的内容,才进入本模块的内容分析. 闲 ...
- SQL Server 调优系列玩转篇三(利用索引提示(Hint)引导语句最大优化运行)
前言 本篇继续玩转模块的内容,关于索引在SQL Server的位置无须多言,本篇将分析如何利用Hint引导语句充分利用索引进行运行,同样,还是希望扎实掌握前面一系列的内容,才进入本模块的内容分析. 闲 ...
- SQL Server调优系列进阶篇(如何索引调优)
前言 上一篇我们分析了数据库中的统计信息的作用,我们已经了解了数据库如何通过统计信息来掌控数据库中各个表的内容分布.不清楚的童鞋可以点击参考. 作为调优系列的文章,数据库的索引肯定是不能少的了,所以本 ...
- SQL Server调优系列进阶篇(如何维护数据库索引)
前言 上一篇我们研究了如何利用索引在数据库里面调优,简要的介绍了索引的原理,更重要的分析了如何选择索引以及索引的利弊项,有兴趣的可以点击查看. 本篇延续上一篇的内容,继续分析索引这块,侧重索引项的日常 ...
随机推荐
- Windows 10 专业版 长期服务版 激活
这个用小白系统之后一段时间显示要求激活,或者更改产品秘钥.网上找了许多秘钥也是没啥用,又不想用激活工具的话,可以试试用win+R 输入cmd : 依次输入:slmgr /skms kms.digibo ...
- linux crontab 命令,最小的执行时间是一分钟,如需要在小于一分钟内重复执行
编写shell脚本实现 crontab.sh #!/bin/bash step=2 #间隔的秒数,不能大于60 for (( i = 0; i < 60; i=(i+step) )); do $ ...
- 2019.03.11 COGS2652 秘术(天文密葬法)(分数规划+长链剖分)
传送门 题意:nnn个点的树,每个点两个值a,ba,ba,b,问长度为mmm的路径∑ai∑bi\frac{\sum a_i}{\sum b_i}∑bi∑ai的最大值. 思路:一眼要01分数规划, ...
- MySQL-查询结果缓存
1.缓存必备: SQL文相同,数库表字段构.记录不变,大小写不敏感,字符集敏感 2.提缓存: 缓存配高.分区 3.多个应用多配置 4.SELECT SQL_NO_CACHE/SQL_CACHE my. ...
- sjms-4 行为型模式
行为型模式 责任链模式 内容:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系.将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止.角色:抽象处理者(Hand ...
- 1003 Emergency Dijkstra
这题做的心很累,我用的还是 1018的思路做的,但是 使用dfs 求最大人数对于某些有问题(现在也不知道错哪了), 看了别人的代码后才发现,其实完全不用这么麻烦,只需设置一个点的权重,一遍DJ(自创简 ...
- 为创世纪图书馆(Library Genesis)作镜像
简介 Library Genesis的Wikipedia条目中的介绍是: Library Genesis or LibGen is a search engine for articles and b ...
- windows mysql zip 安装
https://www.cnblogs.com/iathanasy/p/8461429.html
- (二)Javascript面向对象编程:构造函数的继承
Javascript面向对象编程:构造函数的继承 这个系列的第一部分,主要介绍了如何"封装"数据和方法,以及如何从原型对象生成实例. 今天要介绍的是,对象之间的"继承 ...
- Exp2 后门原理与实践-------20164325王晓蕊
Exp2 后门原理与实践 任务一:使用netcat获取主机操作Shell,cron启动 1.windows获取linux shell 1.1 ipconfig 查看本机查看以太网适配器(8)的ipv ...