Python os.walk文件遍历用法【转】
python中os.walk是一个简单易用的文件、目录遍历器,可以帮助我们高效的处理文件、目录方面的事情。
1.载入
要使用os.walk,首先要载入该函数
可以使用以下两种方法
- import os
- from os import walk
2.使用
os.walk的函数声明为:
walk(top, topdown=True, onerror=None, followlinks=False)
参数
- top 是你所要便利的目录的地址
- topdown 为真,则优先遍历top目录,否则优先遍历top的子目录(默认为开启)
- onerror 需要一个 callable 对象,当walk需要异常时,会调用
- followlinks 如果为真,则会遍历目录下的快捷方式(linux 下是 symbolic link)实际所指的目录(默认关闭)
os.walk 的返回值是一个生成器(generator),也就是说我们需要不断的遍历它,来获得所有的内容。
每次遍历的对象都是返回的是一个三元组(root,dirs,files)
- root 所指的是当前正在遍历的这个文件夹的本身的地址
- dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
- files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
如果topdown 参数为真,walk 会遍历top文件夹,与top文件夹中每一个子目录。
举个例子
如果我们有如下的文件结构:
a -> b -> 1.txt, 2.txt
c -> 3.txt
d ->
4.txt
5.txt for (root, dirs, files) in os.walk('a'):
#第一次运行时,当前遍历目录为 a
所以 root == 'a'
dirs == [ 'b', 'c', 'd']
files == [ '4.txt', '5.txt'] 。。。 # 接着遍历 dirs 中的每一个目录
b: root = 'a\\b'
dirs = []
files = [ '1.txt', '2.txt'] # dirs为空,返回
# 遍历c
c: root = 'a\\c'
dirs = []
files = [ '3.txt' ] PS : 如果想获取文件的全路径,只需要
for f in files:
path = os.path.join(root,f) # 遍历d
d: root = 'a\\b'
dirs = []
files = [] 遍历完毕,退出循环
3.简单的例子
保持目录 a 的目录结构,在 b 中创建对应的文件夹,并把a中所有的文件加上后缀 _bak
import os Root = 'a'
Dest = 'b' for (root, dirs, files) in os.walk(Root):
new_root = root.replace(Root, Dest, 1)
if not os.path.exists(new_root):
os.mkdir(new_root) for d in dirs:
d = os.path.join(new_root, d)
if not os.path.exists(d):
os.mkdir(d) for f in files:
# 把文件名分解为 文件名.扩展名
# 在这里可以添加一个 filter,过滤掉不想复制的文件类型,或者文件名
(shotname, extension) = os.path.splitext(f)
# 原文件的路径
old_path = os.path.join(root, f)
new_name = shotname + '_bak' + extension
# 新文件的路径
new_path = os.path.join(new_root, new_name)
try:
# 复制文件
open(new_path, 'wb').write(open(old_path, 'rb').read())
except IOError as e:
print(e)
转自
作者:MikuLovely
链接:https://www.jianshu.com/p/bbad16822eab
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
#!/usr/bin/python
#coding=utf-8
import os
def dirlist(path):
for root,dirs,files in os.walk(path): #将os.walk在元素中提取的值,分别放到root(根目录),dirs(目录名),files(文件名)中。
for file in files:
print os.path.join(root,file) #根目录与文件名组合,形成绝对路径。
if __name__=='__main__':
path = '/test'
dirlist(path)
执行结果:
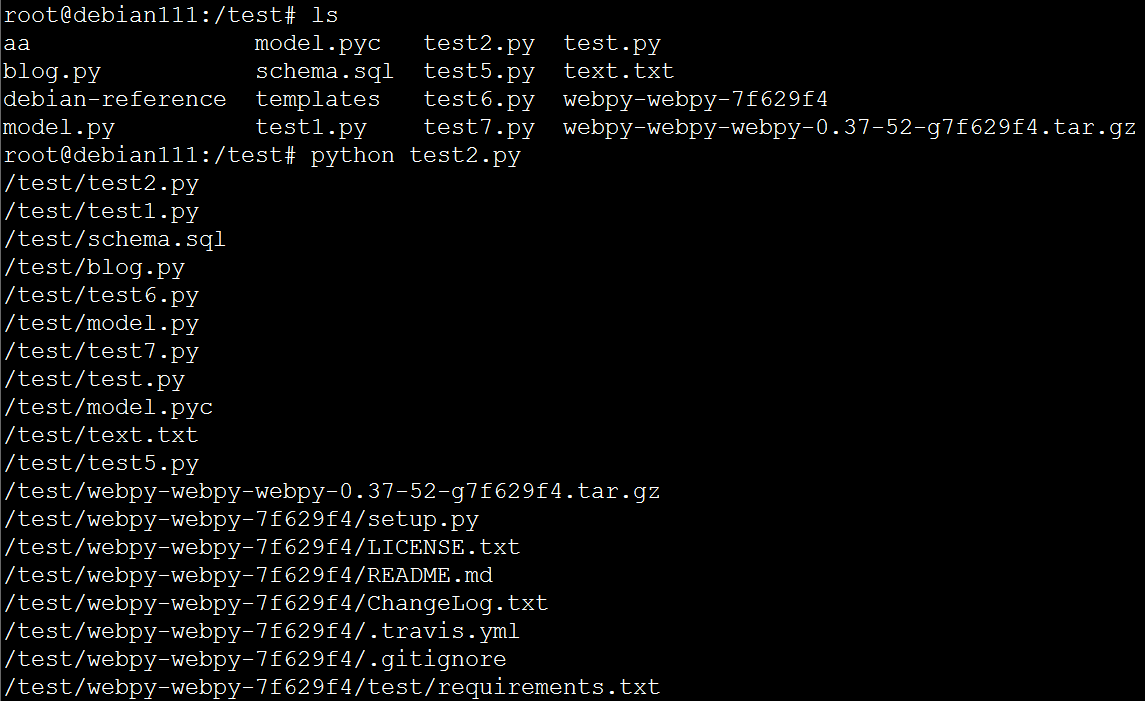
知识点:
代码中的root为str类型,dirs为list类型,files为list类型
当root为/test时,dirs列表中是/test下的目录,files列表是/test下的文件
当root为/test/aa时,dirs列表则为/test/aa下的目录,fiels列表是/test/aa下的文件
心得:
#!/usr/bin/python
import os,os.path
def visit(arg,dirname,names):
for filespath in names:
print os.path.join(dirname,filespath)
if __name__=='__main__':
path = '/test'
os.path.walk(path,visit,())
关于os.path.walk不清楚,暂且标记。
转自
自学python之——os.walk 查找目录下的文件 - CSDN博客 https://blog.csdn.net/happylife_haha/article/details/44566975
#!/usr/bin/python
# -*- coding: gbk -*- # os.walk()的使用
import os # 枚举dirPath目录下的所有文件 def main():
#begin
fileDir = "F:" + os.sep + "kams" # 查找F:\aaa 目录下
for root, dirs, files in os.walk(fileDir):
#begin
for dir in dirs:
#begin
print(os.path.join(root, dir))
#end
for file in files:
#begin
print(os.path.join(root, file))
#end
#end
os.system("pause")
#end if __name__ == '__main__':
#begin
main()
#end
执行结果
目录:
F:\kams\.svn
F:\kams\war119
F:\kams\war120
文件:
F:\kams\.svn\pristine
F:\kams\.svn\tmp
F:\kams\.svn\entries
F:\kams\.svn\format
F:\kams\.svn\wc.db
F:\kams\.svn\wc.db-journal
F:\kams\.svn\pristine\12
F:\kams\.svn\pristine\96
F:\kams\.svn\pristine\9a
F:\kams\.svn\pristine\12\12b99bf8ef5342805dab3cb5da02650ea50d7994.svn-base
F:\kams\.svn\pristine\96\96c5938bf3f1c89e3da195fc7839744a8b01822a.svn-base
F:\kams\.svn\pristine\9a\9a71415db2b420aa1d6eae9166b5128aaab4c402.svn-base
F:\kams\war119\czx.py
F:\kams\war119\zabbix_server_modify.sh
F:\kams\war120\czx.py
F:\kams\war120\test.py
F:\kams\war120\zabbix_server_modify.sh
转自
Python os.walk文件遍历 - 星星故乡 - 博客园 https://www.cnblogs.com/lincj/p/5617605.html
python 简单示例说明os.walk和os.path.walk的不同
import os,os.path
def func(arg,dirname,names):
for filespath in names:
print os.path.join(dirname,filespath) if __name__=="__main__":
print "==========os.walk================"
index = 1
for root,subdirs,files in os.walk("c:\\test"):
print "第",index,"层"
index += 1
for filepath in files:
print os.path.join(root,filepath)
for sub in subdirs:
print os.path.join(root,sub)
print "==========os.path.walk================"
os.path.walk("c:\\test",func,())
结果如下:

总结:
(1)两者都能实现达到同一个效果
(2)在python3中,os.path.walk要被os.walk取代了,大家尽量用os.walk
(3)os.walk明显比os.path.walk要简洁一些,起码它不需要回调函数,遍历的时候一目了然:root,subdirs,files
(4)可能你在烦恼,os.path.walk的第三个参数arg有什么用,好吧,当你os.path.walk()赋值给arg的时候,你就可以在第二个参数对应的func中用arg了
转自
python 简单示例说明os.walk和os.path.walk的不同 - CSDN博客 https://blog.csdn.net/emaste_r/article/details/12442675
Python os.walk文件遍历用法【转】的更多相关文章
- Python os.walk文件遍历
os.walk(top, topdown=True, onerror=None, followlinks=False) 可以得到一个三元tupple(dirpath, dirnames, filena ...
- Python os.walk() 方法遍历文件目录
概述 os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下. os.walk() 方法是一个简单易用的文件.目录遍历器,可以帮助我们高效的处理文件.目录方面的事情. 在Un ...
- python os.walk()方法--遍历当前目录的方法
前记:有个奇妙的想法并想使用代码实现,发现了一个坑,百度了好久也没发现的"填坑"的文章~~~~~~~~~ 那就由我来填 os.walk()支持相对路径 例如 os.walk(&qu ...
- Python os.walk() 遍历出当前目录下的文件夹和文件
os.walk目录遍历 os.walk的参数如下: os.walk(top, topdown=True, onerror=None, followlinks=False) 其中: - top是要遍历的 ...
- python os&shutil 文件操作
python os&shutil 文件操作 # os 模块 os.sep 可以取代操作系统特定的路径分隔符.windows下为 '\\' os.name 字符串指示你正在使用的平台.比如对于W ...
- Python os.walk() 简介
Table of Contents 1. os.walk目录遍历 1.1. os.walk 1.2. 例子 1.2.1. 测试topdown 1.2.2. 运行时修改遍历目录 2. 参考资料 os.w ...
- python os.walk()遍历文件夹
转自 http://alanland.iteye.com/blog/612459 via @alanland 今天第一次进行 文件遍历,自己递归写的时候还调试了好久,(主要因为分隔符号的问题),后来发 ...
- python os.walk()遍历
os.walk()遍历 import os p='/bin' #设定一个路径 for i in os.walk(p): #返回一个元组 print (i) # i[0]是路径 i[1]是文件夹 i[2 ...
- Python os.walk的用法与举例
os.walk(top, topdown=True, onerror=None, followlinks=False) 可以得到一个三元tupple(dirpath, dirnames, filena ...
随机推荐
- MyBatis-Plugins
MyBatis 允许在已映射语句执行过程中的某一点进行拦截调用.默认情况下,MyBatis 允许使用插件来拦截的方法调用包括: Executor (update, query, flushStatem ...
- Sublime Text3 里使用MarkDown如何预览
安装需要的包: 1.markdown editing 2.markdown preview 具体的步骤是: 1.按住ctrl + shift + p 来调出一个弹出的输入框 :2.输入package ...
- Linux记录-JMX监控JAVA进程
3.修改xxx.sh 加入export JAVA_OPTS="-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.mana ...
- js中数值类型相加变成拼接字符串的问题
如题,弱类型计算需要先进行转型,例: savNum=parseInt(savNum)+parseInt(num);或者使用 number()转型
- freemarker迭代list、map等常规操作,将数据放到模板中
转自:https://blog.csdn.net/wickedvalley/article/details/65937189 一.controller开始准备模型.数据1.po类 package co ...
- python --端点调试
python端点调试 左边三角:快速跳到下一个端点 下箭头:单不调试 斜向下箭头:跳到函数内部执行代码
- 使用idea创建springboot项目并打成war包发布到tomcat8上
1.将pom.xml中的打包方式修改为war <groupId>com.borya</groupId> <artifactId>Project</artifa ...
- 配置tomcat限制指定IP地址访问后端应用
1. 场景后端存在N个tomcat实例,前端通过nginx反向代理和负载均衡. tomcat1 tomcatN | | | ...
- SpringBoot系列: 理解 Spring 的依赖注入(一)
==============================Spring 的依赖注入==============================对于 Spring 程序, Spring 框架为我们提供 ...
- windows修改自定义格式,有的程序写的不严谨的话会造成出错,就需要重置时间格式